 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed collaborative anomalous sound detection by embedding sharing
Mar 25, 2024
To develop a machine sound monitoring system, a method for detecting anomalous sound is proposed. In this paper, we explore a method for multiple clients to collaboratively learn an anomalous sound detection model while keeping their raw data private from each other. In the context of industrial machine anomalous sound detection, each client possesses data from different machines or different operational states, making it challenging to learn through federated learning or split learning. In our proposed method, each client calculates embeddings using a common pre-trained model developed for sound data classification, and these calculated embeddings are aggregated on the server to perform anomalous sound detection through outlier exposure. Experiments showed that our proposed method improves the AUC of anomalous sound detection by an average of 6.8%.
Streaming Active Learning for Regression Problems Using Regression via Classification
Sep 02, 2023


One of the challenges in deploying a machine learning model is that the model's performance degrades as the operating environment changes. To maintain the performance, streaming active learning is used, in which the model is retrained by adding a newly annotated sample to the training dataset if the prediction of the sample is not certain enough. Although many streaming active learning methods have been proposed for classification, few efforts have been made for regression problems, which are often handled in the industrial field. In this paper, we propose to use the regression-via-classification framework for streaming active learning for regression. Regression-via-classification transforms regression problems into classification problems so that streaming active learning methods proposed for classification problems can be applied directly to regression problems. Experimental validation on four real data sets shows that the proposed method can perform regression with higher accuracy at the same annotation cost.
CAPTDURE: Captioned Sound Dataset of Single Sources
May 28, 2023In conventional studies on environmental sound separation and synthesis using captions, datasets consisting of multiple-source sounds with their captions were used for model training. However, when we collect the captions for multiple-source sound, it is not easy to collect detailed captions for each sound source, such as the number of sound occurrences and timbre. Therefore, it is difficult to extract only the single-source target sound by the model-training method using a conventional captioned sound dataset. In this work, we constructed a dataset with captions for a single-source sound named CAPTDURE, which can be used in various tasks such as environmental sound separation and synthesis. Our dataset consists of 1,044 sounds and 4,902 captions. We evaluated the performance of environmental sound extraction using our dataset. The experimental results show that the captions for single-source sounds are effective in extracting only the single-source target sound from the mixture sound.
Anomalous Sound Detection Based on Sound Separation
May 25, 2023This paper proposes an unsupervised anomalous sound detection method using sound separation. In factory environments, background noise and non-objective sounds obscure desired machine sounds, making it challenging to detect anomalous sounds. Therefore, using sounds not mixed with background noise or non-purpose sounds in the detection system is desirable. We compared two versions of our proposed method, one using sound separation as a pre-processing step and the other using separation-based outlier exposure that uses the error between two separated sounds. Based on the assumption that differences in separation performance between normal and anomalous sounds affect detection results, a sound separation model specific to a particular product type was used in both versions. Experimental results indicate that the proposed method improved anomalous sound detection performance for all Machine IDs, achieving a maximum improvement of 39%.
Description and Discussion on DCASE 2023 Challenge Task 2: First-Shot Unsupervised Anomalous Sound Detection for Machine Condition Monitoring
May 13, 2023



We present the task description of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2023 Challenge Task 2: "First-shot unsupervised anomalous sound detection (ASD) for machine condition monitoring". The main goal is to enable rapid deployment of ASD systems for new kinds of machines using only a few normal samples, without the need for hyperparameter tuning. In the past ASD tasks, developed methods tuned hyperparameters for each machine type, as the development and evaluation datasets had the same machine types. However, collecting normal and anomalous data as the development dataset can be infeasible in practice. In 2023 Task 2, we focus on solving first-shot problem, which is the challenge of training a model on a few machines of a completely novel machine type. Specifically, (i) each machine type has only one section, and (ii) machine types in the development and evaluation datasets are completely different. We will add challenge results and analysis of the submissions after the challenge submission deadline.
Zero-shot domain adaptation of anomalous samples for semi-supervised anomaly detection
Apr 05, 2023Semi-supervised anomaly detection~(SSAD) is a task where normal data and a limited number of anomalous data are available for training. In practical situations, SSAD methods suffer adapting to domain shifts, since anomalous data are unlikely to be available for the target domain in the training phase. To solve this problem, we propose a domain adaptation method for SSAD where no anomalous data are available for the target domain. First, we introduce a domain-adversarial network to a variational auto-encoder-based SSAD model to obtain domain-invariant latent variables. Since the decoder cannot reconstruct the original data solely from domain-invariant latent variables, we conditioned the decoder on the domain label. To compensate for the missing anomalous data of the target domain, we introduce an importance sampling-based weighted loss function that approximates the ideal loss function. Experimental results indicate that the proposed method helps adapt SSAD models to the target domain when no anomalous data are available for the target domain.
Updating Only Encoders Prevents Catastrophic Forgetting of End-to-End ASR Models
Jul 01, 2022
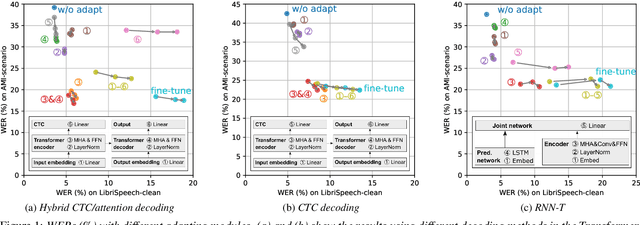
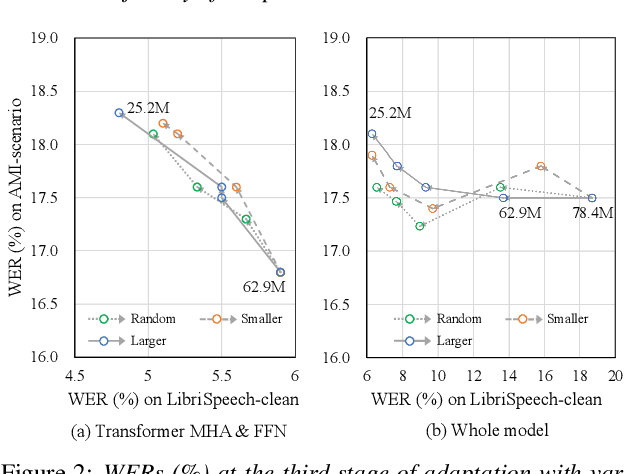
In this paper, we present an incremental domain adaptation technique to prevent catastrophic forgetting for an end-to-end automatic speech recognition (ASR) model. Conventional approaches require extra parameters of the same size as the model for optimization, and it is difficult to apply these approaches to end-to-end ASR models because they have a huge amount of parameters. To solve this problem, we first investigate which parts of end-to-end ASR models contribute to high accuracy in the target domain while preventing catastrophic forgetting. We conduct experiments on incremental domain adaptation from the LibriSpeech dataset to the AMI meeting corpus with two popular end-to-end ASR models and found that adapting only the linear layers of their encoders can prevent catastrophic forgetting. Then, on the basis of this finding, we develop an element-wise parameter selection focused on specific layers to further reduce the number of fine-tuning parameters. Experimental results show that our approach consistently prevents catastrophic forgetting compared to parameter selection from the whole model.
Description and Discussion on DCASE 2022 Challenge Task 2: Unsupervised Anomalous Sound Detection for Machine Condition Monitoring Applying Domain Generalization Techniques
Jun 13, 2022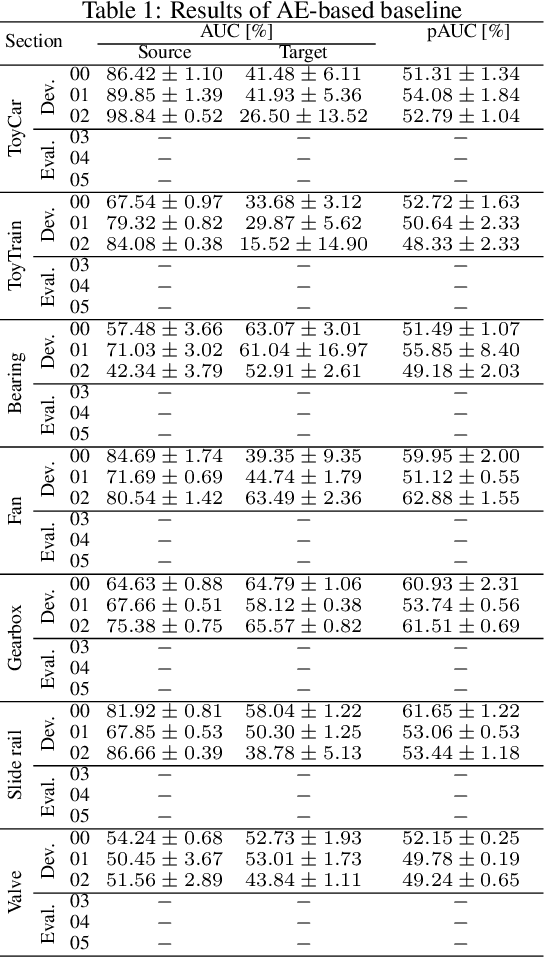
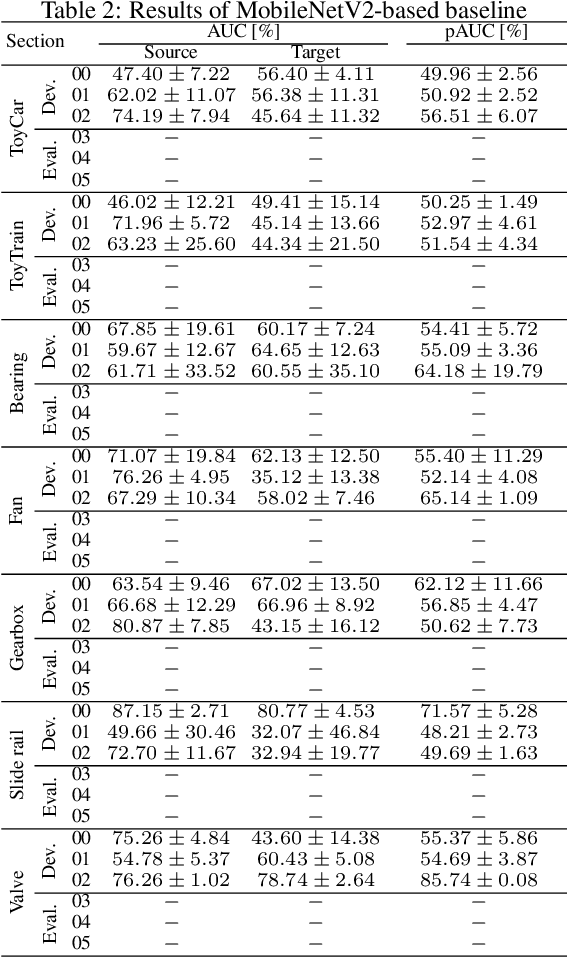
We present the task description of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2022 Challenge Task 2: "Unsupervised anomalous sound detection (ASD) for machine condition monitoring applying domain generalization techniques". Domain shifts are a critical problem for the application of ASD systems. Because domain shifts can change the acoustic characteristics of data, a model trained in a source domain performs poorly for a target domain. In DCASE 2021 Challenge Task 2, we organized an ASD task for handling domain shifts. In this task, it was assumed that the occurrences of domain shifts are known. However, in practice, the domain of each sample may not be given, and the domain shifts can occur implicitly. In 2022 Task 2, we focus on domain generalization techniques that detects anomalies regardless of the domain shifts. Specifically, the domain of each sample is not given in the test data and only one threshold is allowed for all domains. We will add challenge results and analysis of the submissions after the challenge submission deadline.
Hierarchical Conditional Variational Autoencoder Based Acoustic Anomaly Detection
Jun 11, 2022
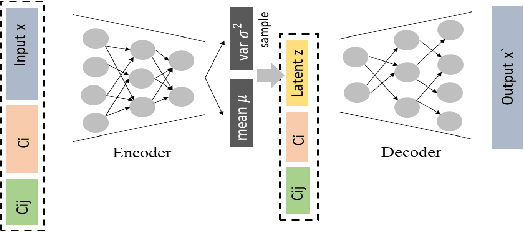
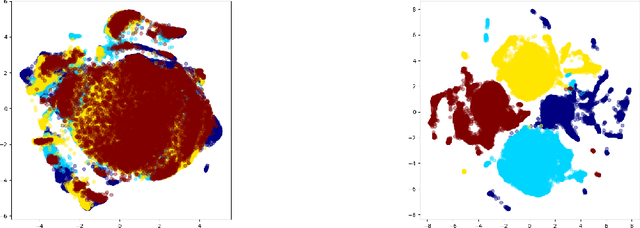
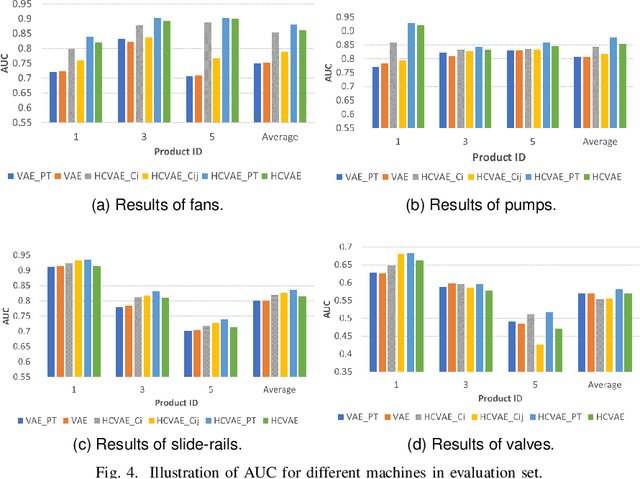
This paper aims to develop an acoustic signal-based unsupervised anomaly detection method for automatic machine monitoring. Existing approaches such as deep autoencoder (DAE), variational autoencoder (VAE), conditional variational autoencoder (CVAE) etc. have limited representation capabilities in the latent space and, hence, poor anomaly detection performance. Different models have to be trained for each different kind of machines to accurately perform the anomaly detection task. To solve this issue, we propose a new method named as hierarchical conditional variational autoencoder (HCVAE). This method utilizes available taxonomic hierarchical knowledge about industrial facility to refine the latent space representation. This knowledge helps model to improve the anomaly detection performance as well. We demonstrated the generalization capability of a single HCVAE model for different types of machines by using appropriate conditions. Additionally, to show the practicability of the proposed approach, (i) we evaluated HCVAE model on different domain and (ii) we checked the effect of partial hierarchical knowledge. Our results show that HCVAE method validates both of these points, and it outperforms the baseline system on anomaly detection task by utmost 15 % on the AUC score metric.
Online Neural Diarization of Unlimited Numbers of Speakers
Jun 06, 2022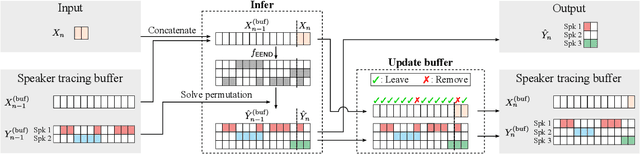
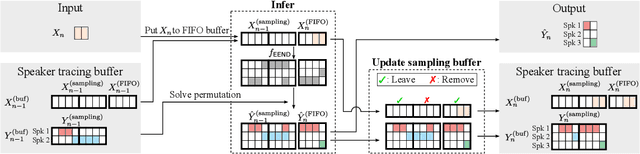
A method to perform offline and online speaker diarization for an unlimited number of speakers is described in this paper. End-to-end neural diarization (EEND) has achieved overlap-aware speaker diarization by formulating it as a multi-label classification problem. It has also been extended for a flexible number of speakers by introducing speaker-wise attractors. However, the output number of speakers of attractor-based EEND is empirically capped; it cannot deal with cases where the number of speakers appearing during inference is higher than that during training because its speaker counting is trained in a fully supervised manner. Our method, EEND-GLA, solves this problem by introducing unsupervised clustering into attractor-based EEND. In the method, the input audio is first divided into short blocks, then attractor-based diarization is performed for each block, and finally the results of each blocks are clustered on the basis of the similarity between locally-calculated attractors. While the number of output speakers is limited within each block, the total number of speakers estimated for the entire input can be higher than the limitation. To use EEND-GLA in an online manner, our method also extends the speaker-tracing buffer, which was originally proposed to enable online inference of conventional EEND. We introduces a block-wise buffer update to make the speaker-tracing buffer compatible with EEND-GLA. Finally, to improve online diarization, our method improves the buffer update method and revisits the variable chunk-size training of EEND. The experimental results demonstrate that EEND-GLA can perform speaker diarization of an unseen number of speakers in both offline and online inferences.