 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering the Missing Pattern: Unified Framework Towards Trajectory Imputation and Prediction
Mar 28, 2023



Trajectory prediction is a crucial undertaking in understanding entity movement or human behavior from observed sequences. However, current methods often assume that the observed sequences are complete while ignoring the potential for missing values caused by object occlusion, scope limitation, sensor failure, etc. This limitation inevitably hinders the accuracy of trajectory prediction. To address this issue, our paper presents a unified framework, the Graph-based Conditional Variational Recurrent Neural Network (GC-VRNN), which can perform trajectory imputation and prediction simultaneously. Specifically, we introduce a novel Multi-Space Graph Neural Network (MS-GNN) that can extract spatial features from incomplete observations and leverage missing patterns. Additionally, we employ a Conditional VRNN with a specifically designed Temporal Decay (TD) module to capture temporal dependencies and temporal missing patterns in incomplete trajectories. The inclusion of the TD module allows for valuable information to be conveyed through the temporal flow. We also curate and benchmark three practical datasets for the joint problem of trajectory imputation and prediction. Extensive experiments verify the exceptional performance of our proposed method. As far as we know, this is the first work to address the lack of benchmarks and techniques for trajectory imputation and prediction in a unified manner.
Frame Flexible Network
Mar 26, 2023Existing video recognition algorithms always conduct different training pipelines for inputs with different frame numbers, which requires repetitive training operations and multiplying storage costs. If we evaluate the model using other frames which are not used in training, we observe the performance will drop significantly (see Fig.1), which is summarized as Temporal Frequency Deviation phenomenon. To fix this issue, we propose a general framework, named Frame Flexible Network (FFN), which not only enables the model to be evaluated at different frames to adjust its computation, but also reduces the memory costs of storing multiple models significantly. Concretely, FFN integrates several sets of training sequences, involves Multi-Frequency Alignment (MFAL) to learn temporal frequency invariant representations, and leverages Multi-Frequency Adaptation (MFAD) to further strengthen the representation abilities. Comprehensive empirical validations using various architectures and popular benchmarks solidly demonstrate the effectiveness and generalization of FFN (e.g., 7.08/5.15/2.17% performance gain at Frame 4/8/16 on Something-Something V1 dataset over Uniformer). Code is available at https://github.com/BeSpontaneous/FFN.
Contrastive Alignment of Vision to Language Through Parameter-Efficient Transfer Learning
Mar 21, 2023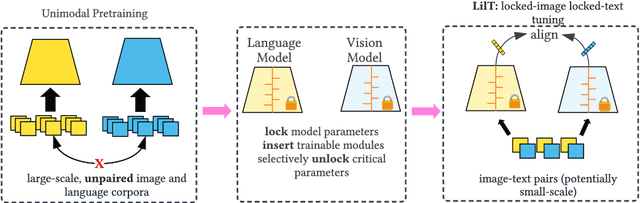

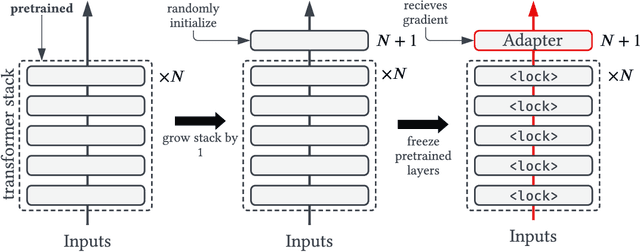
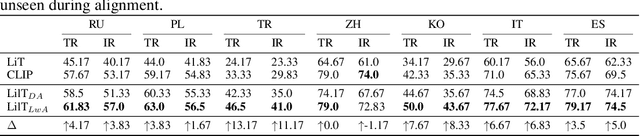
Contrastive vision-language models (e.g. CLIP) are typically created by updating all the parameters of a vision model and language model through contrastive training. Can such models be created by a small number of parameter updates to an already-trained language model and vision model? The literature describes techniques that can create vision-language models by updating a small number of parameters in a language model, but these require already aligned visual representations and are non-contrastive, hence unusable for latency-sensitive applications such as neural search. We explore the feasibility and benefits of parameter-efficient contrastive vision-language alignment through transfer learning: creating a model such as CLIP by minimally updating an already-trained vision and language model. We find that a minimal set of parameter updates ($<$7%) can achieve the same performance as full-model training, and updating specific components ($<$1% of parameters) can match 75% of full-model training. We describe a series of experiments: we show that existing knowledge is conserved more strongly in parameter-efficient training and that parameter-efficient scaling scales with model and dataset size. Where paired-image text data is scarce but strong multilingual language models exist (e.g. low resource languages), parameter-efficient training is even preferable to full-model training. Given a fixed compute budget, parameter-efficient training allows training larger models on the same hardware, achieving equivalent performance in less time. Parameter-efficient training hence constitutes an energy-efficient and effective training strategy for contrastive vision-language models that may be preferable to the full-model training paradigm for common use cases. Code and weights at https://github.com/codezakh/LilT.
GlueGen: Plug and Play Multi-modal Encoders for X-to-image Generation
Mar 17, 2023Text-to-image (T2I) models based on diffusion processes have achieved remarkable success in controllable image generation using user-provided captions. However, the tight coupling between the current text encoder and image decoder in T2I models makes it challenging to replace or upgrade. Such changes often require massive fine-tuning or even training from scratch with the prohibitive expense. To address this problem, we propose GlueGen, which applies a newly proposed GlueNet model to align features from single-modal or multi-modal encoders with the latent space of an existing T2I model. The approach introduces a new training objective that leverages parallel corpora to align the representation spaces of different encoders. Empirical results show that GlueNet can be trained efficiently and enables various capabilities beyond previous state-of-the-art models: 1) multilingual language models such as XLM-Roberta can be aligned with existing T2I models, allowing for the generation of high-quality images from captions beyond English; 2) GlueNet can align multi-modal encoders such as AudioCLIP with the Stable Diffusion model, enabling sound-to-image generation; 3) it can also upgrade the current text encoder of the latent diffusion model for challenging case generation. By the alignment of various feature representations, the GlueNet allows for flexible and efficient integration of new functionality into existing T2I models and sheds light on X-to-image (X2I) generation.
Iterative Soft Shrinkage Learning for Efficient Image Super-Resolution
Mar 16, 2023The field of image super-resolution (SR) has witnessed extensive neural network designs from CNN to transformer architectures. However, prevailing SR models suffer from prohibitive memory footprint and intensive computations, which limits further deployment on computational-constrained platforms. In this work, we investigate the potential of network pruning for super-resolution to take advantage of off-the-shelf network designs and reduce the underlying computational overhead. Two main challenges remain in applying pruning methods for SR. First, the widely-used filter pruning technique reflects limited granularity and restricted adaptability to diverse network structures. Second, existing pruning methods generally operate upon a pre-trained network for the sparse structure determination, failing to get rid of dense model training in the traditional SR paradigm. To address these challenges, we adopt unstructured pruning with sparse models directly trained from scratch. Specifically, we propose a novel Iterative Soft Shrinkage-Percentage (ISS-P) method by optimizing the sparse structure of a randomly initialized network at each iteration and tweaking unimportant weights with a small amount proportional to the magnitude scale on-the-fly. We observe that the proposed ISS-P could dynamically learn sparse structures adapting to the optimization process and preserve the sparse model's trainability by yielding a more regularized gradient throughput. Experiments on benchmark datasets demonstrate the effectiveness of the proposed ISS-P compared with state-of-the-art methods over diverse network architectures.
Image as Set of Points
Mar 02, 2023What is an image and how to extract latent features? Convolutional Networks (ConvNets) consider an image as organized pixels in a rectangular shape and extract features via convolutional operation in local region; Vision Transformers (ViTs) treat an image as a sequence of patches and extract features via attention mechanism in a global range. In this work, we introduce a straightforward and promising paradigm for visual representation, which is called Context Clusters. Context clusters (CoCs) view an image as a set of unorganized points and extract features via simplified clustering algorithm. In detail, each point includes the raw feature (e.g., color) and positional information (e.g., coordinates), and a simplified clustering algorithm is employed to group and extract deep features hierarchically. Our CoCs are convolution- and attention-free, and only rely on clustering algorithm for spatial interaction. Owing to the simple design, we show CoCs endow gratifying interpretability via the visualization of clustering process. Our CoCs aim at providing a new perspective on image and visual representation, which may enjoy broad applications in different domains and exhibit profound insights. Even though we are not targeting SOTA performance, COCs still achieve comparable or even better results than ConvNets or ViTs on several benchmarks. Codes are available at: https://github.com/ma-xu/Context-Cluster.
Towards Explainable Visual Anomaly Detection
Feb 13, 2023



Anomaly detection and localization of visual data, including images and videos, are of great significance in both machine learning academia and applied real-world scenarios. Despite the rapid development of visual anomaly detection techniques in recent years, the interpretations of these black-box models and reasonable explanations of why anomalies can be distinguished out are scarce. This paper provides the first survey concentrated on explainable visual anomaly detection methods. We first introduce the basic background of image-level anomaly detection and video-level anomaly detection, followed by the current explainable approaches for visual anomaly detection. Then, as the main content of this survey, a comprehensive and exhaustive literature review of explainable anomaly detection methods for both images and videos is presented. Finally, we discuss several promising future directions and open problems to explore on the explainability of visual anomaly detection.
Making Reconstruction-based Method Great Again for Video Anomaly Detection
Jan 28, 2023



Anomaly detection in videos is a significant yet challenging problem. Previous approaches based on deep neural networks employ either reconstruction-based or prediction-based approaches. Nevertheless, existing reconstruction-based methods 1) rely on old-fashioned convolutional autoencoders and are poor at modeling temporal dependency; 2) are prone to overfit the training samples, leading to indistinguishable reconstruction errors of normal and abnormal frames during the inference phase. To address such issues, firstly, we get inspiration from transformer and propose ${\textbf S}$patio-${\textbf T}$emporal ${\textbf A}$uto-${\textbf T}$rans-${\textbf E}$ncoder, dubbed as $\textbf{STATE}$, as a new autoencoder model for enhanced consecutive frame reconstruction. Our STATE is equipped with a specifically designed learnable convolutional attention module for efficient temporal learning and reasoning. Secondly, we put forward a novel reconstruction-based input perturbation technique during testing to further differentiate anomalous frames. With the same perturbation magnitude, the testing reconstruction error of the normal frames lowers more than that of the abnormal frames, which contributes to mitigating the overfitting problem of reconstruction. Owing to the high relevance of the frame abnormality and the objects in the frame, we conduct object-level reconstruction using both the raw frame and the corresponding optical flow patches. Finally, the anomaly score is designed based on the combination of the raw and motion reconstruction errors using perturbed inputs. Extensive experiments on benchmark video anomaly detection datasets demonstrate that our approach outperforms previous reconstruction-based methods by a notable margin, and achieves state-of-the-art anomaly detection performance consistently. The code is available at https://github.com/wyzjack/MRMGA4VAD.
Why is the State of Neural Network Pruning so Confusing? On the Fairness, Comparison Setup, and Trainability in Network Pruning
Jan 12, 2023The state of neural network pruning has been noticed to be unclear and even confusing for a while, largely due to "a lack of standardized benchmarks and metrics" [3]. To standardize benchmarks, first, we need to answer: what kind of comparison setup is considered fair? This basic yet crucial question has barely been clarified in the community, unfortunately. Meanwhile, we observe several papers have used (severely) sub-optimal hyper-parameters in pruning experiments, while the reason behind them is also elusive. These sub-optimal hyper-parameters further exacerbate the distorted benchmarks, rendering the state of neural network pruning even more obscure. Two mysteries in pruning represent such a confusing status: the performance-boosting effect of a larger finetuning learning rate, and the no-value argument of inheriting pretrained weights in filter pruning. In this work, we attempt to explain the confusing state of network pruning by demystifying the two mysteries. Specifically, (1) we first clarify the fairness principle in pruning experiments and summarize the widely-used comparison setups; (2) then we unveil the two pruning mysteries and point out the central role of network trainability, which has not been well recognized so far; (3) finally, we conclude the paper and give some concrete suggestions regarding how to calibrate the pruning benchmarks in the future. Code: https://github.com/mingsun-tse/why-the-state-of-pruning-so-confusing.
A Close Look at Spatial Modeling: From Attention to Convolution
Dec 23, 2022Vision Transformers have shown great promise recently for many vision tasks due to the insightful architecture design and attention mechanism. By revisiting the self-attention responses in Transformers, we empirically observe two interesting issues. First, Vision Transformers present a queryirrelevant behavior at deep layers, where the attention maps exhibit nearly consistent contexts in global scope, regardless of the query patch position (also head-irrelevant). Second, the attention maps are intrinsically sparse, few tokens dominate the attention weights; introducing the knowledge from ConvNets would largely smooth the attention and enhance the performance. Motivated by above observations, we generalize self-attention formulation to abstract a queryirrelevant global context directly and further integrate the global context into convolutions. The resulting model, a Fully Convolutional Vision Transformer (i.e., FCViT), purely consists of convolutional layers and firmly inherits the merits of both attention mechanism and convolutions, including dynamic property, weight sharing, and short- and long-range feature modeling, etc. Experimental results demonstrate the effectiveness of FCViT. With less than 14M parameters, our FCViT-S12 outperforms related work ResT-Lite by 3.7% top1 accuracy on ImageNet-1K. When scaling FCViT to larger models, we still perform better than previous state-of-the-art ConvNeXt with even fewer parameters. FCViT-based models also demonstrate promising transferability to downstream tasks, like object detection, instance segmentation, and semantic segmentation. Codes and models are made available at: https://github.com/ma-xu/FCViT.