 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVERITAS: Verifier-Guided Proof Search for Zero-Shot Formal Theorem Proving
Jun 17, 2026LLM-based formal provers often collapse rich verifier signals (syntax errors, type mismatches, partial goal progress) into a binary pass/fail bit. We present VERITAS, a zero-shot framework that routes every verifier signal back into proof search through a two-phase protocol: Best-of-N sampling first, then a critic-guided MCTS pass that ingests Phase 1 failures as explicit negative examples. The protocol preserves every theorem solved by its own Phase 1 sweep, so Phase 2's additional solves are attributable to feedback-driven exploration. VERITAS reaches 40.6% on miniF2F (vs. an independently run Best-of-5 at 36.9%, Portfolio 26.2%) and 7.3% on VERITAS-CombiBench, a 55-theorem combinatorics benchmark we release on which Best-of-5 (1.8%) falls below Portfolio (3.6%), exposing that unguided sampling hurts when correct lemma names must be recovered iteratively from verifier feedback. Artifacts are available on GitHub.
Constraint-Guided Multi-Agent Decompilation for Executable Binary Recovery
Apr 27, 2026Decompilation -- recovering source code from compiled binaries -- is essential for security analysis, malware reverse engineering, and legacy software maintenance. However, existing decompilers produce code that often fails to compile or execute correctly, limiting their practical utility. We present a multi-agent framework that transforms decompiled code into re-executable source through Multi-level Constraint-Guided Decompilation (MCGD). Our approach employs a hierarchical validation pipeline with three constraint levels: (1) syntactic correctness via parsing, (2) compilability via GCC, and (3) behavioral equivalence via LLM-generated test cases. When validation fails, specialized LLM agents iteratively refine the code using structured error feedback. We evaluate our framework on 1,641 real-world binaries from ExeBench across three decompilers (RetDec, Ghidra, and Angr). Our framework achieves 84-97% re-executability, improving baseline decompiler output by 28-89 percentage points. In comparison with state-of-the-art LLM-based decompilation methods using the same GPT-4o backbone, our approach (84.1%) outperforms LLM4Decompile (80.3%), SK2Decompile (73.9%), and SALT4Decompile (61.8%). Our ablation study reveals that execution-based validation is critical: compile-only approaches achieve 0% behavioral correctness despite 91-99% compilation rates. The system converges efficiently, with 90%+ binaries reaching correctness within 2 iterations at an average cost of $0.03-0.05 per binary. Our results demonstrate that constraint-guided agentic refinement can bridge the gap between raw decompiler output and practically useful source code.
COMBO: Pre-Training Representations of Binary Code Using Contrastive Learning
Oct 11, 2022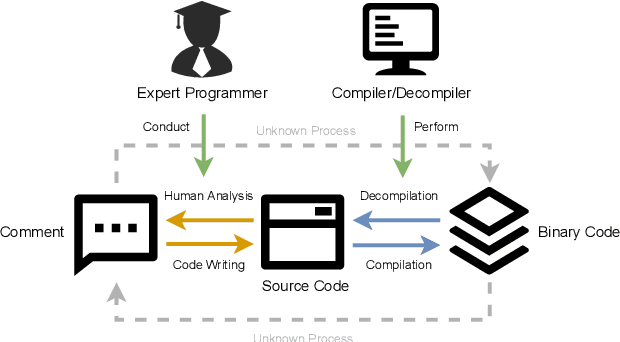
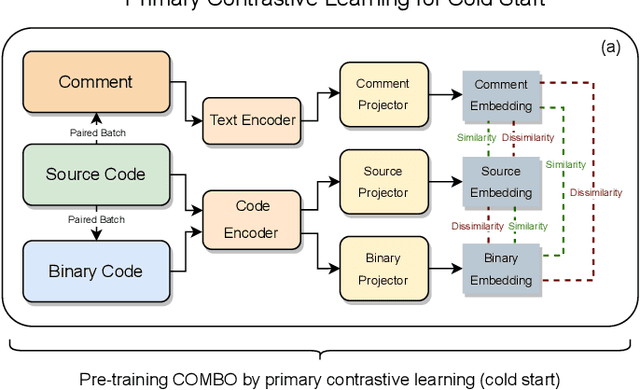
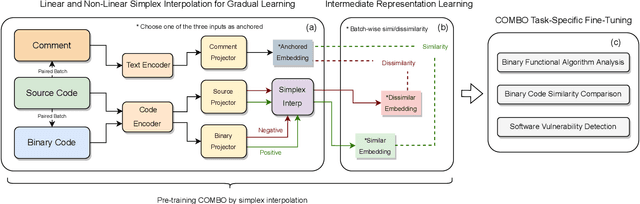
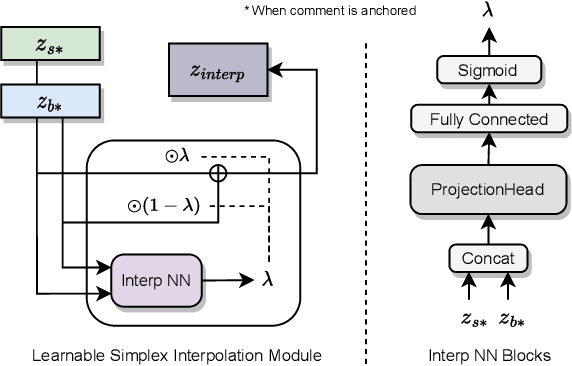
Compiled software is delivered as executable binary code. Developers write source code to express the software semantics, but the compiler converts it to a binary format that the CPU can directly execute. Therefore, binary code analysis is critical to applications in reverse engineering and computer security tasks where source code is not available. However, unlike source code and natural language that contain rich semantic information, binary code is typically difficult for human engineers to understand and analyze. While existing work uses AI models to assist source code analysis, few studies have considered binary code. In this paper, we propose a COntrastive learning Model for Binary cOde Analysis, or COMBO, that incorporates source code and comment information into binary code during representation learning. Specifically, we present three components in COMBO: (1) a primary contrastive learning method for cold-start pre-training, (2) a simplex interpolation method to incorporate source code, comments, and binary code, and (3) an intermediate representation learning algorithm to provide binary code embeddings. Finally, we evaluate the effectiveness of the pre-trained representations produced by COMBO using three indicative downstream tasks relating to binary code: algorithmic functionality classification, binary code similarity, and vulnerability detection. Our experimental results show that COMBO facilitates representation learning of binary code visualized by distribution analysis, and improves the performance on all three downstream tasks by 5.45% on average compared to state-of-the-art large-scale language representation models. To the best of our knowledge, COMBO is the first language representation model that incorporates source code, binary code, and comments into contrastive code representation learning and unifies multiple tasks for binary code analysis.