 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-TRAK: Understanding how diffusion models learn concepts through concept-level attribution
Jul 09, 2025



While diffusion models excel at image generation, their growing adoption raises critical concerns around copyright issues and model transparency. Existing attribution methods identify training examples influencing an entire image, but fall short in isolating contributions to specific elements, such as styles or objects, that matter most to stakeholders. To bridge this gap, we introduce \emph{concept-level attribution} via a novel method called \emph{Concept-TRAK}. Concept-TRAK extends influence functions with two key innovations: (1) a reformulated diffusion training loss based on diffusion posterior sampling, enabling robust, sample-specific attribution; and (2) a concept-aware reward function that emphasizes semantic relevance. We evaluate Concept-TRAK on the AbC benchmark, showing substantial improvements over prior methods. Through diverse case studies--ranging from identifying IP-protected and unsafe content to analyzing prompt engineering and compositional learning--we demonstrate how concept-level attribution yields actionable insights for responsible generative AI development and governance.
MonaCoBERT: Monotonic attention based ConvBERT for Knowledge Tracing
Aug 19, 2022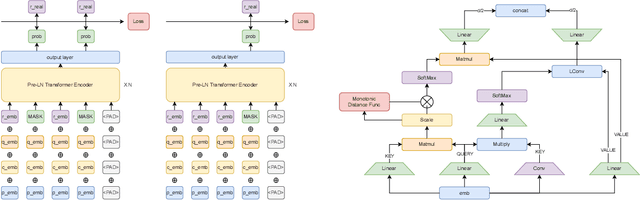
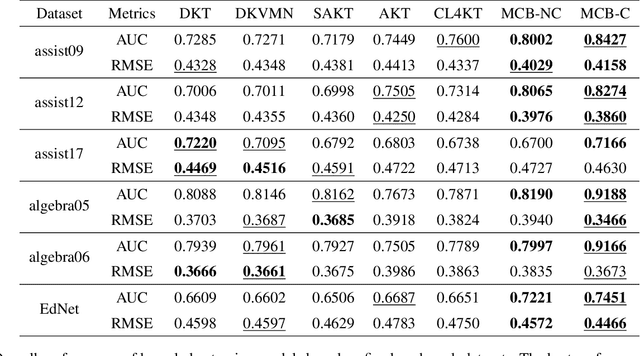
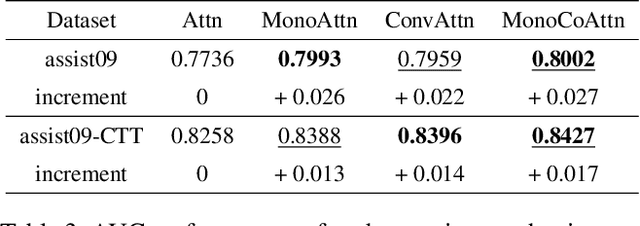
Knowledge tracing (KT) is a field of study that predicts the future performance of students based on prior performance datasets collected from educational applications such as intelligent tutoring systems, learning management systems, and online courses. Some previous studies on KT have concentrated only on the interpretability of the model, whereas others have focused on enhancing the performance. Models that consider both interpretability and the performance improvement have been insufficient. Moreover, models that focus on performance improvements have not shown an overwhelming performance compared with existing models. In this study, we propose MonaCoBERT, which achieves the best performance on most benchmark datasets and has significant interpretability. MonaCoBERT uses a BERT-based architecture with monotonic convolutional multihead attention, which reflects forgetting behavior of the students and increases the representation power of the model. We can also increase the performance and interpretability using a classical test-theory-based (CTT-based) embedding strategy that considers the difficulty of the question. To determine why MonaCoBERT achieved the best performance and interpret the results quantitatively, we conducted ablation studies and additional analyses using Grad-CAM, UMAP, and various visualization techniques. The analysis results demonstrate that both attention components complement one another and that CTT-based embedding represents information on both global and local difficulties. We also demonstrate that our model represents the relationship between concepts.