 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXAONE 4.5 Technical Report
Apr 09, 2026This technical report introduces EXAONE 4.5, the first open-weight vision language model released by LG AI Research. EXAONE 4.5 is architected by integrating a dedicated visual encoder into the existing EXAONE 4.0 framework, enabling native multimodal pretraining over both visual and textual modalities. The model is trained on large-scale data with careful curation, particularly emphasizing document-centric corpora that align with LG's strategic application domains. This targeted data design enables substantial performance gains in document understanding and related tasks, while also delivering broad improvements across general language capabilities. EXAONE 4.5 extends context length up to 256K tokens, facilitating long-context reasoning and enterprise-scale use cases. Comparative evaluations demonstrate that EXAONE 4.5 achieves competitive performance in general benchmarks while outperforming state-of-the-art models of similar scale in document understanding and Korean contextual reasoning. As part of LG's ongoing effort toward practical industrial deployment, EXAONE 4.5 is designed to be continuously extended with additional domains and application scenarios to advance AI for a better life.
K-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
Trustworthy Agents for Electronic Health Records through Confidence Estimation
Aug 26, 2025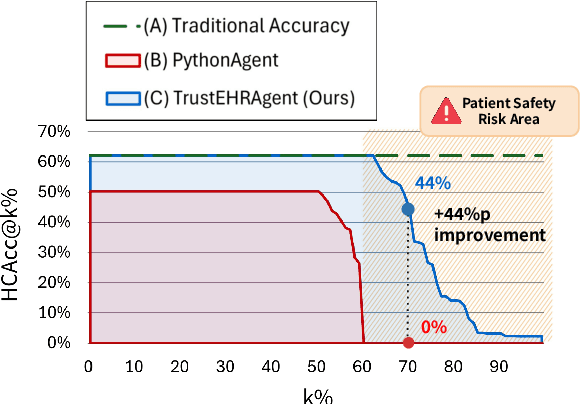
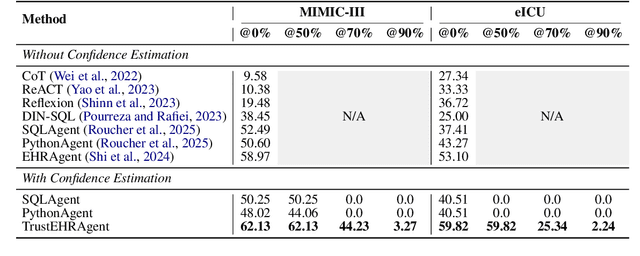
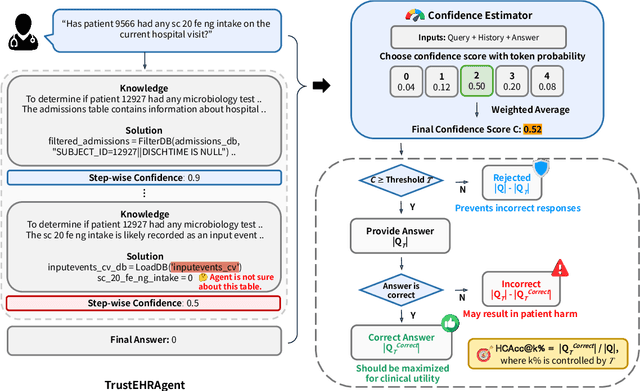
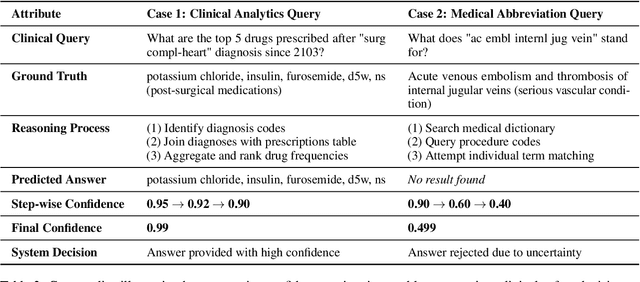
Large language models (LLMs) show promise for extracting information from Electronic Health Records (EHR) and supporting clinical decisions. However, deployment in clinical settings faces challenges due to hallucination risks. We propose Hallucination Controlled Accuracy at k% (HCAcc@k%), a novel metric quantifying the accuracy-reliability trade-off at varying confidence thresholds. We introduce TrustEHRAgent, a confidence-aware agent incorporating stepwise confidence estimation for clinical question answering. Experiments on MIMIC-III and eICU datasets show TrustEHRAgent outperforms baselines under strict reliability constraints, achieving improvements of 44.23%p and 25.34%p at HCAcc@70% while baseline methods fail at these thresholds. These results highlight limitations of traditional accuracy metrics in evaluating healthcare AI agents. Our work contributes to developing trustworthy clinical agents that deliver accurate information or transparently express uncertainty when confidence is low.
What Really Matters in Many-Shot Attacks? An Empirical Study of Long-Context Vulnerabilities in LLMs
May 26, 2025



We investigate long-context vulnerabilities in Large Language Models (LLMs) through Many-Shot Jailbreaking (MSJ). Our experiments utilize context length of up to 128K tokens. Through comprehensive analysis with various many-shot attack settings with different instruction styles, shot density, topic, and format, we reveal that context length is the primary factor determining attack effectiveness. Critically, we find that successful attacks do not require carefully crafted harmful content. Even repetitive shots or random dummy text can circumvent model safety measures, suggesting fundamental limitations in long-context processing capabilities of LLMs. The safety behavior of well-aligned models becomes increasingly inconsistent with longer contexts. These findings highlight significant safety gaps in context expansion capabilities of LLMs, emphasizing the need for new safety mechanisms.