 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Crowd Behaviors in a Social Event by Passive WiFi Sensing and Data Mining
Feb 05, 2020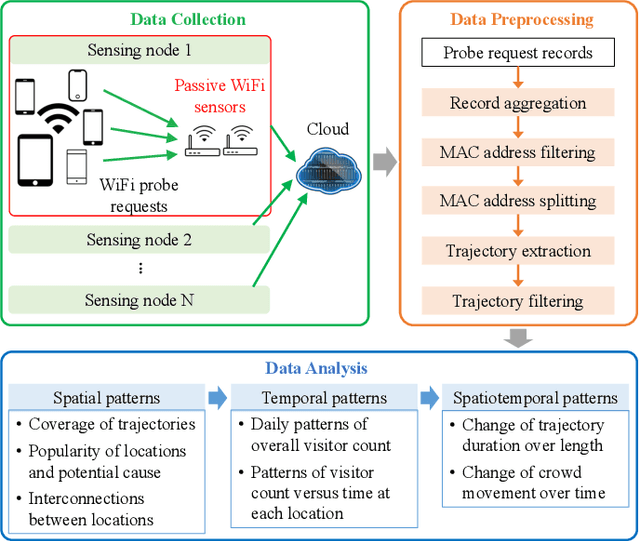
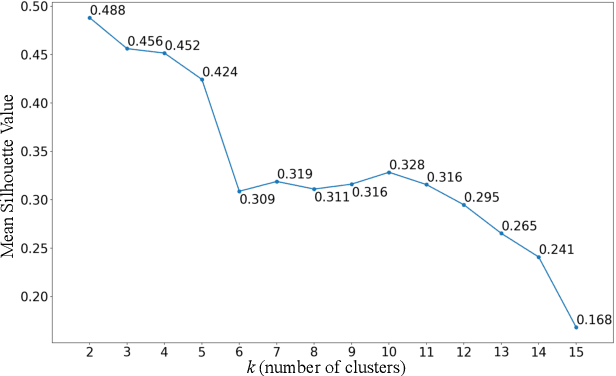
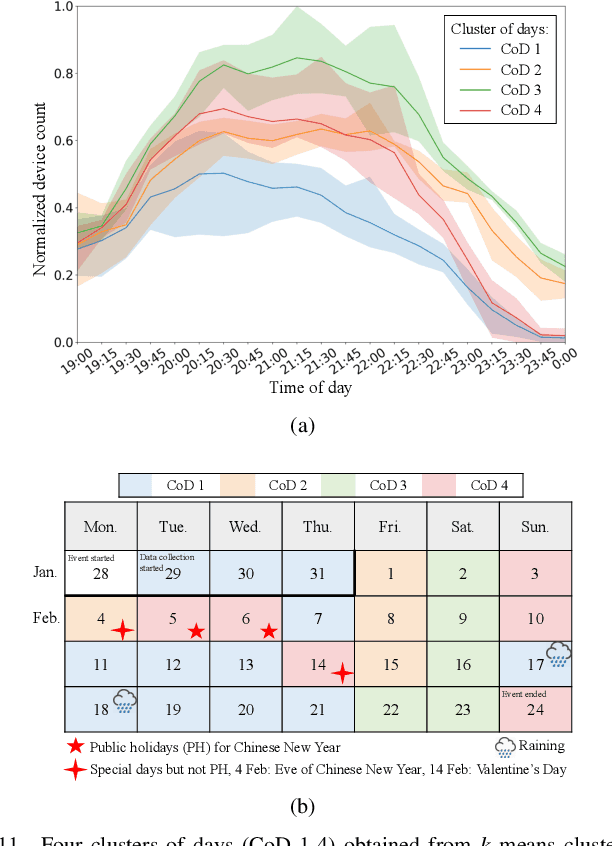
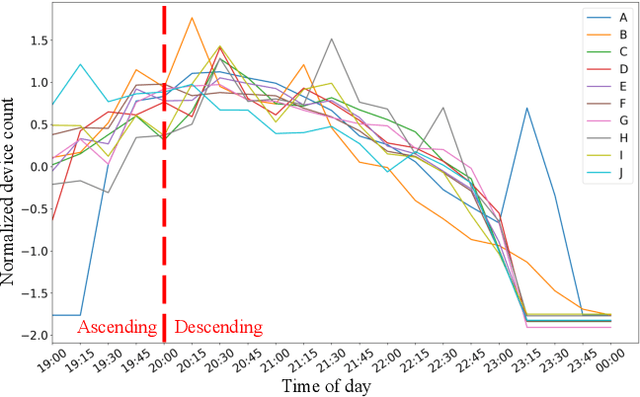
Understanding crowd behaviors in a large social event is crucial for event management. Passive WiFi sensing, by collecting WiFi probe requests sent from mobile devices, provides a better way to monitor crowds compared with people counters and cameras in terms of free interference, larger coverage, lower cost, and more information on people's movement. In existing studies, however, not enough attention has been paid to the thorough analysis and mining of collected data. Especially, the power of machine learning has not been fully exploited. In this paper, therefore, we propose a comprehensive data analysis framework to fully analyze the collected probe requests to extract three types of patterns related to crowd behaviors in a large social event, with the help of statistics, visualization, and unsupervised machine learning. First, trajectories of the mobile devices are extracted from probe requests and analyzed to reveal the spatial patterns of the crowds' movement. Hierarchical agglomerative clustering is adopted to find the interconnections between different locations. Next, k-means and k-shape clustering algorithms are applied to extract temporal visiting patterns of the crowds by days and locations, respectively. Finally, by combining with time, trajectories are transformed into spatiotemporal patterns, which reveal how trajectory duration changes over the length and how the overall trends of crowd movement change over time. The proposed data analysis framework is fully demonstrated using real-world data collected in a large social event. Results show that one can extract comprehensive patterns from data collected by a network of passive WiFi sensors.
Benchmarking air-conditioning energy performance of residential rooms based on regression and clustering techniques
Aug 22, 2019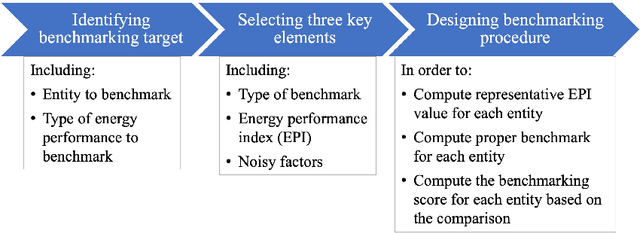
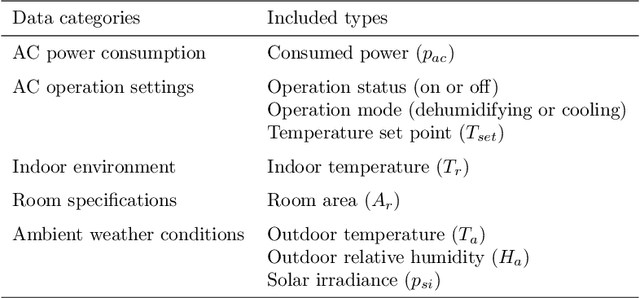
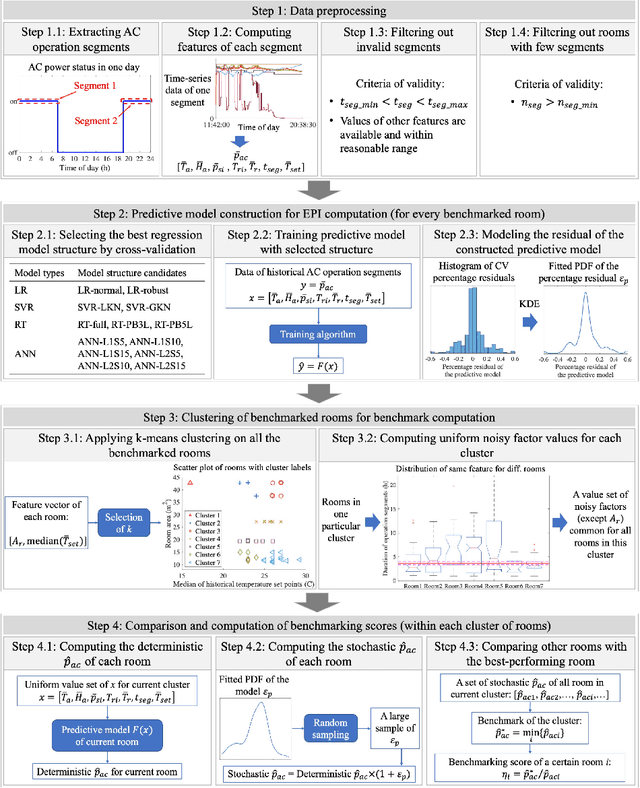
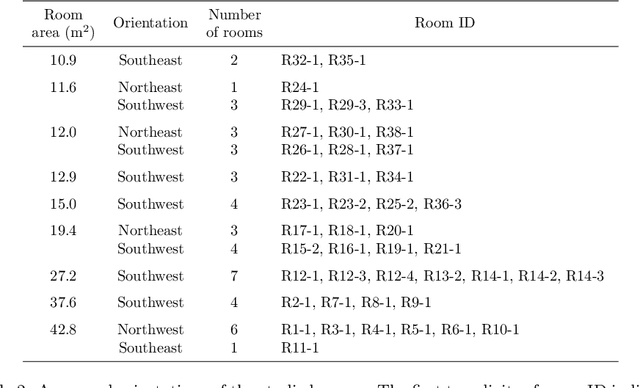
Air conditioning (AC) accounts for a critical portion of the global energy consumption. To improve its energy performance, it is important to fairly benchmark its energy performance and provide the evaluation feedback to users. However, this task has not been well tackled in the residential sector. In this paper, we propose a data-driven approach to fairly benchmark the AC energy performance of residential rooms. First, regression model is built for each benchmarked room so that its power consumption can be predicted given different weather conditions and AC settings. Then, all the rooms are clustered based on their areas and usual AC temperature set points. Lastly, within each cluster, rooms are benchmarked based on their predicted power consumption under uniform weather conditions and AC settings. A real-world case study was conducted with data collected from 44 residential rooms. Results show that the constructed regression models have an average prediction accuracy of 85.1% in cross-validation tests, and support vector regression with Gaussian kernel is the overall most suitable model structure for building the regression model. In the clustering step, 44 rooms are successfully clustered into seven clusters. By comparing the benchmarking scores generated by the proposed approach with two sets of scores computed from historical power consumption data, we demonstrate that the proposed approach is able to eliminate the influences of room areas, weather conditions, and AC settings on the benchmarking results. Therefore, the proposed benchmarking approach is valid and fair. As a by-product, the approach is also shown to be useful to investigate how room areas, weather conditions, and AC settings affect the AC power consumption of rooms in real life.
* 38 pages (single column), 7 figures, 6 tables. This manuscript is published in Applied Energy 253 (2019): 113548. Please refer to the published version at https://www.sciencedirect.com/science/article/pii/S030626191931222X
A Theoretical Framework of Approximation Error Analysis of Evolutionary Algorithms
Oct 26, 2018
In the empirical study of evolutionary algorithms, the solution quality is evaluated by either the fitness value or approximation error. The latter measures the fitness difference between an approximation solution and the optimal solution. Since the approximation error analysis is more convenient than the direct estimation of the fitness value, this paper focuses on approximation error analysis. However, it is straightforward to extend all related results from the approximation error to the fitness value. Although the evaluation of solution quality plays an essential role in practice, few rigorous analyses have been conducted on this topic. This paper aims at establishing a novel theoretical framework of approximation error analysis of evolutionary algorithms for discrete optimization. This framework is divided into two parts. The first part is about exact expressions of the approximation error. Two methods, Jordan form and Schur's triangularization, are presented to obtain an exact expression. The second part is about upper bounds on approximation error. Two methods, convergence rate and auxiliary matrix iteration, are proposed to estimate the upper bound. The applicability of this framework is demonstrated through several examples.
Analysis of Solution Quality of a Multiobjective Optimization-based Evolutionary Algorithm for Knapsack Problem
Feb 12, 2015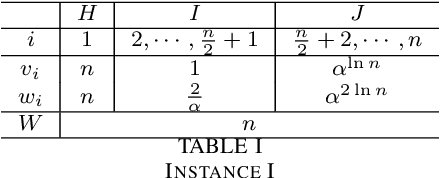
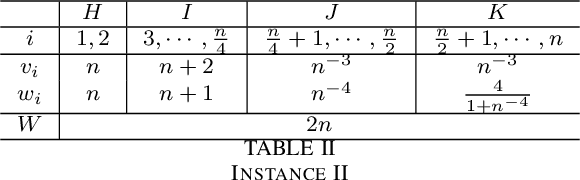
Multi-objective optimisation is regarded as one of the most promising ways for dealing with constrained optimisation problems in evolutionary optimisation. This paper presents a theoretical investigation of a multi-objective optimisation evolutionary algorithm for solving the 0-1 knapsack problem. Two initialisation methods are considered in the algorithm: local search initialisation and greedy search initialisation. Then the solution quality of the algorithm is analysed in terms of the approximation ratio.
Performance Analysis on Evolutionary Algorithms for the Minimum Label Spanning Tree Problem
Sep 03, 2014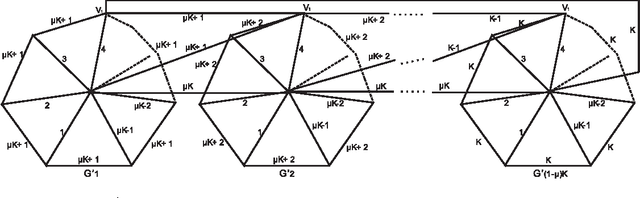
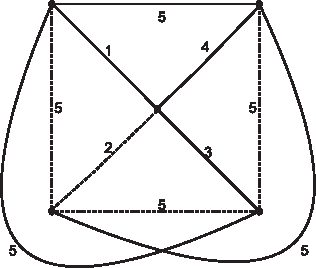
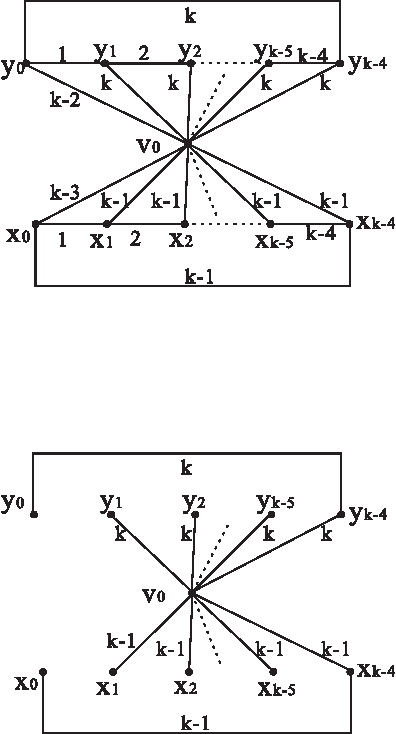
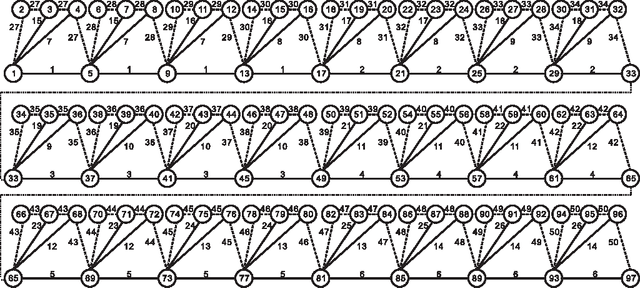
Some experimental investigations have shown that evolutionary algorithms (EAs) are efficient for the minimum label spanning tree (MLST) problem. However, we know little about that in theory. As one step towards this issue, we theoretically analyze the performances of the (1+1) EA, a simple version of EAs, and a multi-objective evolutionary algorithm called GSEMO on the MLST problem. We reveal that for the MLST$_{b}$ problem the (1+1) EA and GSEMO achieve a $\frac{b+1}{2}$-approximation ratio in expected polynomial times of $n$ the number of nodes and $k$ the number of labels. We also show that GSEMO achieves a $(2ln(n))$-approximation ratio for the MLST problem in expected polynomial time of $n$ and $k$. At the same time, we show that the (1+1) EA and GSEMO outperform local search algorithms on three instances of the MLST problem. We also construct an instance on which GSEMO outperforms the (1+1) EA.
A Theoretical Assessment of Solution Quality in Evolutionary Algorithms for the Knapsack Problem
Apr 14, 2014Evolutionary algorithms are well suited for solving the knapsack problem. Some empirical studies claim that evolutionary algorithms can produce good solutions to the 0-1 knapsack problem. Nonetheless, few rigorous investigations address the quality of solutions that evolutionary algorithms may produce for the knapsack problem. The current paper focuses on a theoretical investigation of three types of (N+1) evolutionary algorithms that exploit bitwise mutation, truncation selection, plus different repair methods for the 0-1 knapsack problem. It assesses the solution quality in terms of the approximation ratio. Our work indicates that the solution produced by pure strategy and mixed strategy evolutionary algorithms is arbitrarily bad. Nevertheless, the evolutionary algorithm using helper objectives may produce 1/2-approximation solutions to the 0-1 knapsack problem.