 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Dialogue System with AUDITED
Oct 22, 2021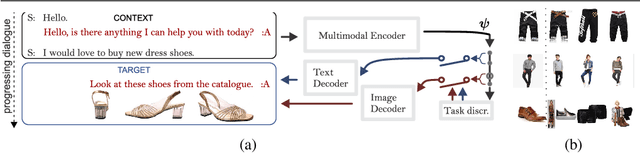

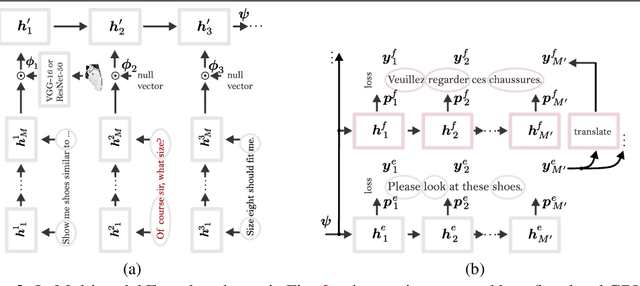
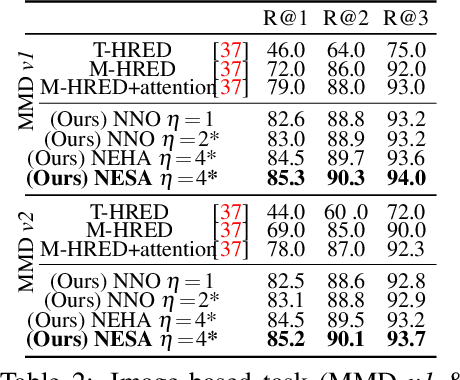
We devise a multimodal conversation system for dialogue utterances composed of text, image or both modalities. We leverage Auxiliary UnsuperviseD vIsual and TExtual Data (AUDITED). To improve the performance of text-based task, we utilize translations of target sentences from English to French to form the assisted supervision. For the image-based task, we employ the DeepFashion dataset in which we seek nearest neighbor images of positive and negative target images of the MMD data. These nearest neighbors form the nearest neighbor embedding providing an external context for target images. We form two methods to create neighbor embedding vectors, namely Neighbor Embedding by Hard Assignment (NEHA) and Neighbor Embedding by Soft Assignment (NESA) which generate context subspaces per target image. Subsequently, these subspaces are learnt by our pipeline as a context for the target data. We also propose a discriminator which switches between the image- and text-based tasks. We show improvements over baselines on the large-scale Multimodal Dialogue Dataset (MMD) and SIMMC.
Artwork Identification from Wearable Camera Images for Enhancing Experience of Museum Audiences
Jun 24, 2018



Recommendation systems based on image recognition could prove a vital tool in enhancing the experience of museum audiences. However, for practical systems utilizing wearable cameras, a number of challenges exist which affect the quality of image recognition. In this pilot study, we focus on recognition of museum collections by using a wearable camera in three different museum spaces. We discuss the application of wearable cameras, and the practical and technical challenges in devising a robust system that can recognize artworks viewed by the visitors to create a detailed record of their visit. Specifically, to illustrate the impact of different kinds of museum spaces on image recognition, we collect three training datasets of museum exhibits containing variety of paintings, clocks, and sculptures. Subsequently, we equip selected visitors with wearable cameras to capture artworks viewed by them as they stroll along exhibitions. We use Convolutional Neural Networks (CNN) which are pre-trained on the ImageNet dataset and fine-tuned on each of the training sets for the purpose of artwork identification. In the testing stage, we use CNNs to identify artworks captured by the visitors with a wearable camera. We analyze the accuracy of their recognition and provide an insight into the applicability of such a system to further engage audiences with museum exhibitions.
CNN-based Action Recognition and Supervised Domain Adaptation on 3D Body Skeletons via Kernel Feature Maps
Jun 24, 2018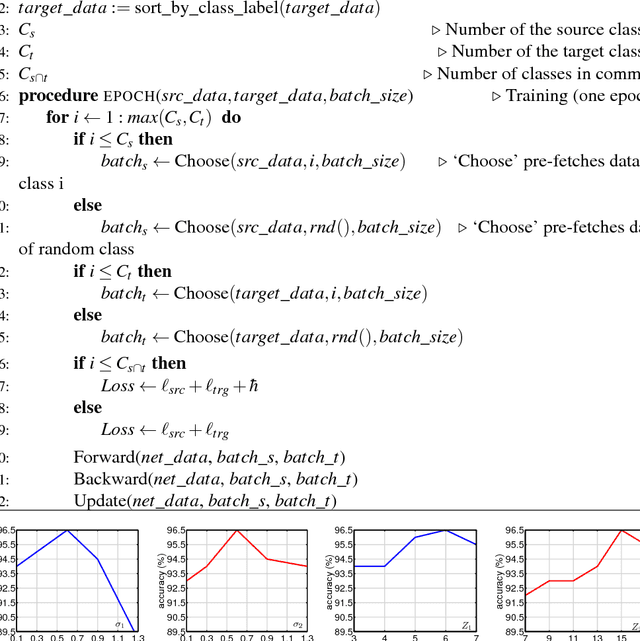
Deep learning is ubiquitous across many areas areas of computer vision. It often requires large scale datasets for training before being fine-tuned on small-to-medium scale problems. Activity, or, in other words, action recognition, is one of many application areas of deep learning. While there exist many Convolutional Neural Network architectures that work with the RGB and optical flow frames, training on the time sequences of 3D body skeleton joints is often performed via recurrent networks such as LSTM. In this paper, we propose a new representation which encodes sequences of 3D body skeleton joints in texture-like representations derived from mathematically rigorous kernel methods. Such a representation becomes the first layer in a standard CNN network e.g., ResNet-50, which is then used in the supervised domain adaptation pipeline to transfer information from the source to target dataset. This lets us leverage the available Kinect-based data beyond training on a single dataset and outperform simple fine-tuning on any two datasets combined in a naive manner. More specifically, in this paper we utilize the overlapping classes between datasets. We associate datapoints of the same class via so-called commonality, known from the supervised domain adaptation. We demonstrate state-of-the-art results on three publicly available benchmarks.
Museum Exhibit Identification Challenge for Domain Adaptation and Beyond
Feb 04, 2018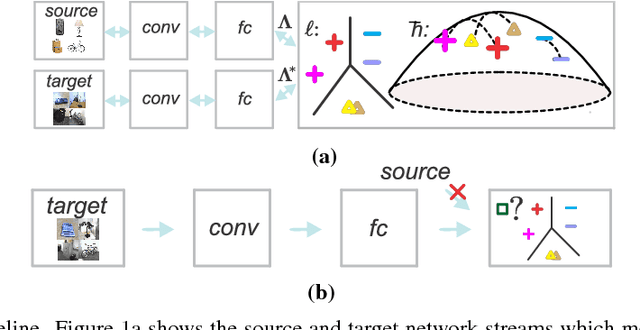
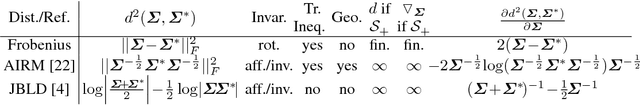

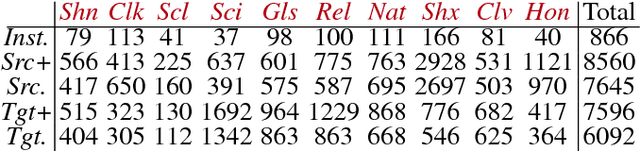
In this paper, we approach an open problem of artwork identification and propose a new dataset dubbed Open Museum Identification Challenge (Open MIC). It contains photos of exhibits captured in 10 distinct exhibition spaces of several museums which showcase paintings, timepieces, sculptures, glassware, relics, science exhibits, natural history pieces, ceramics, pottery, tools and indigenous crafts. The goal of Open MIC is to stimulate research in domain adaptation, egocentric recognition and few-shot learning by providing a testbed complementary to the famous Office dataset which reaches 90% accuracy. To form our dataset, we captured a number of images per art piece with a mobile phone and wearable cameras to form the source and target data splits, respectively. To achieve robust baselines, we build on a recent approach that aligns per-class scatter matrices of the source and target CNN streams [15]. Moreover, we exploit the positive definite nature of such representations by using end-to-end Bregman divergences and the Riemannian metric. We present baselines such as training/evaluation per exhibition and training/evaluation on the combined set covering 866 exhibit identities. As each exhibition poses distinct challenges e.g., quality of lighting, motion blur, occlusions, clutter, viewpoint and scale variations, rotations, glares, transparency, non-planarity, clipping, we break down results w.r.t. these factors.
Domain Adaptation by Mixture of Alignments of Second- or Higher-Order Scatter Tensors
Apr 11, 2017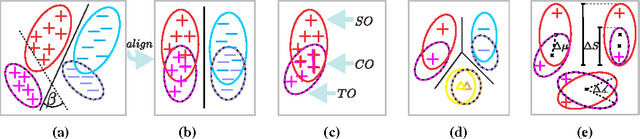
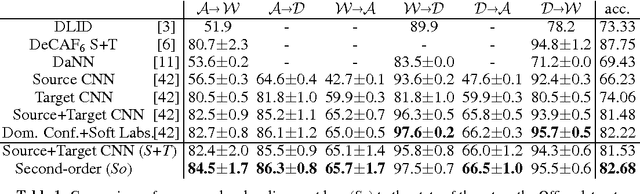
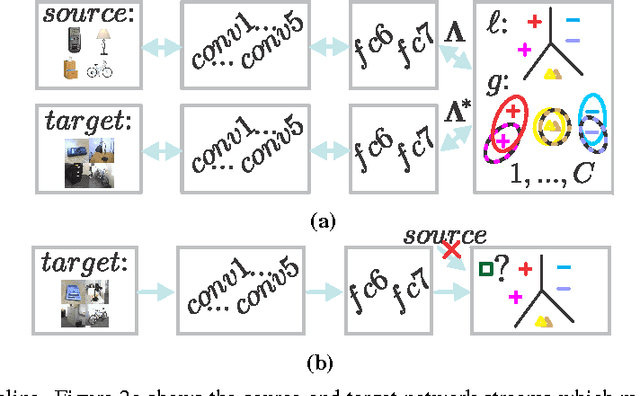
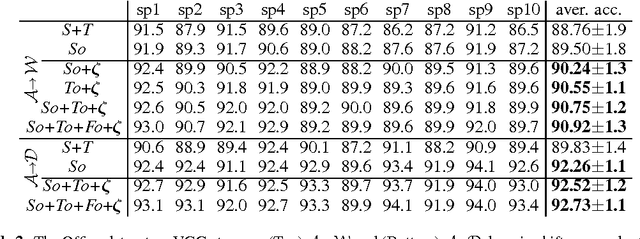
In this paper, we propose an approach to the domain adaptation, dubbed Second- or Higher-order Transfer of Knowledge (So-HoT), based on the mixture of alignments of second- or higher-order scatter statistics between the source and target domains. The human ability to learn from few labeled samples is a recurring motivation in the literature for domain adaptation. Towards this end, we investigate the supervised target scenario for which few labeled target training samples per category exist. Specifically, we utilize two CNN streams: the source and target networks fused at the classifier level. Features from the fully connected layers fc7 of each network are used to compute second- or even higher-order scatter tensors; one per network stream per class. As the source and target distributions are somewhat different despite being related, we align the scatters of the two network streams of the same class (within-class scatters) to a desired degree with our bespoke loss while maintaining good separation of the between-class scatters. We train the entire network in end-to-end fashion. We provide evaluations on the standard Office benchmark (visual domains), RGB-D combined with Caltech256 (depth-to-rgb transfer) and Pascal VOC2007 combined with the TU Berlin dataset (image-to-sketch transfer). We attain state-of-the-art results.