 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCT: Perspective Cue Training Framework for Multi-Camera BEV Segmentation
Mar 19, 2024



Generating annotations for bird's-eye-view (BEV) segmentation presents significant challenges due to the scenes' complexity and the high manual annotation cost. In this work, we address these challenges by leveraging the abundance of unlabeled data available. We propose the Perspective Cue Training (PCT) framework, a novel training framework that utilizes pseudo-labels generated from unlabeled perspective images using publicly available semantic segmentation models trained on large street-view datasets. PCT applies a perspective view task head to the image encoder shared with the BEV segmentation head, effectively utilizing the unlabeled data to be trained with the generated pseudo-labels. Since image encoders are present in nearly all camera-based BEV segmentation architectures, PCT is flexible and applicable to various existing BEV architectures. PCT can be applied to various settings where unlabeled data is available. In this paper, we applied PCT for semi-supervised learning (SSL) and unsupervised domain adaptation (UDA). Additionally, we introduce strong input perturbation through Camera Dropout (CamDrop) and feature perturbation via BEV Feature Dropout (BFD), which are crucial for enhancing SSL capabilities using our teacher-student framework. Our comprehensive approach is simple and flexible but yields significant improvements over various baselines for SSL and UDA, achieving competitive performances even against the current state-of-the-art.
Lite-HRNet Plus: Fast and Accurate Facial Landmark Detection
Aug 23, 2023



Facial landmark detection is an essential technology for driver status tracking and has been in demand for real-time estimations. As a landmark coordinate prediction, heatmap-based methods are known to achieve a high accuracy, and Lite-HRNet can achieve a fast estimation. However, with Lite-HRNet, the problem of a heavy computational cost of the fusion block, which connects feature maps with different resolutions, has yet to be solved. In addition, the strong output module used in HRNetV2 is not applied to Lite-HRNet. Given these problems, we propose a novel architecture called Lite-HRNet Plus. Lite-HRNet Plus achieves two improvements: a novel fusion block based on a channel attention and a novel output module with less computational intensity using multi-resolution feature maps. Through experiments conducted on two facial landmark datasets, we confirmed that Lite-HRNet Plus further improved the accuracy in comparison with conventional methods, and achieved a state-of-the-art accuracy with a computational complexity with the range of 10M FLOPs.
Geometry-Aware Unsupervised Domain Adaptation for Stereo Matching
Mar 26, 2021
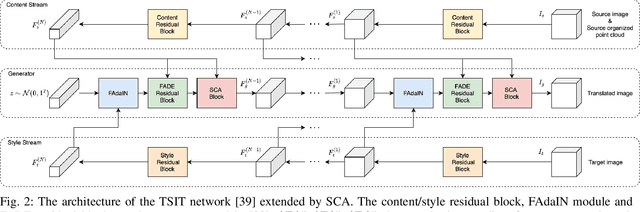
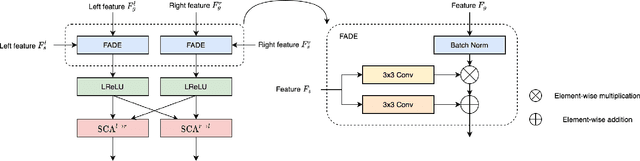
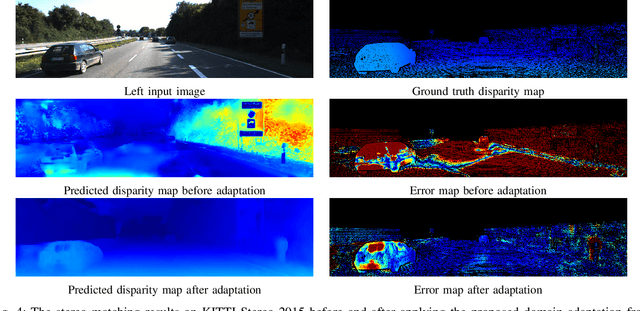
Recently proposed DNN-based stereo matching methods that learn priors directly from data are known to suffer a drastic drop in accuracy in new environments. Although supervised approaches with ground truth disparity maps often work well, collecting them in each deployment environment is cumbersome and costly. For this reason, many unsupervised domain adaptation methods based on image-to-image translation have been proposed, but these methods do not preserve the geometric structure of a stereo image pair because the image-to-image translation is applied to each view separately. To address this problem, in this paper, we propose an attention mechanism that aggregates features in the left and right views, called Stereoscopic Cross Attention (SCA). Incorporating SCA to an image-to-image translation network makes it possible to preserve the geometric structure of a stereo image pair in the process of the image-to-image translation. We empirically demonstrate the effectiveness of the proposed unsupervised domain adaptation based on the image-to-image translation with SCA.
Visualizing Color-wise Saliency of Black-Box Image Classification Models
Oct 06, 2020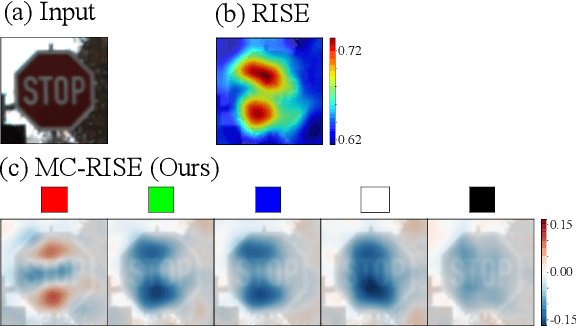
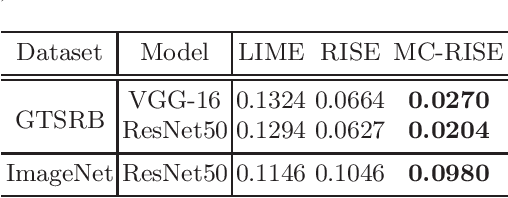
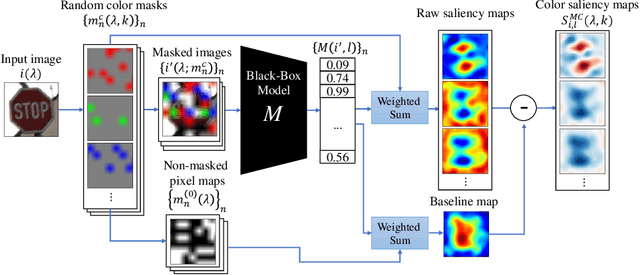
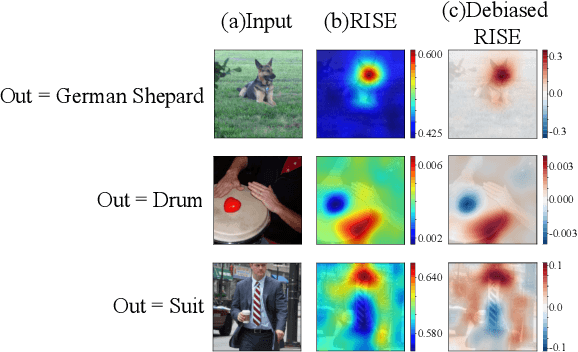
Image classification based on machine learning is being commonly used. However, a classification result given by an advanced method, including deep learning, is often hard to interpret. This problem of interpretability is one of the major obstacles in deploying a trained model in safety-critical systems. Several techniques have been proposed to address this problem; one of which is RISE, which explains a classification result by a heatmap, called a saliency map, which explains the significance of each pixel. We propose MC-RISE (Multi-Color RISE), which is an enhancement of RISE to take color information into account in an explanation. Our method not only shows the saliency of each pixel in a given image as the original RISE does, but the significance of color components of each pixel; a saliency map with color information is useful especially in the domain where the color information matters (e.g., traffic-sign recognition). We implemented MC-RISE and evaluate them using two datasets (GTSRB and ImageNet) to demonstrate the effectiveness of our methods in comparison with existing techniques for interpreting image classification results.
Team O2AS at the World Robot Summit 2018: An Approach to Robotic Kitting and Assembly Tasks using General Purpose Grippers and Tools
Mar 05, 2020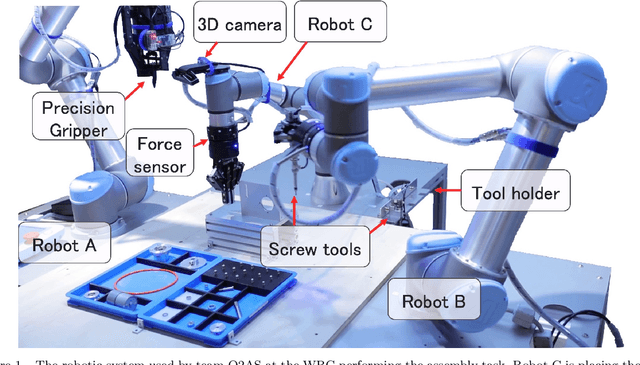
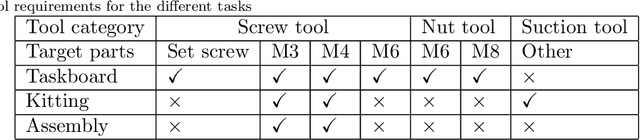
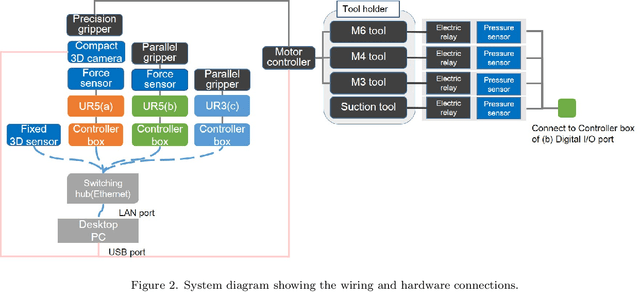

We propose a versatile robotic system for kitting and assembly tasks which uses no jigs or commercial tool changers. Instead of specialized end effectors, it uses its two-finger grippers to grasp and hold tools to perform subtasks such as screwing and suctioning. A third gripper is used as a precision picking and centering tool, and uses in-built passive compliance to compensate for small position errors and uncertainty. A novel grasp point detection for bin picking is described for the kitting task, using a single depth map. Using the proposed system we competed in the Assembly Challenge of the Industrial Robotics Category of the World Robot Challenge at the World Robot Summit 2018, obtaining 4th place and the SICE award for lean design and versatile tool use. We show the effectiveness of our approach through experiments performed during the competition.
Real-Time 6D Object Pose Estimation on CPU
Nov 21, 2018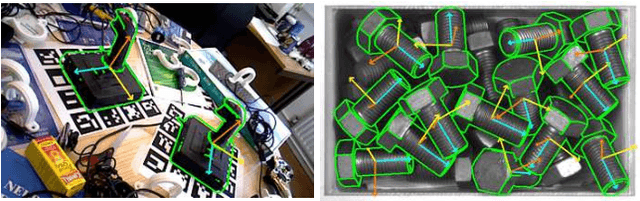
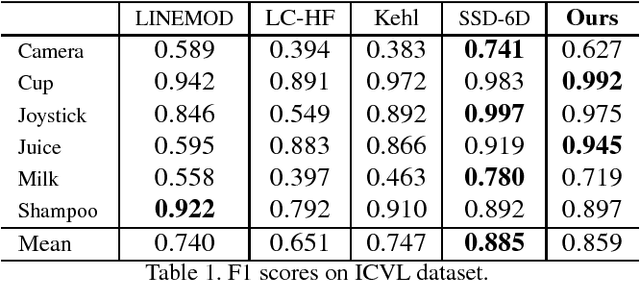
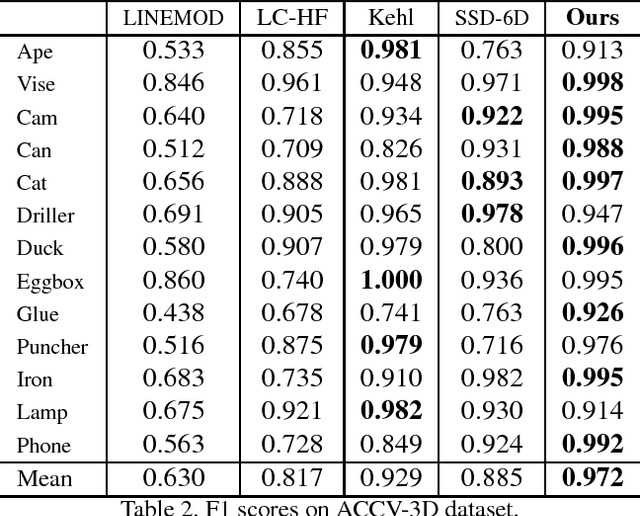
We propose a fast and accurate 6D object pose estimation from a RGB-D image. Our proposed method is template matching based and consists of three main technical components, PCOF-MOD (multimodal PCOF), balanced pose tree (BPT) and optimum memory rearrangement for a coarse-to-fine search. Our model templates on densely sampled viewpoints and PCOF-MOD which explicitly handles a certain range of 3D object pose improve the robustness against background clutters. BPT which is an efficient tree-based data structures for a large number of templates and template matching on rearranged feature maps where nearby features are linearly aligned accelerate the pose estimation. The experimental evaluation on tabletop and bin-picking dataset showed that our method achieved higher accuracy and faster speed in comparison with state-of-the-art techniques including recent CNN based approaches. Moreover, our model templates can be trained only from 3D CAD in a few minutes and the pose estimation run in near real-time (23 fps) on CPU. These features are suitable for any real applications.