 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMix: Reinforcement routing for mixtures of LoRAs in LLM finetuning
Mar 10, 2026Low-rank adapters (LoRAs) are a parameter-efficient finetuning technique that injects trainable low-rank matrices into pretrained models to adapt them to new tasks. Mixture-of-LoRAs models expand neural networks efficiently by routing each layer input to a small subset of specialized LoRAs of the layer. Existing Mixture-of-LoRAs routers assign a learned routing weight to each LoRA to enable end-to-end training of the router. Despite their empirical promise, we observe that the routing weights are typically extremely imbalanced across LoRAs in practice, where only one or two LoRAs often dominate the routing weights. This essentially limits the number of effective LoRAs and thus severely hinders the expressive power of existing Mixture-of-LoRAs models. In this work, we attribute this weakness to the nature of learnable routing weights and rethink the fundamental design of the router. To address this critical issue, we propose a new router designed that we call Reinforcement Routing for Mixture-of-LoRAs (ReMix). Our key idea is using non-learnable routing weights to ensure all active LoRAs to be equally effective, with no LoRA dominating the routing weights. However, our routers cannot be trained directly via gradient descent due to our non-learnable routing weights. Hence, we further propose an unbiased gradient estimator for the router by employing the reinforce leave-one-out (RLOO) technique, where we regard the supervision loss as the reward and the router as the policy in reinforcement learning. Our gradient estimator also enables to scale up training compute to boost the predictive performance of our ReMix. Extensive experiments demonstrate that our proposed ReMix significantly outperform state-of-the-art parameter-efficient finetuning methods under a comparable number of activated parameters.
Bidirectional Representation Learning from Transformers using Multimodal Electronic Health Record Data for Chronic to Predict Depression
Sep 26, 2020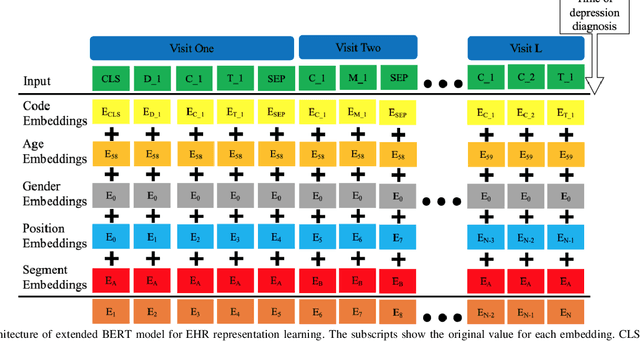
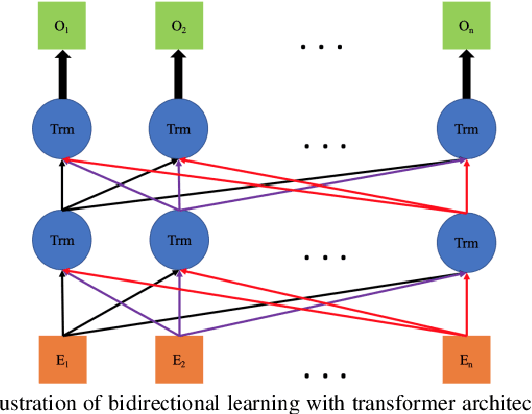

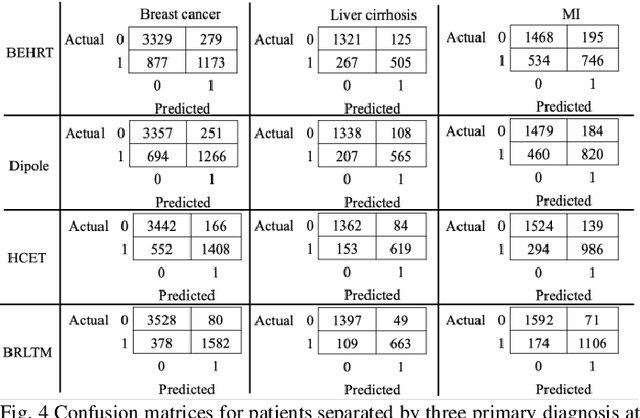
Advancements in machine learning algorithms have had a beneficial impact on representation learning, classification, and prediction models built using electronic health record (EHR) data. Effort has been put both on increasing models' overall performance as well as improving their interpretability, particularly regarding the decision-making process. In this study, we present a temporal deep learning model to perform bidirectional representation learning on EHR sequences with a transformer architecture to predict future diagnosis of depression. This model is able to aggregate five heterogenous and high-dimensional data sources from the EHR and process them in a temporal manner for chronic disease prediction at various prediction windows. We applied the current trend of pretraining and fine-tuning on EHR data to outperform the current state-of-the-art in chronic disease prediction, and to demonstrate the underlying relation between EHR codes in the sequence. The model generated the highest increases of precision-recall area under the curve (PRAUC) from 0.70 to 0.76 in depression prediction compared to the best baseline model. Furthermore, the self-attention weights in each sequence quantitatively demonstrated the inner relationship between various codes, which improved the model's interpretability. These results demonstrate the model's ability to utilize heterogeneous EHR data to predict depression while achieving high accuracy and interpretability, which may facilitate constructing clinical decision support systems in the future for chronic disease screening and early detection.