 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBorderless Long Speech Synthesis
Mar 20, 2026Most existing text-to-speech (TTS) systems either synthesize speech sentence by sentence and stitch the results together, or drive synthesis from plain-text dialogues alone. Both approaches leave models with little understanding of global context or paralinguistic cues, making it hard to capture real-world phenomena such as multi-speaker interactions (interruptions, overlapping speech), evolving emotional arcs, and varied acoustic environments. We introduce the Borderless Long Speech Synthesis framework for agent-centric, borderless long audio synthesis. Rather than targeting a single narrow task, the system is designed as a unified capability set spanning VoiceDesigner, multi-speaker synthesis, Instruct TTS, and long-form text synthesis. On the data side, we propose a "Labeling over filtering/cleaning" strategy and design a top-down, multi-level annotation schema we call Global-Sentence-Token. On the model side, we adopt a backbone with a continuous tokenizer and add Chain-of-Thought (CoT) reasoning together with Dimension Dropout, both of which markedly improve instruction following under complex conditions. We further show that the system is Native Agentic by design: the hierarchical annotation doubles as a Structured Semantic Interface between the LLM Agent and the synthesis engine, creating a layered control protocol stack that spans from scene semantics down to phonetic detail. Text thereby becomes an information-complete, wide-band control channel, enabling a front-end LLM to convert inputs of any modality into structured generation commands, extending the paradigm from Text2Speech to borderless long speech synthesis.
PAMA-TTS: Progression-Aware Monotonic Attention for Stable Seq2Seq TTS With Accurate Phoneme Duration Control
Oct 09, 2021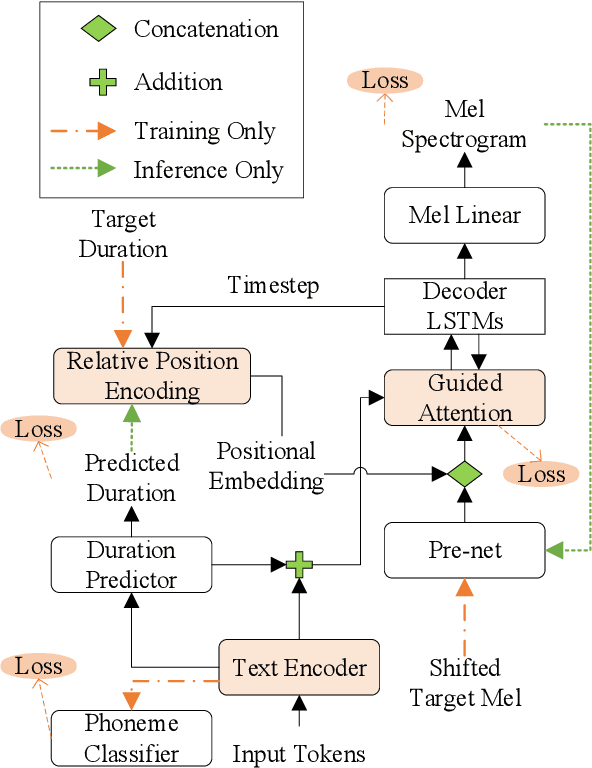
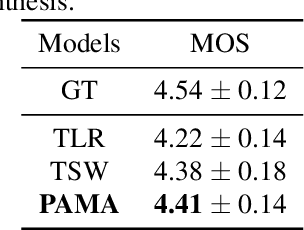
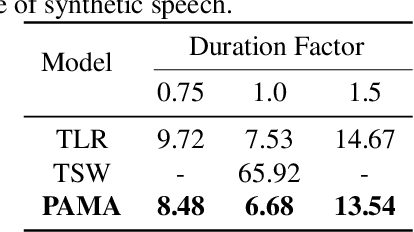
Sequence expansion between encoder and decoder is a critical challenge in sequence-to-sequence TTS. Attention-based methods achieve great naturalness but suffer from unstable issues like missing and repeating phonemes, not to mention accurate duration control. Duration-informed methods, on the contrary, seem to easily adjust phoneme duration but show obvious degradation in speech naturalness. This paper proposes PAMA-TTS to address the problem. It takes the advantage of both flexible attention and explicit duration models. Based on the monotonic attention mechanism, PAMA-TTS also leverages token duration and relative position of a frame, especially countdown information, i.e. in how many future frames the present phoneme will end. They help the attention to move forward along the token sequence in a soft but reliable control. Experimental results prove that PAMA-TTS achieves the highest naturalness, while has on-par or even better duration controllability than the duration-informed model.
RawNet: Fast End-to-End Neural Vocoder
Apr 10, 2019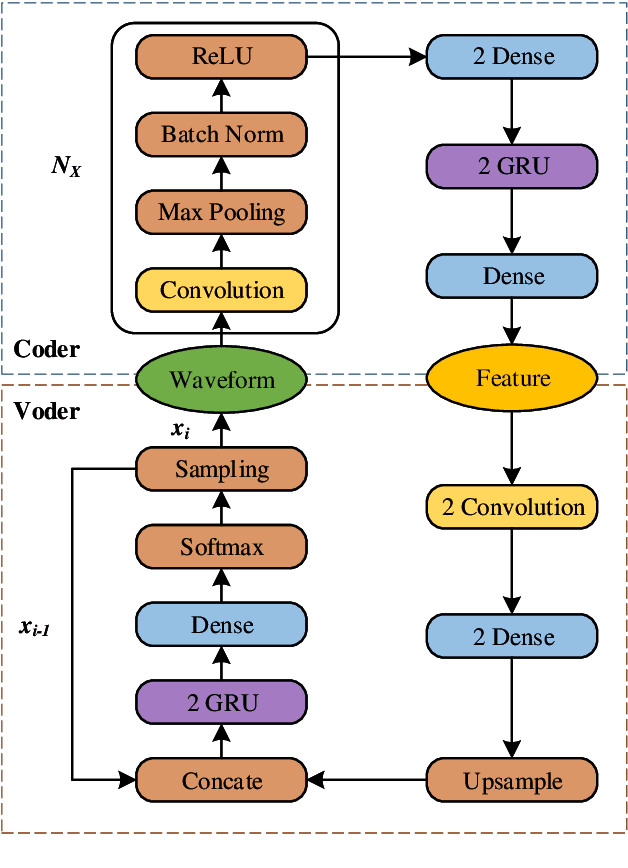
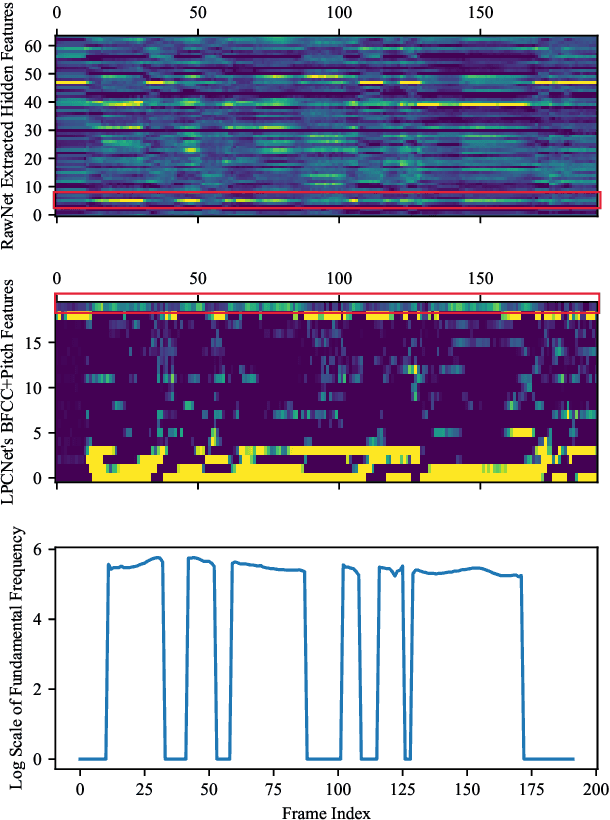
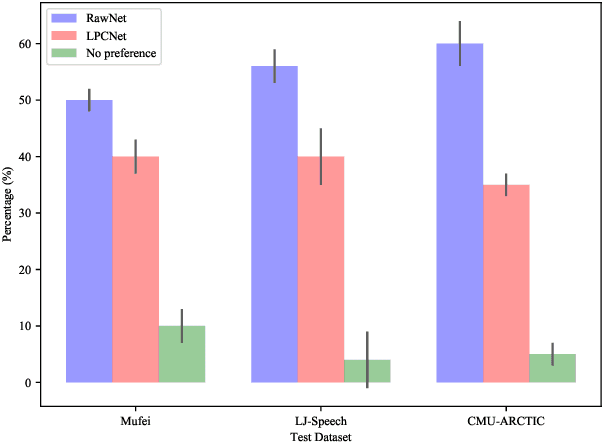
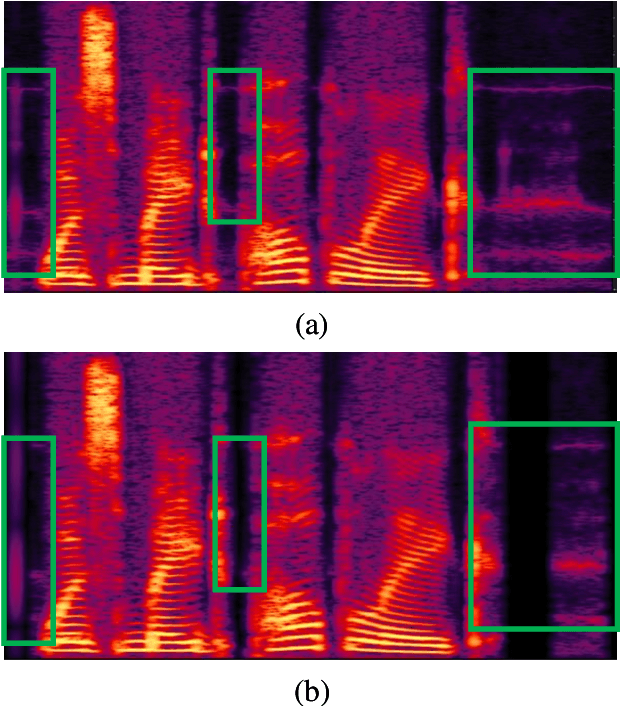
Neural networks based vocoders have recently demonstrated the powerful ability to synthesize high quality speech. These models usually generate samples by conditioning on some spectrum features, such as Mel-spectrum. However, these features are extracted by using speech analysis module including some processing based on the human knowledge. In this work, we proposed RawNet, a truly end-to-end neural vocoder, which use a coder network to learn the higher representation of signal, and an autoregressive voder network to generate speech sample by sample. The coder and voder together act like an auto-encoder network, and could be jointly trained directly on raw waveform without any human-designed features. The experiments on the Copy-Synthesis tasks show that RawNet can achieve the comparative synthesized speech quality with LPCNet, with a smaller model architecture and faster speech generation at the inference step.