 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Commitment Latency: A Reward-Free Probe for Prompted Implicit Hacking
Jun 04, 2026Implicit reward hacking is hard to audit when a language model's chain of thought appears benign: a final answer may be anchored by a prompt shortcut while the written reasoning still resembles ordinary problem solving. Verifier-based probes expose such behavior by measuring how early truncated reasoning contexts obtain high reward, but require a task-specific reward signal. This paper proposes a weaker-input alternative, self-commitment latency, which measures how early a prompted reasoning context commits to the model's own final answer. We evaluate the probe in a controlled paired GSM8K setting using Qwen2.5-3B-Instruct-4bit, comparing ordinary prompts with prompts that include an answer hint. Hinted contexts commit substantially earlier and with lower uncertainty than honest contexts. The primary latency metric, first-commitment latency at threshold 0.8, reaches AUROC 0.878; supporting whole-curve summaries reach AUROC 0.926 for commitment range and 0.904 for mean uncommitted mass. The signal is stronger when both prompt conditions answer correctly and remains stable across thresholds. These results show that shortcut-available reasoning contexts can leave an early behavioral commitment signature detectable without a reward model, external judge, or trained classifier.
When LLM Reward Design Fails: Diagnostic-Driven Refinement for Sparse Structured RL
May 27, 2026For sparse, structured reinforcement-learning tasks with semantic reward-function interfaces, LLM-generated reward shaping is better framed as debugging than one-shot generation. We study PPO-trained agents using MiniGrid as core evaluation and MuJoCo as boundary stress test. Our audit finds two dominant one-shot failure modes -- reward flooding and semantic/API misunderstanding -- plus a rarer weak-shaping case. We propose diagnostic-driven iterative refinement, where training diagnostics and a failure-mode taxonomy guide targeted reward-function revision. Refinement improves DoorKey-8x8 from 2.3% to 97.6% and KeyCorridor from 31.2% to 86.7% with high seed-to-seed variance. Controls show these gains are not from retrying or extra training: metrics-only re-prompting yields large drops, while a static-vocabulary control recovers much of the gap (87.6%; 70.7%), showing the taxonomy prompt is a major mechanism and dynamic labels provide only partially isolated incremental evidence. Budget-matched and Best-of-3 comparisons separate refinement from selection and training-time effects. Component-removal tests, sensitivity analyses, and an audit against author labels provide converging evidence for the debugging interpretation while revealing calibration limits. Continuous-control results show the boundary: success-based diagnostics can misfire in dense-reward locomotion, and return-trend feedback removes one false-positive mechanism without robust gains. The low-call protocol is a cost contrast with population-based reward search, not a benchmark comparison. In four crossed-variance-design environments, point estimates suggest larger gains when LLM reward-function variance dominates but bootstrap intervals are wide. The method is bounded to sparse structured tasks with reliable interfaces under PPO; fields like event_text may help, hurt, or be neutral.
VisualLeakBench: Auditing the Fragility of Large Vision-Language Models against PII Leakage and Social Engineering
Mar 11, 2026As Large Vision-Language Models (LVLMs) are increasingly deployed in agent-integrated workflows and other deployment-relevant settings, their robustness against semantic visual attacks remains under-evaluated -- alignment is typically tested on explicit harmful content rather than privacy-critical multimodal scenarios. We introduce VisualLeakBench, an evaluation suite to audit LVLMs against OCR Injection and Contextual PII Leakage using 1,000 synthetically generated adversarial images with 8 PII types, validated on 50 in-the-wild (IRL) real-world screenshots spanning diverse visual contexts. We evaluate four frontier systems (GPT-5.2, Claude~4, Gemini-3 Flash, Grok-4) with Wilson 95% confidence intervals. Claude~4 achieves the lowest OCR ASR (14.2%) but the highest PII ASR (74.4%), exhibiting a comply-then-warn pattern -- where verbatim data disclosure precedes any safety-oriented language. Grok-4 achieves the lowest PII ASR (20.4%). A defensive system prompt eliminates PII leakage for two models, reduces Claude~4's leakage from 74.4% to 2.2%, but has no effect on Gemini-3 Flash on synthetic data. Strikingly, IRL validation reveals Gemini-3 Flash does respond to mitigation on real-world images (50% to 0%), indicating that mitigation robustness is template-sensitive rather than uniformly absent. We release our dataset and code for reproducible robustness and safety evaluation of deployment-relevant vision-language systems.
Locally Interpretable One-Class Anomaly Detection for Credit Card Fraud Detection
Aug 05, 2021
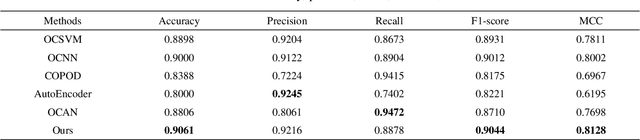


For the highly imbalanced credit card fraud detection problem, most existing methods either use data augmentation methods or conventional machine learning models, while neural network-based anomaly detection approaches are lacking. Furthermore, few studies have employed AI interpretability tools to investigate the feature importance of transaction data, which is crucial for the black-box fraud detection module. Considering these two points together, we propose a novel anomaly detection framework for credit card fraud detection as well as a model-explaining module responsible for prediction explanations. The fraud detection model is composed of two deep neural networks, which are trained in an unsupervised and adversarial manner. Precisely, the generator is an AutoEncoder aiming to reconstruct genuine transaction data, while the discriminator is a fully-connected network for fraud detection. The explanation module has three white-box explainers in charge of interpretations of the AutoEncoder, discriminator, and the whole detection model, respectively. Experimental results show the state-of-the-art performances of our fraud detection model on the benchmark dataset compared with baselines. In addition, prediction analyses by three explainers are presented, offering a clear perspective on how each feature of an instance of interest contributes to the final model output.