 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyMPs: One-Shot Vision-Language Guided Motion Generation by Sequencing DMPs for Occlusion-Rich Tasks
Apr 14, 2025



Dynamic Movement Primitives (DMPs) provide a flexible framework wherein smooth robotic motions are encoded into modular parameters. However, they face challenges in integrating multimodal inputs commonly used in robotics like vision and language into their framework. To fully maximize DMPs' potential, enabling them to handle multimodal inputs is essential. In addition, we also aim to extend DMPs' capability to handle object-focused tasks requiring one-shot complex motion generation, as observation occlusion could easily happen mid-execution in such tasks (e.g., knife occlusion in cake icing, hand occlusion in dough kneading, etc.). A promising approach is to leverage Vision-Language Models (VLMs), which process multimodal data and can grasp high-level concepts. However, they typically lack enough knowledge and capabilities to directly infer low-level motion details and instead only serve as a bridge between high-level instructions and low-level control. To address this limitation, we propose Keyword Labeled Primitive Selection and Keypoint Pairs Generation Guided Movement Primitives (KeyMPs), a framework that combines VLMs with sequencing of DMPs. KeyMPs use VLMs' high-level reasoning capability to select a reference primitive through keyword labeled primitive selection and VLMs' spatial awareness to generate spatial scaling parameters used for sequencing DMPs by generalizing the overall motion through keypoint pairs generation, which together enable one-shot vision-language guided motion generation that aligns with the intent expressed in the multimodal input. We validate our approach through an occlusion-rich manipulation task, specifically object cutting experiments in both simulated and real-world environments, demonstrating superior performance over other DMP-based methods that integrate VLMs support.
Self-Supervised Learning of Grasping Arbitrary Objects On-the-Move
Nov 15, 2024



Mobile grasping enhances manipulation efficiency by utilizing robots' mobility. This study aims to enable a commercial off-the-shelf robot for mobile grasping, requiring precise timing and pose adjustments. Self-supervised learning can develop a generalizable policy to adjust the robot's velocity and determine grasp position and orientation based on the target object's shape and pose. Due to mobile grasping's complexity, action primitivization and step-by-step learning are crucial to avoid data sparsity in learning from trial and error. This study simplifies mobile grasping into two grasp action primitives and a moving action primitive, which can be operated with limited degrees of freedom for the manipulator. This study introduces three fully convolutional neural network (FCN) models to predict static grasp primitive, dynamic grasp primitive, and residual moving velocity error from visual inputs. A two-stage grasp learning approach facilitates seamless FCN model learning. The ablation study demonstrated that the proposed method achieved the highest grasping accuracy and pick-and-place efficiency. Furthermore, randomizing object shapes and environments in the simulation effectively achieved generalizable mobile grasping.
Randomized-to-Canonical Model Predictive Control for Real-world Visual Robotic Manipulation
Jul 05, 2022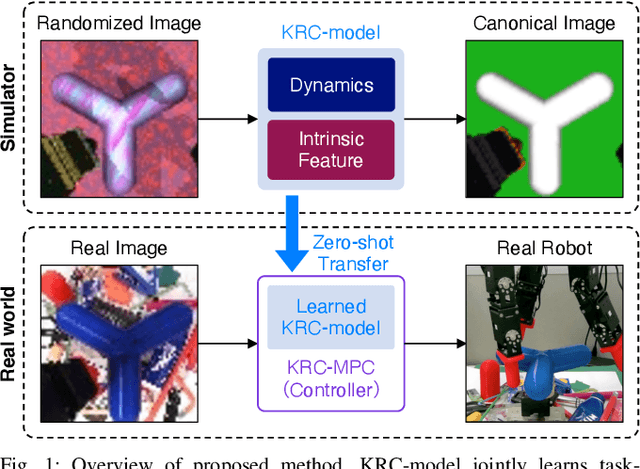
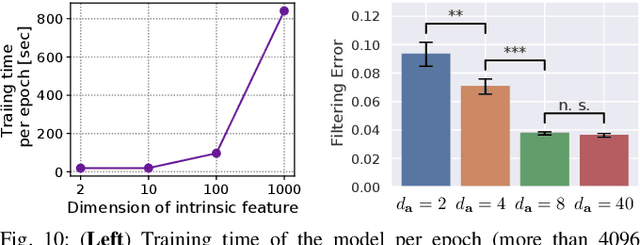
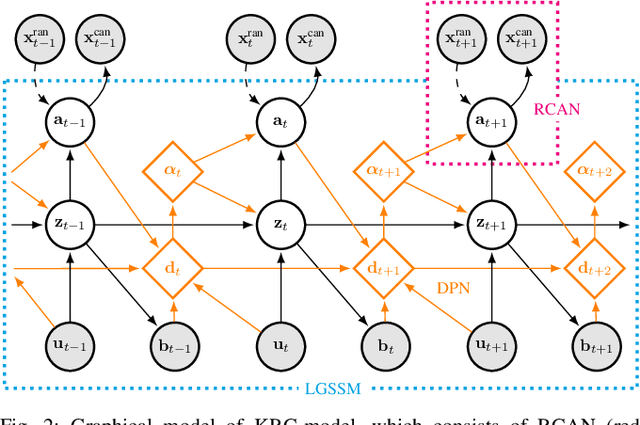
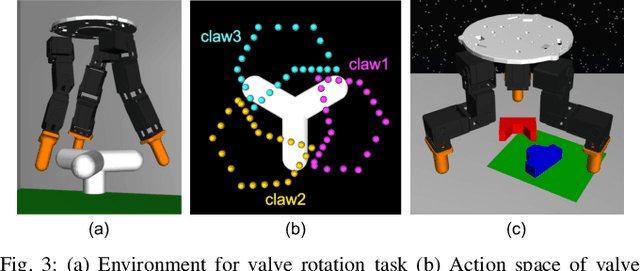
Many works have recently explored Sim-to-real transferable visual model predictive control (MPC). However, such works are limited to one-shot transfer, where real-world data must be collected once to perform the sim-to-real transfer, which remains a significant human effort in transferring the models learned in simulations to new domains in the real world. To alleviate this problem, we first propose a novel model-learning framework called Kalman Randomized-to-Canonical Model (KRC-model). This framework is capable of extracting task-relevant intrinsic features and their dynamics from randomized images. We then propose Kalman Randomized-to-Canonical Model Predictive Control (KRC-MPC) as a zero-shot sim-to-real transferable visual MPC using KRC-model. The effectiveness of our method is evaluated through a valve rotation task by a robot hand in both simulation and the real world, and a block mating task in simulation. The experimental results show that KRC-MPC can be applied to various real domains and tasks in a zero-shot manner.