 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Hierarchical Modelling for Fine-Grained Sketch Based Image Retrieval
Aug 11, 2020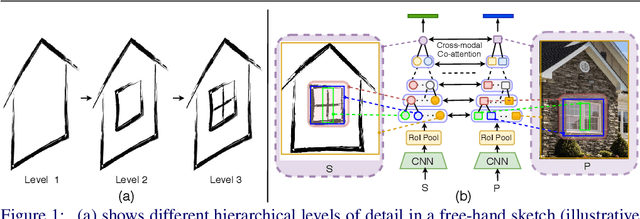
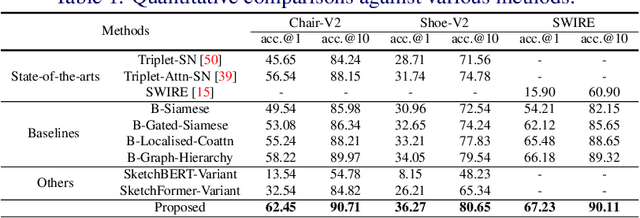
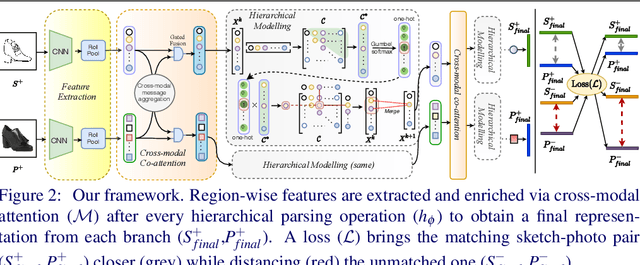
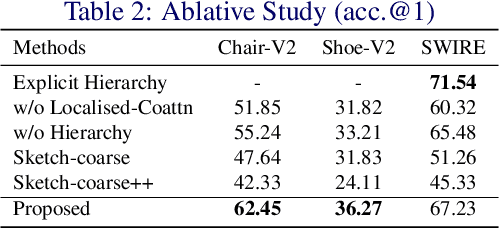
Sketch as an image search query is an ideal alternative to text in capturing the fine-grained visual details. Prior successes on fine-grained sketch-based image retrieval (FG-SBIR) have demonstrated the importance of tackling the unique traits of sketches as opposed to photos, e.g., temporal vs. static, strokes vs. pixels, and abstract vs. pixel-perfect. In this paper, we study a further trait of sketches that has been overlooked to date, that is, they are hierarchical in terms of the levels of detail -- a person typically sketches up to various extents of detail to depict an object. This hierarchical structure is often visually distinct. In this paper, we design a novel network that is capable of cultivating sketch-specific hierarchies and exploiting them to match sketch with photo at corresponding hierarchical levels. In particular, features from a sketch and a photo are enriched using cross-modal co-attention, coupled with hierarchical node fusion at every level to form a better embedding space to conduct retrieval. Experiments on common benchmarks show our method to outperform state-of-the-arts by a significant margin.
BézierSketch: A generative model for scalable vector sketches
Jul 14, 2020
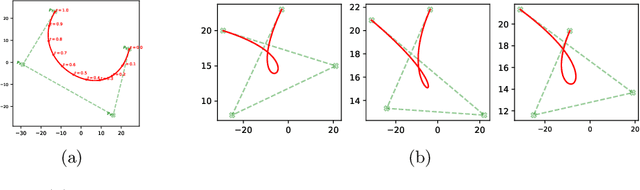
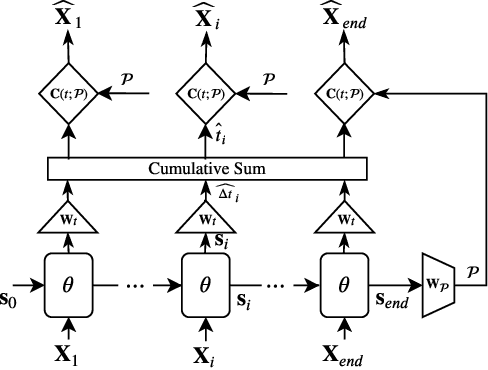
The study of neural generative models of human sketches is a fascinating contemporary modeling problem due to the links between sketch image generation and the human drawing process. The landmark SketchRNN provided breakthrough by sequentially generating sketches as a sequence of waypoints. However this leads to low-resolution image generation, and failure to model long sketches. In this paper we present B\'ezierSketch, a novel generative model for fully vector sketches that are automatically scalable and high-resolution. To this end, we first introduce a novel inverse graphics approach to stroke embedding that trains an encoder to embed each stroke to its best fit B\'ezier curve. This enables us to treat sketches as short sequences of paramaterized strokes and thus train a recurrent sketch generator with greater capacity for longer sketches, while producing scalable high-resolution results. We report qualitative and quantitative results on the Quick, Draw! benchmark.
Learning to Generate Novel Domains for Domain Generalization
Jul 07, 2020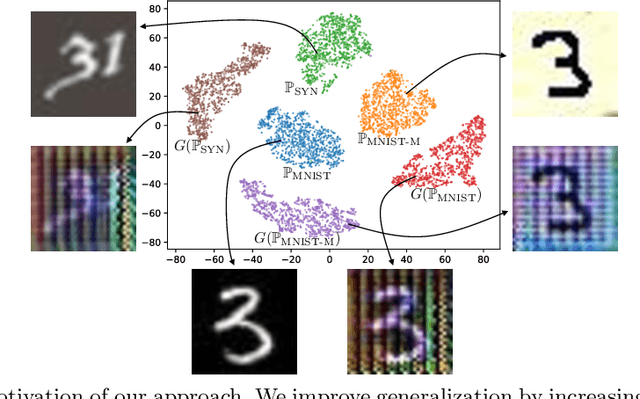
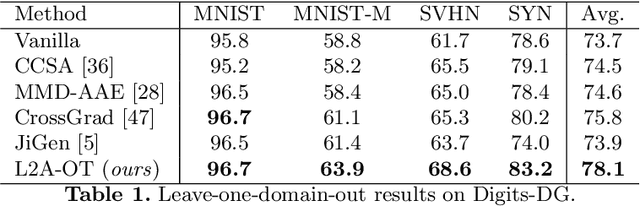

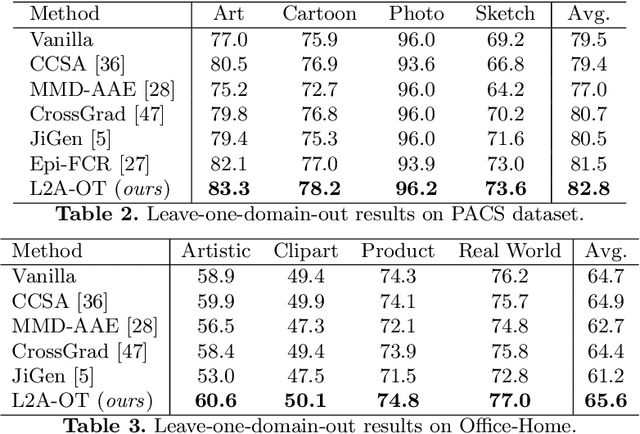
This paper focuses on domain generalization (DG), the task of learning from multiple source domains a model that generalizes well to unseen domains. A main challenge for DG is that the available source domains often exhibit limited diversity, hampering the model's ability to learn to generalize. We therefore employ a data generator to synthesize data from pseudo-novel domains to augment the source domains. This explicitly increases the diversity of available training domains and leads to a more generalizable model. To train the generator, we model the distribution divergence between source and synthesized pseudo-novel domains using optimal transport, and maximize the divergence. To ensure that semantics are preserved in the synthesized data, we further impose cycle-consistency and classification losses on the generator. Our method, L2A-OT (Learning to Augment by Optimal Transport) outperforms current state-of-the-art DG methods on four benchmark datasets.
Augmented Sliced Wasserstein Distances
Jun 17, 2020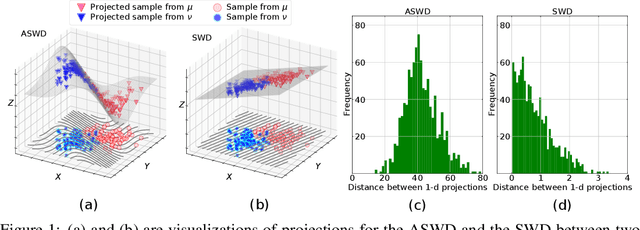
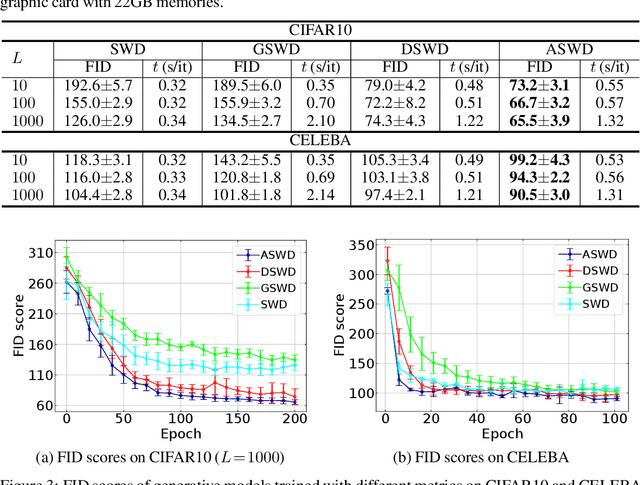
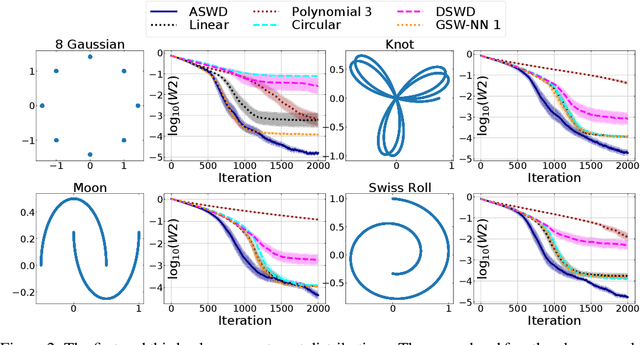
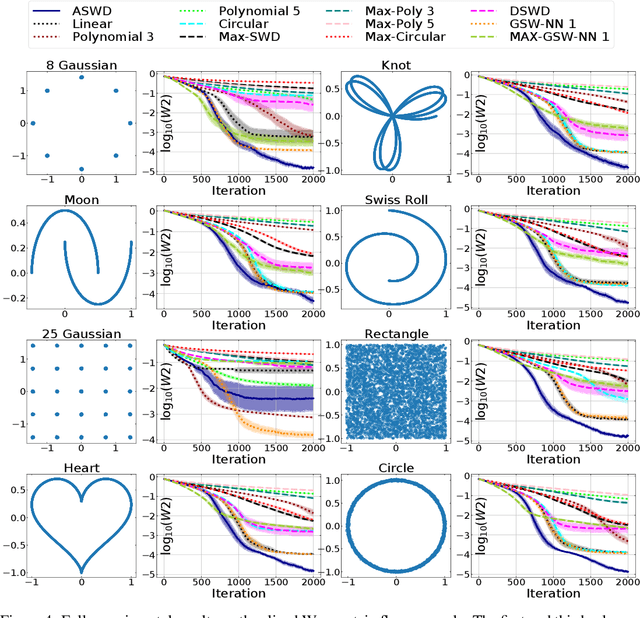
While theoretically appealing, the application of the Wasserstein distance to large-scale machine learning problems has been hampered by its prohibitive computational cost. The sliced Wasserstein distance and its variants improve the computational efficiency through random projection, yet they suffer from low projection efficiency because the majority of projections result in trivially small values. In this work, we propose a new family of distance metrics, called augmented sliced Wasserstein distances (ASWDs), constructed by first mapping samples to higher-dimensional hypersurfaces parameterized by neural networks. It is derived from a key observation that (random) linear projections of samples residing on these hypersurfaces would translate to much more flexible projections in the original sample space, so they can capture complex structures of the data distribution. We show that the hypersurfaces can be optimized by gradient ascent efficiently. We provide the condition under which the ASWD is a valid metric and show that this can be obtained by an injective neural network architecture. Numerical results demonstrate that the ASWD significantly outperforms other Wasserstein variants for both synthetic and real-world problems.
Flexible Dataset Distillation: Learn Labels Instead of Images
Jun 15, 2020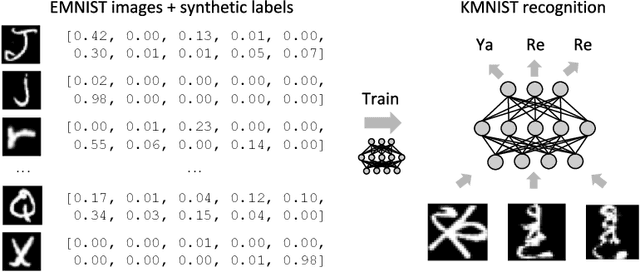
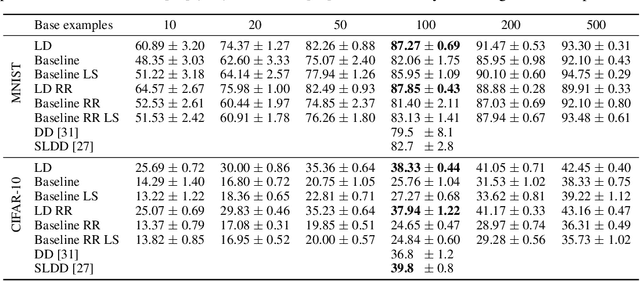
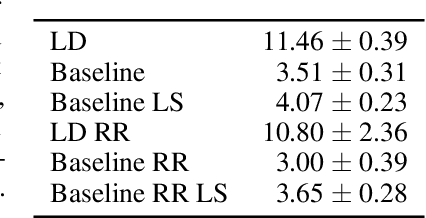
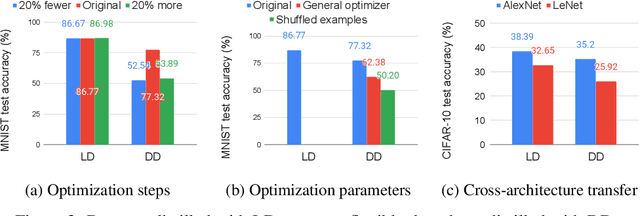
We study the problem of dataset distillation - creating a small set of synthetic examples capable of training a good model. In particular, we study the problem of label distillation - creating synthetic labels for a small set of real images, and show it to be more effective than the prior image-based approach to dataset distillation. Interestingly, label distillation can be applied across datasets, for example enabling learning Japanese character recognition by training only on synthetically labeled English letters. Methodologically, we introduce a more robust and flexible meta-learning algorithm for distillation, as well as an effective first-order strategy based on convex optimization layers. Distilling labels with our new algorithm leads to improved results over prior image-based distillation. More importantly, it leads to clear improvements in flexibility of the distilled dataset in terms of compatibility with off-the-shelf optimizers and diverse neural architectures.
Sequential Learning for Domain Generalization
Apr 03, 2020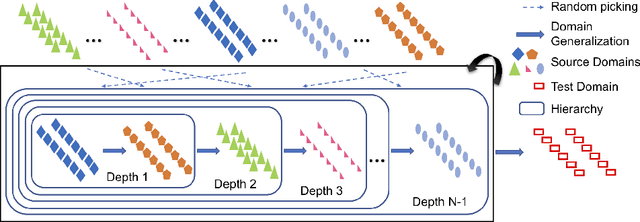


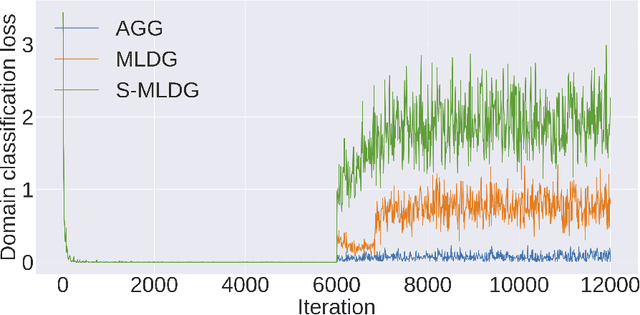
In this paper we propose a sequential learning framework for Domain Generalization (DG), the problem of training a model that is robust to domain shift by design. Various DG approaches have been proposed with different motivating intuitions, but they typically optimize for a single step of domain generalization -- training on one set of domains and generalizing to one other. Our sequential learning is inspired by the idea lifelong learning, where accumulated experience means that learning the $n^{th}$ thing becomes easier than the $1^{st}$ thing. In DG this means encountering a sequence of domains and at each step training to maximise performance on the next domain. The performance at domain $n$ then depends on the previous $n-1$ learning problems. Thus backpropagating through the sequence means optimizing performance not just for the next domain, but all following domains. Training on all such sequences of domains provides dramatically more `practice' for a base DG learner compared to existing approaches, thus improving performance on a true testing domain. This strategy can be instantiated for different base DG algorithms, but we focus on its application to the recently proposed Meta-Learning Domain generalization (MLDG). We show that for MLDG it leads to a simple to implement and fast algorithm that provides consistent performance improvement on a variety of DG benchmarks.
DADA: Differentiable Automatic Data Augmentation
Mar 28, 2020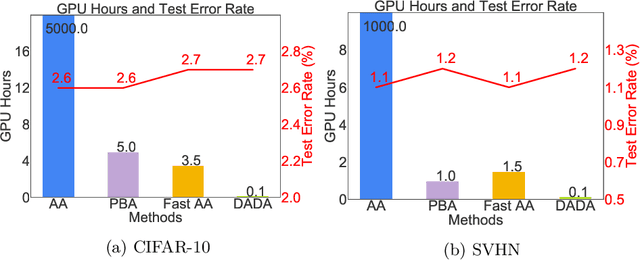

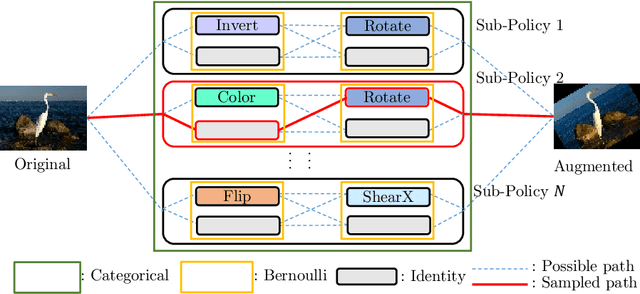
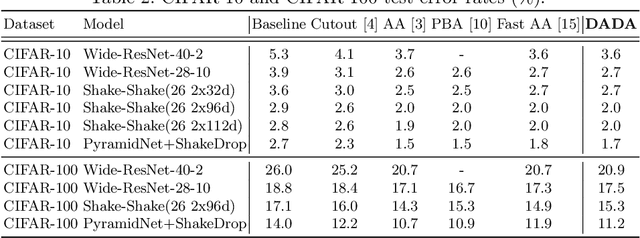
Data augmentation (DA) techniques aim to increase data variability, and thus train deep networks with better generalisation. The pioneering AutoAugment automated the search for optimal DA policies with reinforcement learning. However, AutoAugment is extremely computationally expensive, limiting its wide applicability. Followup work such as PBA and Fast AutoAugment improved efficiency, but optimization speed remains a bottleneck. In this paper, we propose Differentiable Automatic Data Augmentation (DADA) which dramatically reduces the cost. DADA relaxes the discrete DA policy selection to a differentiable optimization problem via Gumbel-Softmax. In addition, we introduce an unbiased gradient estimator, RELAX, leading to an efficient and effective one-pass optimization strategy to learn an efficient and accurate DA policy. We conduct extensive experiments on CIFAR-10, CIFAR-100, SVHN, and ImageNet datasets. Furthermore, we demonstrate the value of Auto DA in pre-training for downstream detection problems. Results show our DADA is at least one order of magnitude faster than the state-of-the-art while achieving very comparable accuracy.
Domain Adaptive Ensemble Learning
Mar 16, 2020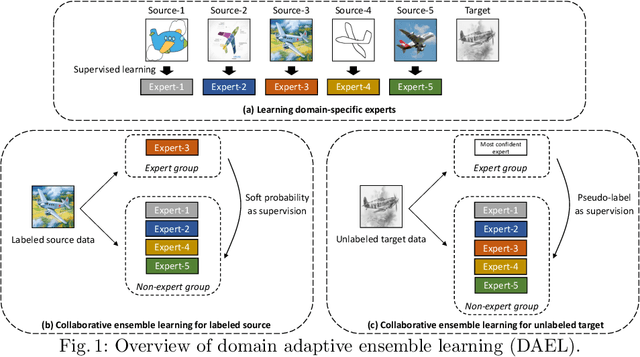
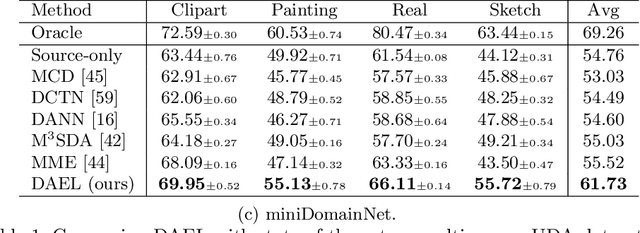
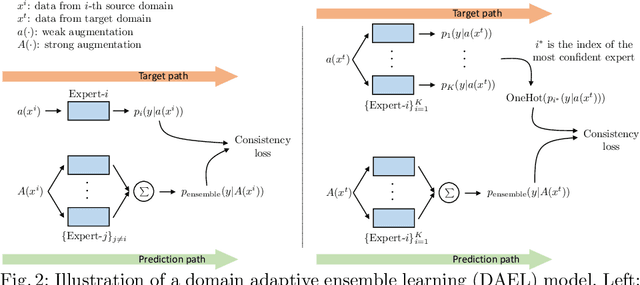
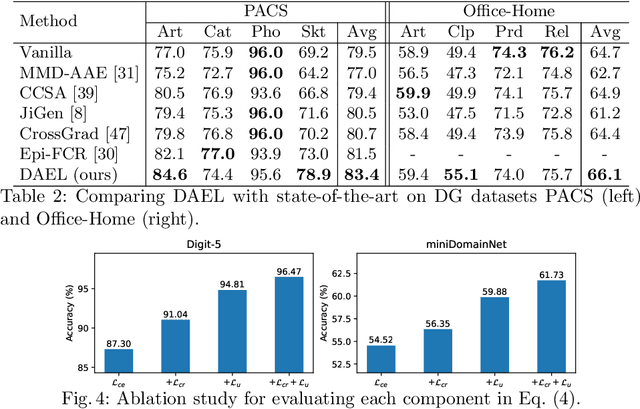
The problem of generalizing deep neural networks from multiple source domains to a target one is studied under two settings: When unlabeled target data is available, it is a multi-source unsupervised domain adaptation (UDA) problem, otherwise a domain generalization (DG) problem. We propose a unified framework termed domain adaptive ensemble learning (DAEL) to address both problems. A DAEL model is composed of a CNN feature extractor shared across domains and multiple classifier heads each trained to specialize in a particular source domain. Each such classifier is an expert to its own domain and a non-expert to others. DAEL aims to learn these experts collaboratively so that when forming an ensemble, they can leverage complementary information from each other to be more effective for an unseen target domain. To this end, each source domain is used in turn as a pseudo-target-domain with its own expert providing supervision signal to the ensemble of non-experts learned from the other sources. For unlabeled target data under the UDA setting where real expert does not exist, DAEL uses pseudo-label to supervise the ensemble learning. Extensive experiments on three multi-source UDA datasets and two DG datasets show that DAEL improves the state-of-the-art on both problems, often by significant margins. The code is released at \url{https://github.com/KaiyangZhou/Dassl.pytorch}.
Deep Domain-Adversarial Image Generation for Domain Generalisation
Mar 12, 2020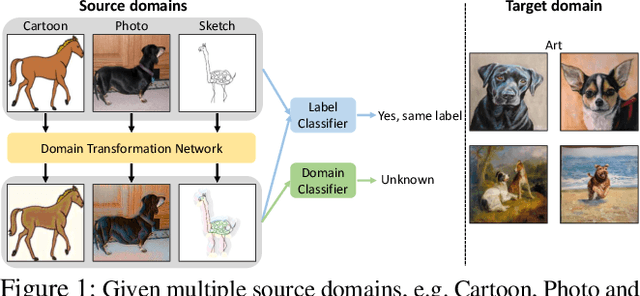
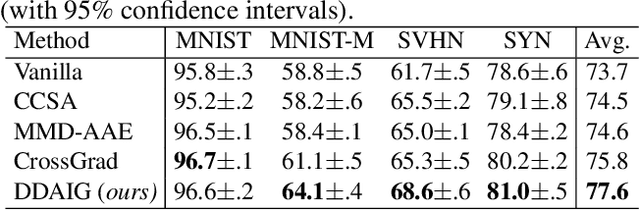
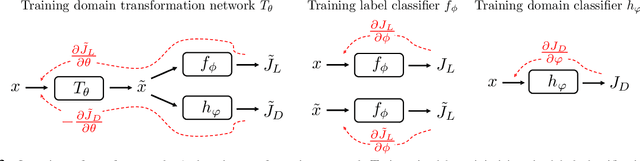
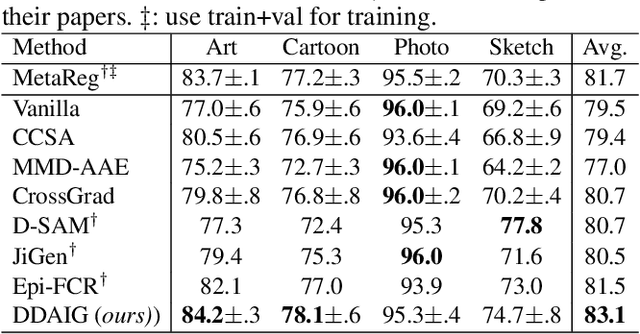
Machine learning models typically suffer from the domain shift problem when trained on a source dataset and evaluated on a target dataset of different distribution. To overcome this problem, domain generalisation (DG) methods aim to leverage data from multiple source domains so that a trained model can generalise to unseen domains. In this paper, we propose a novel DG approach based on \emph{Deep Domain-Adversarial Image Generation} (DDAIG). Specifically, DDAIG consists of three components, namely a label classifier, a domain classifier and a domain transformation network (DoTNet). The goal for DoTNet is to map the source training data to unseen domains. This is achieved by having a learning objective formulated to ensure that the generated data can be correctly classified by the label classifier while fooling the domain classifier. By augmenting the source training data with the generated unseen domain data, we can make the label classifier more robust to unknown domain changes. Extensive experiments on four DG datasets demonstrate the effectiveness of our approach.
Online Meta-Critic Learning for Off-Policy Actor-Critic Methods
Mar 11, 2020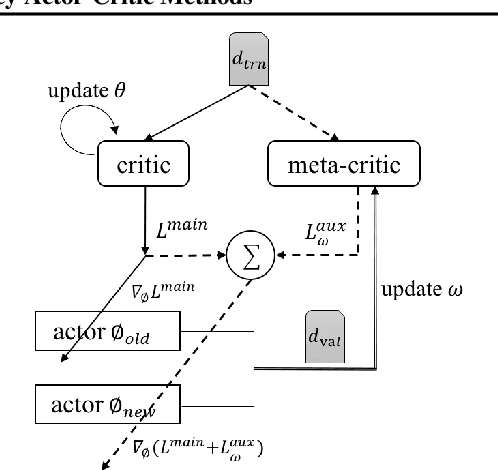
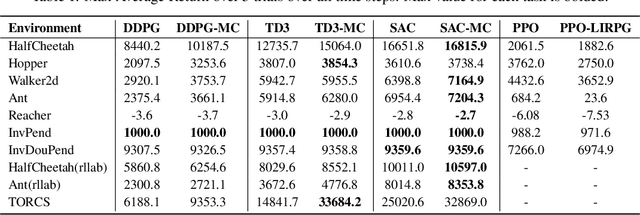
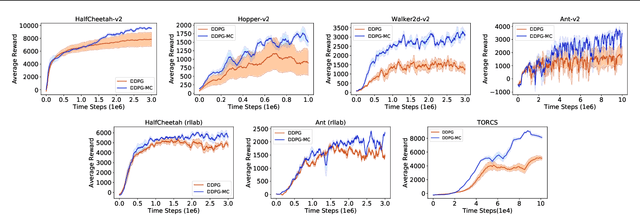

Off-Policy Actor-Critic (Off-PAC) methods have proven successful in a variety of continuous control tasks. Normally, the critic's action-value function is updated using temporal-difference, and the critic in turn provides a loss for the actor that trains it to take actions with higher expected return. In this paper, we introduce a novel and flexible meta-critic that observes the learning process and meta-learns an additional loss for the actor that accelerates and improves actor-critic learning. Compared to the vanilla critic, the meta-critic network is explicitly trained to accelerate the learning process; and compared to existing meta-learning algorithms, meta-critic is rapidly learned online for a single task, rather than slowly over a family of tasks. Crucially, our meta-critic framework is designed for off-policy based learners, which currently provide state-of-the-art reinforcement learning sample efficiency. We demonstrate that online meta-critic learning leads to improvements in avariety of continuous control environments when combined with contemporary Off-PAC methods DDPG, TD3 and the state-of-the-art SAC.