 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill Retrieval Augmentation for Agentic AI
Apr 27, 2026As large language models (LLMs) evolve into agentic problem solvers, they increasingly rely on external, reusable skills to handle tasks beyond their native parametric capabilities. In existing agent systems, the dominant strategy for incorporating skills is to explicitly enumerate available skills within the context window. However, this strategy fails to scale: as skill corpora expand, context budgets are consumed rapidly, and the agent becomes markedly less accurate in identifying the right skill. To this end, this paper formulates Skill Retrieval Augmentation (SRA), a new paradigm in which agents dynamically retrieve, incorporate, and apply relevant skills from large external skill corpora on demand. To make this problem measurable, we construct a large-scale skill corpus and introduce SRA-Bench, the first benchmark for decomposed evaluation of the full SRA pipeline, covering skill retrieval, skill incorporation, and end-task execution. SRA-Bench contains 5,400 capability-intensive test instances and 636 manually constructed gold skills, which are mixed with web-collected distractor skills to form a large-scale corpus of 26,262 skills. Extensive experiments show that retrieval-based skill augmentation can substantially improve agent performance, validating the promise of the paradigm. At the same time, we uncover a fundamental gap in skill incorporation: current LLM agents tend to load skills at similar rates, regardless of whether a gold skill is retrieved or whether the task actually requires external capabilities. This shows that the bottleneck in skill augmentation lies not only in retrieval but also in the base model's ability to determine which skill to load and when external loading is actually needed. These findings position SRA as a distinct research problem and establish a foundation for the scalable augmentation of capabilities in future agent systems.
Analytical Search
Feb 12, 2026Analytical information needs, such as trend analysis and causal impact assessment, are prevalent across various domains including law, finance, science, and much more. However, existing information retrieval paradigms, whether based on relevance-oriented document ranking or retrieval-augmented generation (RAG) with large language models (LLMs), often struggle to meet the end-to-end requirements of such tasks at the corpus scale. They either emphasize information finding rather than end-to-end problem solving, or simply treat everything as naive question answering, offering limited control over reasoning, evidence usage, and verifiability. As a result, they struggle to support analytical queries that have diverse utility concepts and high accountability requirements. In this paper, we propose analytical search as a distinct and emerging search paradigm designed to fulfill these analytical information needs. Analytical search reframes search as an evidence-governed, process-oriented analytical workflow that explicitly models analytical intent, retrieves evidence for fusion, and produces verifiable conclusions through structured, multi-step inference. We position analytical search in contrast to existing paradigms, and present a unified system framework that integrates query understanding, recall-oriented retrieval, reasoning-aware fusion, and adaptive verification. We also discuss potential research directions for the construction of analytical search engines. In this way, we highlight the conceptual significance and practical importance of analytical search and call on efforts toward the next generation of search engines that support analytical information needs.
Equity vs. Equality: Optimizing Ranking Fairness for Tailored Provider Needs
Jan 31, 2026Ranking plays a central role in connecting users and providers in Information Retrieval (IR) systems, making provider-side fairness an important challenge. While recent research has begun to address fairness in ranking, most existing approaches adopt an equality-based perspective, aiming to ensure that providers with similar content receive similar exposure. However, it overlooks the diverse needs of real-world providers, whose utility from ranking may depend not only on exposure but also on outcomes like sales or engagement. Consequently, exposure-based fairness may not accurately capture the true utility perceived by different providers with varying priorities. To this end, we introduce an equity-oriented fairness framework that explicitly models each provider's preferences over key outcomes such as exposure and sales, thus evaluating whether a ranking algorithm can fulfill these individualized goals while maintaining overall fairness across providers. Based on this framework, we develop EquityRank, a gradient-based algorithm that jointly optimizes user-side effectiveness and provider-side equity. Extensive offline and online simulations demonstrate that EquityRank offers improved trade-offs between effectiveness and fairness and adapts to heterogeneous provider needs.
RbFT: Robust Fine-tuning for Retrieval-Augmented Generation against Retrieval Defects
Jan 30, 2025



Retrieval-augmented generation (RAG) enhances large language models (LLMs) by integrating external knowledge retrieved from a knowledge base. However, its effectiveness is fundamentally constrained by the reliability of both the retriever and the knowledge base. In real-world scenarios, imperfections in these components often lead to the retrieval of noisy, irrelevant, or misleading counterfactual information, ultimately undermining the trustworthiness of RAG systems. To address this challenge, we propose Robust Fine-Tuning (RbFT), a method designed to enhance the resilience of LLMs against retrieval defects through two targeted fine-tuning tasks. Experimental results demonstrate that RbFT significantly improves the robustness of RAG systems across diverse retrieval conditions, surpassing existing methods while maintaining high inference efficiency and compatibility with other robustness techniques.
PRE: A Peer Review Based Large Language Model Evaluator
Jan 28, 2024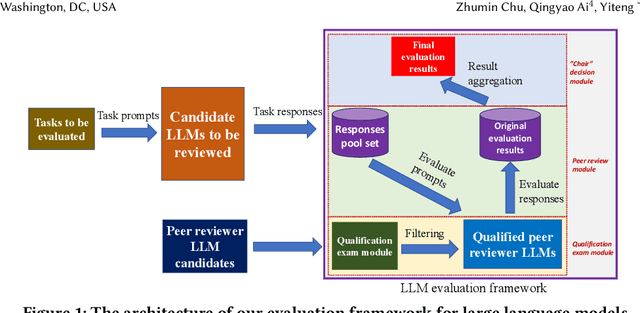
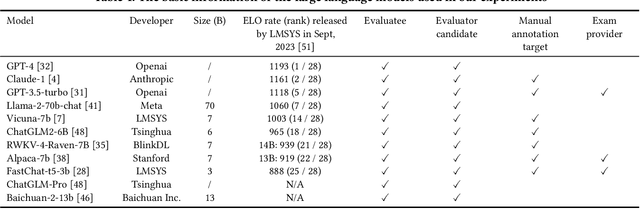
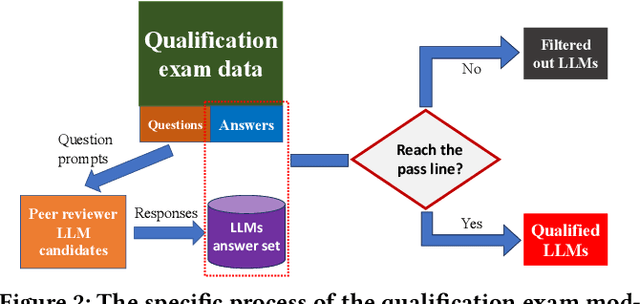
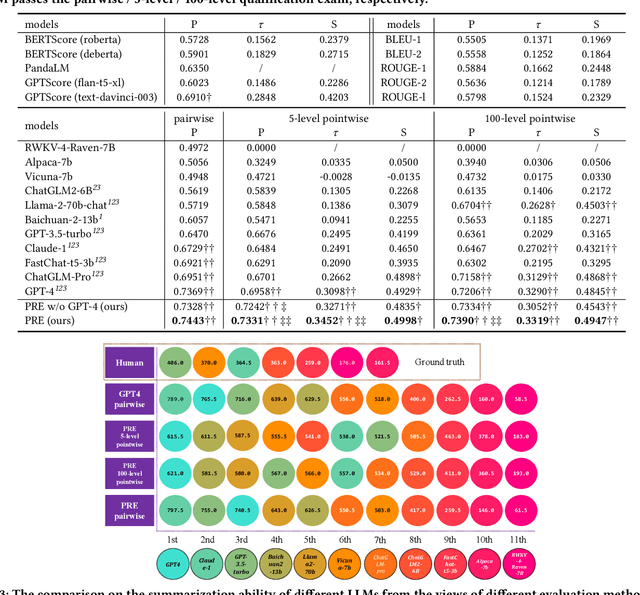
The impressive performance of large language models (LLMs) has attracted considerable attention from the academic and industrial communities. Besides how to construct and train LLMs, how to effectively evaluate and compare the capacity of LLMs has also been well recognized as an important yet difficult problem. Existing paradigms rely on either human annotators or model-based evaluators to evaluate the performance of LLMs on different tasks. However, these paradigms often suffer from high cost, low generalizability, and inherited biases in practice, which make them incapable of supporting the sustainable development of LLMs in long term. In order to address these issues, inspired by the peer review systems widely used in academic publication process, we propose a novel framework that can automatically evaluate LLMs through a peer-review process. Specifically, for the evaluation of a specific task, we first construct a small qualification exam to select "reviewers" from a couple of powerful LLMs. Then, to actually evaluate the "submissions" written by different candidate LLMs, i.e., the evaluatees, we use the reviewer LLMs to rate or compare the submissions. The final ranking of evaluatee LLMs is generated based on the results provided by all reviewers. We conducted extensive experiments on text summarization tasks with eleven LLMs including GPT-4. The results demonstrate the existence of biasness when evaluating using a single LLM. Also, our PRE model outperforms all the baselines, illustrating the effectiveness of the peer review mechanism.