 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo You Know My Emotion? Emotion-Aware Strategy Recognition towards a Persuasive Dialogue System
Jun 24, 2022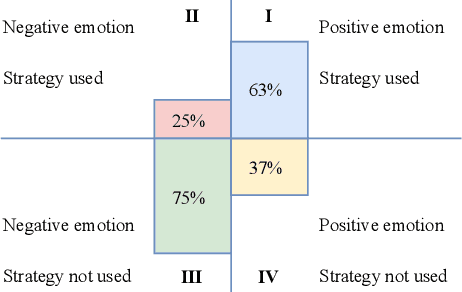
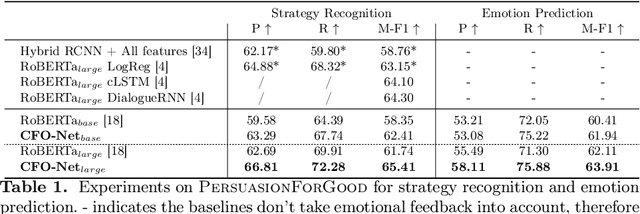
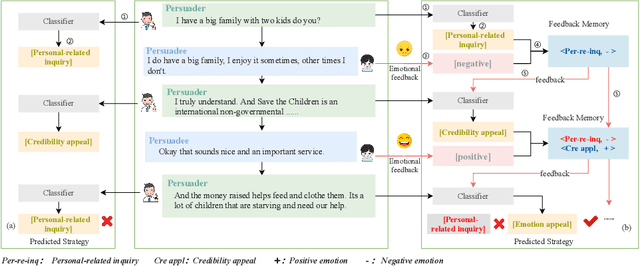

Persuasive strategy recognition task requires the system to recognize the adopted strategy of the persuader according to the conversation. However, previous methods mainly focus on the contextual information, little is known about incorporating the psychological feedback, i.e. emotion of the persuadee, to predict the strategy. In this paper, we propose a Cross-channel Feedback memOry Network (CFO-Net) to leverage the emotional feedback to iteratively measure the potential benefits of strategies and incorporate them into the contextual-aware dialogue information. Specifically, CFO-Net designs a feedback memory module, including strategy pool and feedback pool, to obtain emotion-aware strategy representation. The strategy pool aims to store historical strategies and the feedback pool is to obtain updated strategy weight based on feedback emotional information. Furthermore, a cross-channel fusion predictor is developed to make a mutual interaction between the emotion-aware strategy representation and the contextual-aware dialogue information for strategy recognition. Experimental results on \textsc{PersuasionForGood} confirm that the proposed model CFO-Net is effective to improve the performance on M-F1 from 61.74 to 65.41.
CogIntAc: Modeling the Relationships between Intention, Emotion and Action in Interactive Process from Cognitive Perspective
May 16, 2022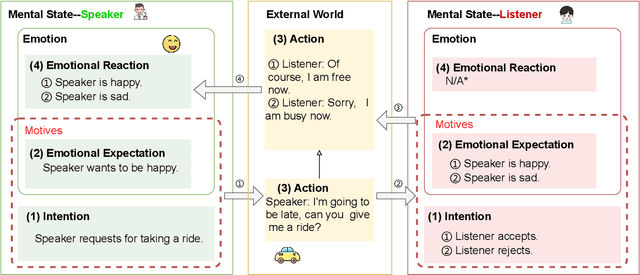
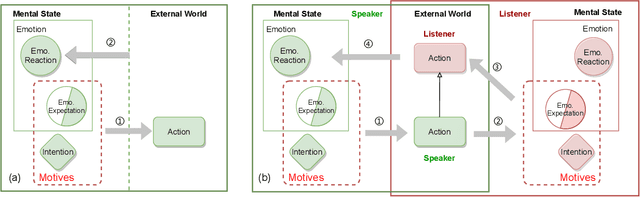
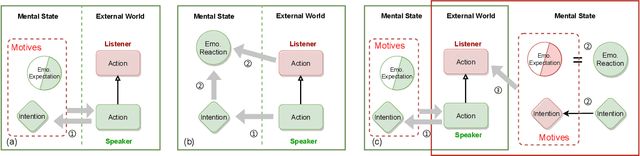
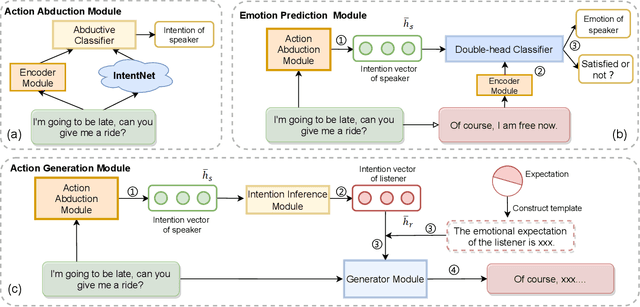
Intention, emotion and action are important psychological factors in human activities, which play an important role in the interaction between individuals. How to model the interaction process between individuals by analyzing the relationship of their intentions, emotions, and actions at the cognitive level is challenging. In this paper, we propose a novel cognitive framework of individual interaction. The core of the framework is that individuals achieve interaction through external action driven by their inner intention. Based on this idea, the interactions between individuals can be constructed by establishing relationships between the intention, emotion and action. Furthermore, we conduct analysis on the interaction between individuals and give a reasonable explanation for the predicting results. To verify the effectiveness of the framework, we reconstruct a dataset and propose three tasks as well as the corresponding baseline models, including action abduction, emotion prediction and action generation. The novel framework shows an interesting perspective on mimicking the mental state of human beings in cognitive science.
Control Globally, Understand Locally: A Global-to-Local Hierarchical Graph Network for Emotional Support Conversation
Apr 27, 2022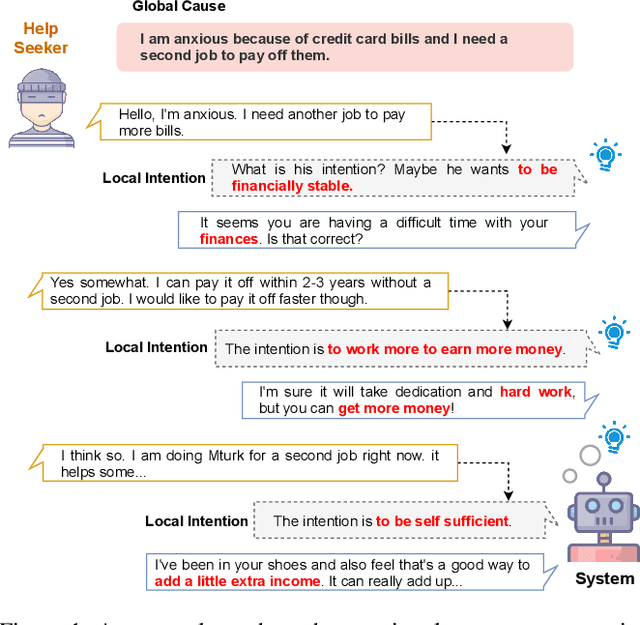
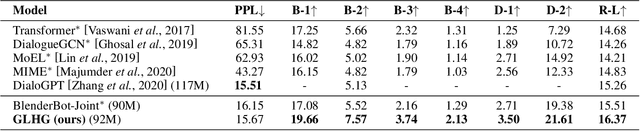
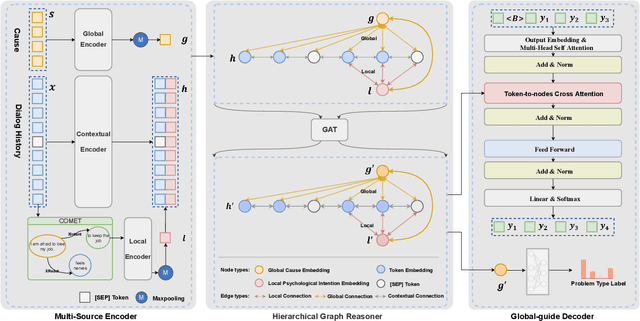
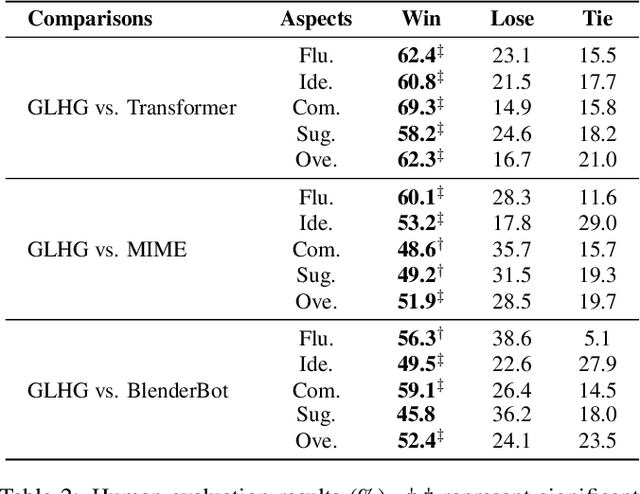
Emotional support conversation aims at reducing the emotional distress of the help-seeker, which is a new and challenging task. It requires the system to explore the cause of help-seeker's emotional distress and understand their psychological intention to provide supportive responses. However, existing methods mainly focus on the sequential contextual information, ignoring the hierarchical relationships with the global cause and local psychological intention behind conversations, thus leads to a weak ability of emotional support. In this paper, we propose a Global-to-Local Hierarchical Graph Network to capture the multi-source information (global cause, local intentions and dialog history) and model hierarchical relationships between them, which consists of a multi-source encoder, a hierarchical graph reasoner, and a global-guide decoder. Furthermore, a novel training objective is designed to monitor semantic information of the global cause. Experimental results on the emotional support conversation dataset, ESConv, confirm that the proposed GLHG has achieved the state-of-the-art performance on the automatic and human evaluations.
CLSEG: Contrastive Learning of Story Ending Generation
Feb 18, 2022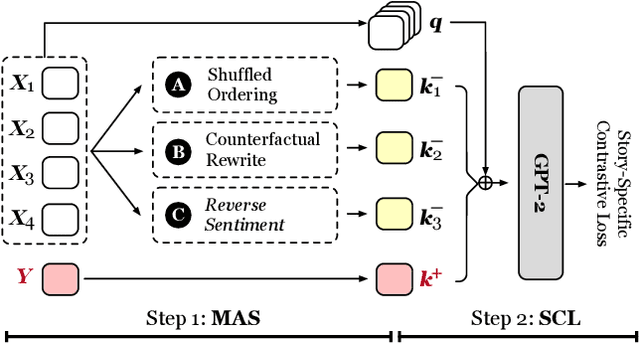

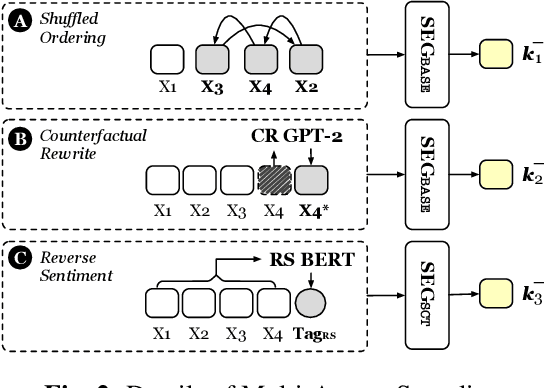
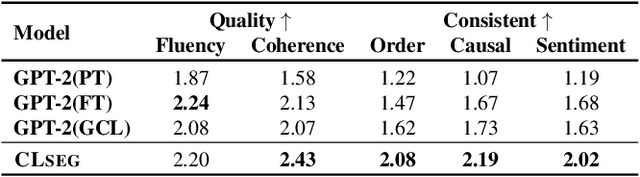
Story Ending Generation (SEG) is a challenging task in natural language generation. Recently, methods based on Pre-trained Language Models (PLM) have achieved great prosperity, which can produce fluent and coherent story endings. However, the pre-training objective of PLM-based methods is unable to model the consistency between story context and ending. The goal of this paper is to adopt contrastive learning to generate endings more consistent with story context, while there are two main challenges in contrastive learning of SEG. First is the negative sampling of wrong endings inconsistent with story contexts. The second challenge is the adaptation of contrastive learning for SEG. To address these two issues, we propose a novel Contrastive Learning framework for Story Ending Generation (CLSEG), which has two steps: multi-aspect sampling and story-specific contrastive learning. Particularly, for the first issue, we utilize novel multi-aspect sampling mechanisms to obtain wrong endings considering the consistency of order, causality, and sentiment. To solve the second issue, we well-design a story-specific contrastive training strategy that is adapted for SEG. Experiments show that CLSEG outperforms baselines and can produce story endings with stronger consistency and rationality.
Modeling Intention, Emotion and External World in Dialogue Systems
Feb 14, 2022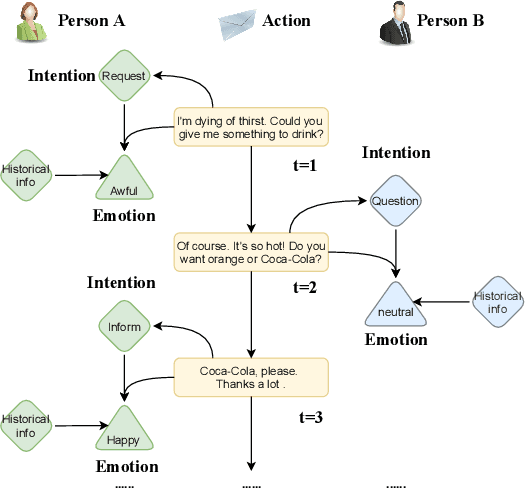
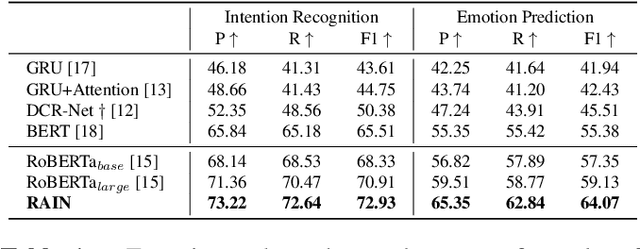
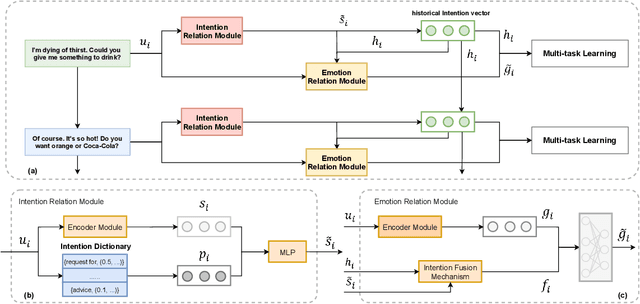
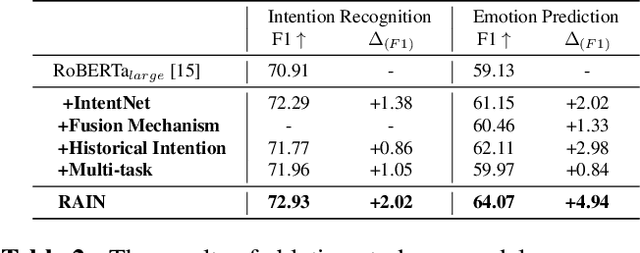
Intention, emotion and action are important elements in human activities. Modeling the interaction process between individuals by analyzing the relationships between these elements is a challenging task. However, previous work mainly focused on modeling intention and emotion independently, and neglected of exploring the mutual relationships between intention and emotion. In this paper, we propose a RelAtion Interaction Network (RAIN), consisting of Intention Relation Module and Emotion Relation Module, to jointly model mutual relationships and explicitly integrate historical intention information. The experiments on the dataset show that our model can take full advantage of the intention, emotion and action between individuals and achieve a remarkable improvement over BERT-style baselines. Qualitative analysis verifies the importance of the mutual interaction between the intention and emotion.
Know Deeper: Knowledge-Conversation Cyclic Utilization Mechanism for Open-domain Dialogue Generation
Jul 16, 2021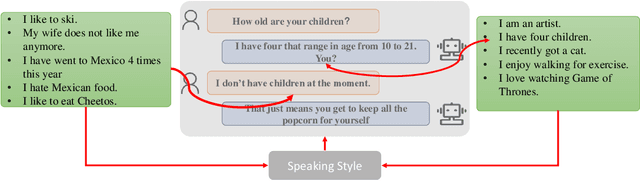
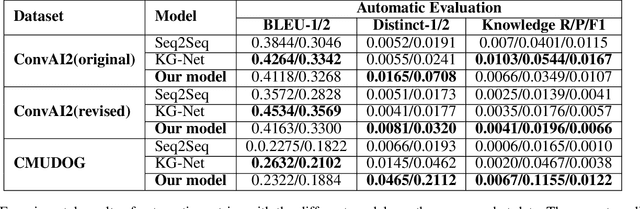
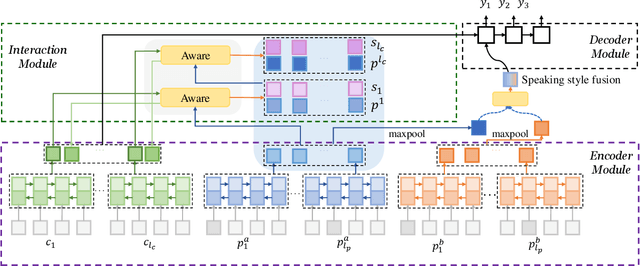
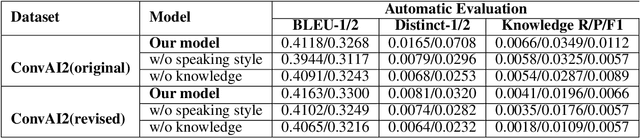
End-to-End intelligent neural dialogue systems suffer from the problems of generating inconsistent and repetitive responses. Existing dialogue models pay attention to unilaterally incorporating personal knowledge into the dialog while ignoring the fact that incorporating the personality-related conversation information into personal knowledge taken as the bilateral information flow boosts the quality of the subsequent conversation. Besides, it is indispensable to control personal knowledge utilization over the conversation level. In this paper, we propose a conversation-adaption multi-view persona aware response generation model that aims at enhancing conversation consistency and alleviating the repetition from two folds. First, we consider conversation consistency from multiple views. From the view of the persona profile, we design a novel interaction module that not only iteratively incorporates personalized knowledge into each turn conversation but also captures the personality-related information from conversation to enhance personalized knowledge semantic representation. From the view of speaking style, we introduce the speaking style vector and feed it into the decoder to keep the speaking style consistency. To avoid conversation repetition, we devise a coverage mechanism to keep track of the activation of personal knowledge utilization. Experiments on both automatic and human evaluation verify the superiority of our model over previous models.
Coarse-to-Careful: Seeking Semantic-related Knowledge for Open-domain Commonsense Question Answering
Jul 04, 2021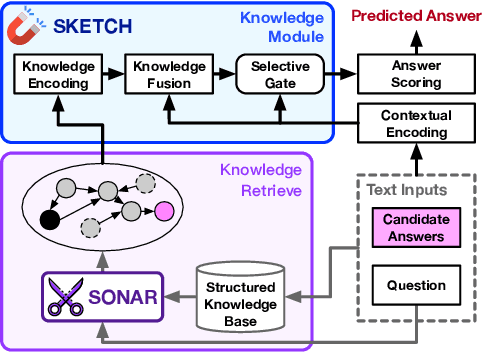
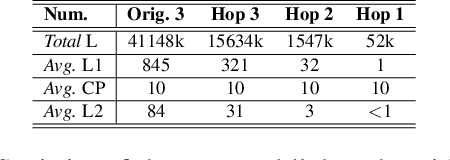
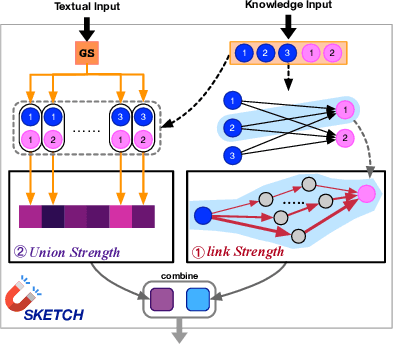
It is prevalent to utilize external knowledge to help machine answer questions that need background commonsense, which faces a problem that unlimited knowledge will transmit noisy and misleading information. Towards the issue of introducing related knowledge, we propose a semantic-driven knowledge-aware QA framework, which controls the knowledge injection in a coarse-to-careful fashion. We devise a tailoring strategy to filter extracted knowledge under monitoring of the coarse semantic of question on the knowledge extraction stage. And we develop a semantic-aware knowledge fetching module that engages structural knowledge information and fuses proper knowledge according to the careful semantic of questions in a hierarchical way. Experiments demonstrate that the proposed approach promotes the performance on the CommonsenseQA dataset comparing with strong baselines.
MCR-Net: A Multi-Step Co-Interactive Relation Network for Unanswerable Questions on Machine Reading Comprehension
Mar 08, 2021
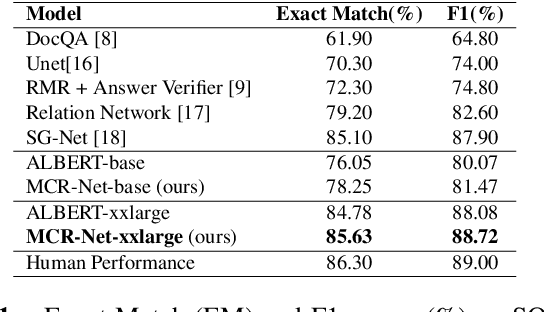
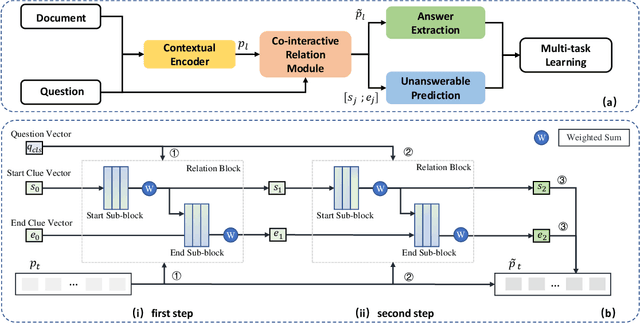
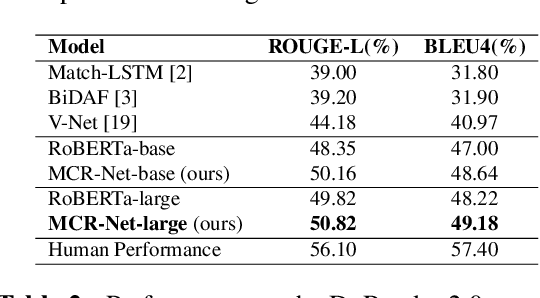
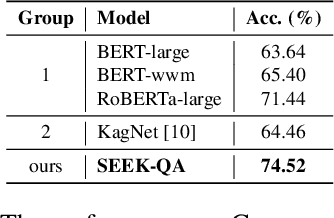
Question answering systems usually use keyword searches to retrieve potential passages related to a question, and then extract the answer from passages with the machine reading comprehension methods. However, many questions tend to be unanswerable in the real world. In this case, it is significant and challenging how the model determines when no answer is supported by the passage and abstains from answering. Most of the existing systems design a simple classifier to determine answerability implicitly without explicitly modeling mutual interaction and relation between the question and passage, leading to the poor performance for determining the unanswerable questions. To tackle this problem, we propose a Multi-Step Co-Interactive Relation Network (MCR-Net) to explicitly model the mutual interaction and locate key clues from coarse to fine by introducing a co-interactive relation module. The co-interactive relation module contains a stack of interaction and fusion blocks to continuously integrate and fuse history-guided and current-query-guided clues in an explicit way. Experiments on the SQuAD 2.0 and DuReader datasets show that our model achieves a remarkable improvement, outperforming the BERT-style baselines in literature. Visualization analysis also verifies the importance of the mutual interaction between the question and passage.
IIE-NLP-Eyas at SemEval-2021 Task 4: Enhancing PLM for ReCAM with Special Tokens, Re-Ranking, Siamese Encoders and Back Translation
Feb 25, 2021
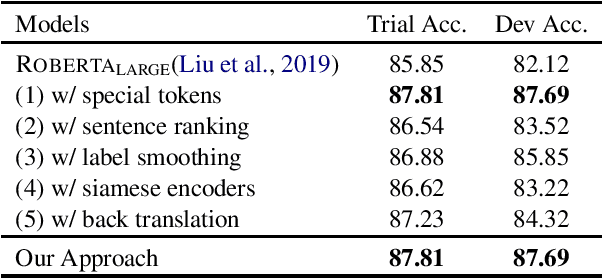
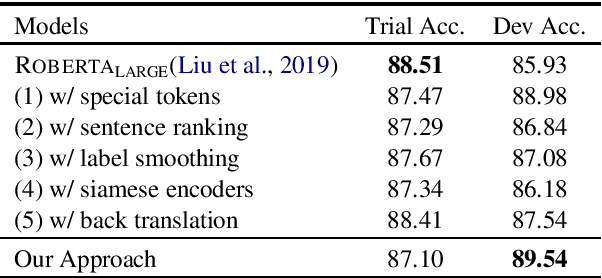
This paper introduces our systems for all three subtasks of SemEval-2021 Task 4: Reading Comprehension of Abstract Meaning. To help our model better represent and understand abstract concepts in natural language, we well-design many simple and effective approaches adapted to the backbone model (RoBERTa). Specifically, we formalize the subtasks into the multiple-choice question answering format and add special tokens to abstract concepts, then, the final prediction of question answering is considered as the result of subtasks. Additionally, we employ many finetuning tricks to improve the performance. Experimental results show that our approaches achieve significant performance compared with the baseline systems. Our approaches achieve eighth rank on subtask-1 and tenth rank on subtask-2.
Bi-directional Cognitive Thinking Network for Machine Reading Comprehension
Oct 20, 2020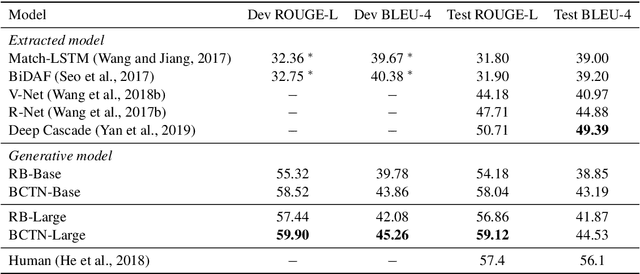
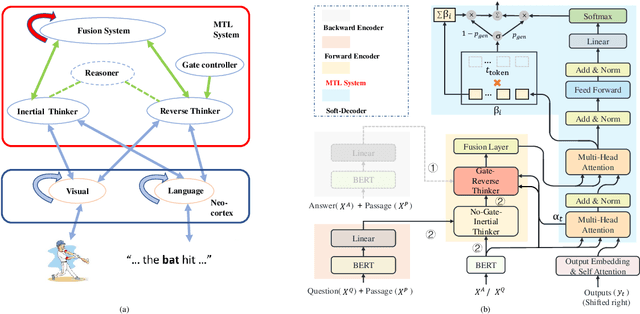

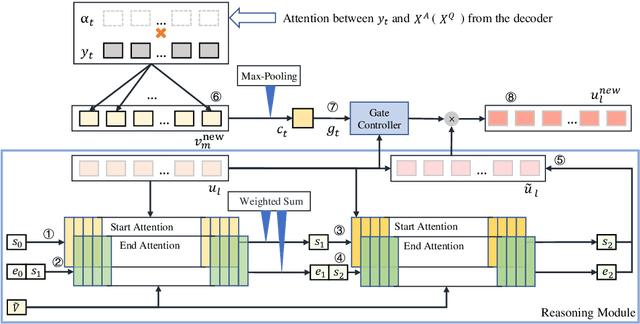
We propose a novel Bi-directional Cognitive Knowledge Framework (BCKF) for reading comprehension from the perspective of complementary learning systems theory. It aims to simulate two ways of thinking in the brain to answer questions, including reverse thinking and inertial thinking. To validate the effectiveness of our framework, we design a corresponding Bi-directional Cognitive Thinking Network (BCTN) to encode the passage and generate a question (answer) given an answer (question) and decouple the bi-directional knowledge. The model has the ability to reverse reasoning questions which can assist inertial thinking to generate more accurate answers. Competitive improvement is observed in DuReader dataset, confirming our hypothesis that bi-directional knowledge helps the QA task. The novel framework shows an interesting perspective on machine reading comprehension and cognitive science.