 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoSHAP: A Distributional Framework and Robust Metric for Stable Feature Attribution
May 14, 2026Feature attribution analysis is critical for interpreting machine learning models and supporting reliable data-driven decisions. However, feature attribution measures often exhibit stochastic variation: different train--test splits, random seeds, or model-fitting procedures can produce substantially different attribution values and feature rankings. This paper proposes a framework for incorporating stochastic nature of feature attribution and a robust attribution metric, RoSHAP, for stable feature ranking based on the SHAP metric. The proposed framework models the distribution of feature attribution scores and estimates it through bootstrap resampling and kernel density estimation. We show that, under mild regularity conditions, the aggregated feature attribution score is asymptotically Gaussian, which greatly reduces the computational cost of distribution estimation. The RoSHAP summarizes the distribution of SHAP into a robust feature-ranking criterion that simultaneously rewards features that are active, strong, and stable. Through simulations and real-data experiments, the proposed framework and RoSHAP outperform standard single-run attribution measures in identifying signal features. In addition, models built using RoSHAP-selected features achieve predictive performance comparable to full-feature models while using substantially fewer predictors. The proposed RoSHAP approach improves the stability and interpretability of machine learning models, enabling reliable and consistent insights for analysis.
Robust Flow-based Conformal Inference (FCI) with Statistical Guarantee
May 22, 2022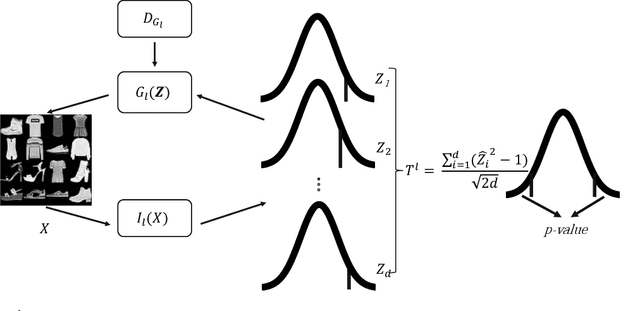
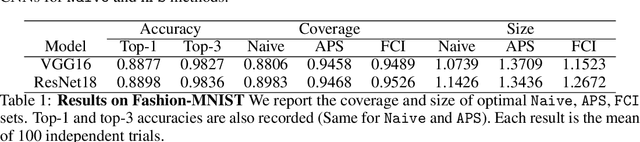
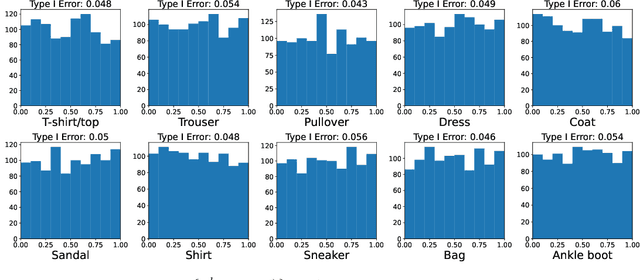

Conformal prediction aims to determine precise levels of confidence in predictions for new objects using past experience. However, the commonly used exchangeable assumptions between the training data and testing data limit its usage in dealing with contaminated testing sets. In this paper, we develop a series of conformal inference methods, including building predictive sets and inferring outliers for complex and high-dimensional data. We leverage ideas from adversarial flow to transfer the input data to a random vector with known distributions, which enable us to construct a non-conformity score for uncertainty quantification. We can further learn the distribution of input data in each class directly through the learned transformation. Therefore, our approach is applicable and more robust when the test data is contaminated. We evaluate our method, robust flow-based conformal inference, on benchmark datasets. We find that it produces effective prediction sets and accurate outlier detection and is more powerful relative to competing approaches.