 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Agents for Electronic Health Records through Confidence Estimation
Paper and Code
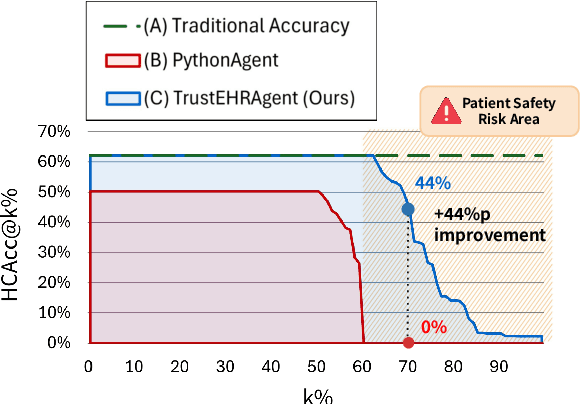
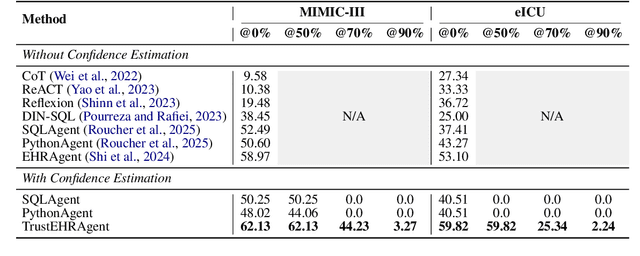
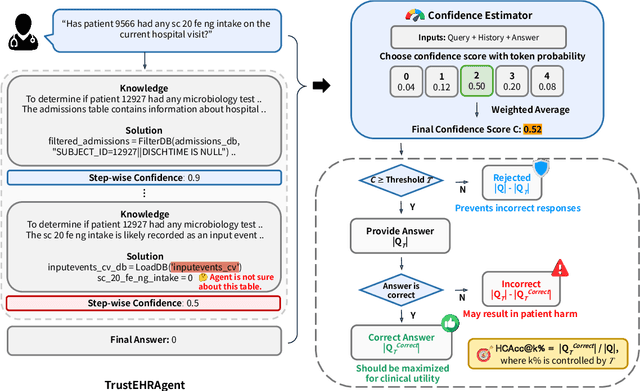
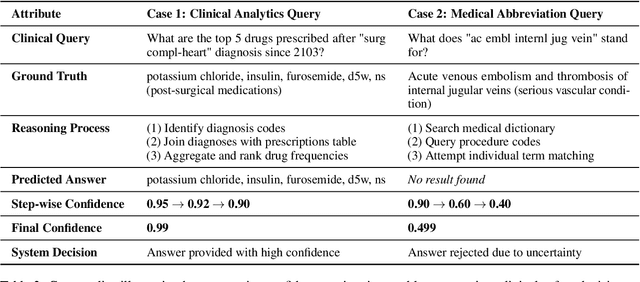
Large language models (LLMs) show promise for extracting information from Electronic Health Records (EHR) and supporting clinical decisions. However, deployment in clinical settings faces challenges due to hallucination risks. We propose Hallucination Controlled Accuracy at k% (HCAcc@k%), a novel metric quantifying the accuracy-reliability trade-off at varying confidence thresholds. We introduce TrustEHRAgent, a confidence-aware agent incorporating stepwise confidence estimation for clinical question answering. Experiments on MIMIC-III and eICU datasets show TrustEHRAgent outperforms baselines under strict reliability constraints, achieving improvements of 44.23%p and 25.34%p at HCAcc@70% while baseline methods fail at these thresholds. These results highlight limitations of traditional accuracy metrics in evaluating healthcare AI agents. Our work contributes to developing trustworthy clinical agents that deliver accurate information or transparently express uncertainty when confidence is low.