 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDueling Convex Optimization with General Preferences
Sep 27, 2022We address the problem of \emph{convex optimization with dueling feedback}, where the goal is to minimize a convex function given a weaker form of \emph{dueling} feedback. Each query consists of two points and the dueling feedback returns a (noisy) single-bit binary comparison of the function values of the two queried points. The translation of the function values to the single comparison bit is through a \emph{transfer function}. This problem has been addressed previously for some restricted classes of transfer functions, but here we consider a very general transfer function class which includes all functions that can be approximated by a finite polynomial with a minimal degree $p$. Our main contribution is an efficient algorithm with convergence rate of $\smash{\widetilde O}(\epsilon^{-4p})$ for a smooth convex objective function, and an optimal rate of $\smash{\widetilde O}(\epsilon^{-2p})$ when the objective is smooth and strongly convex.
Regret Minimization and Convergence to Equilibria in General-sum Markov Games
Aug 08, 2022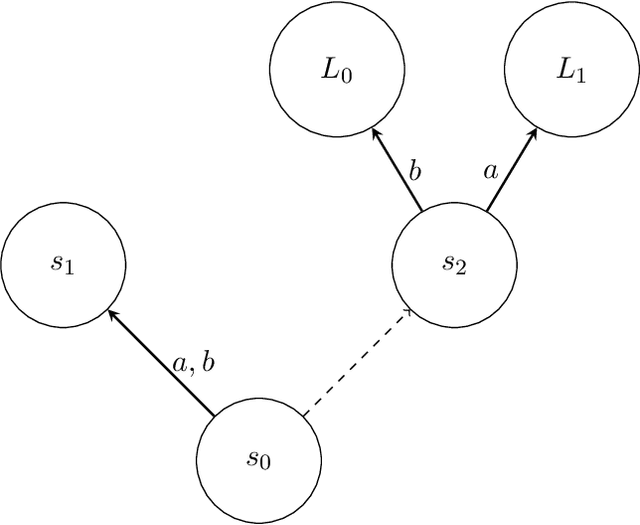
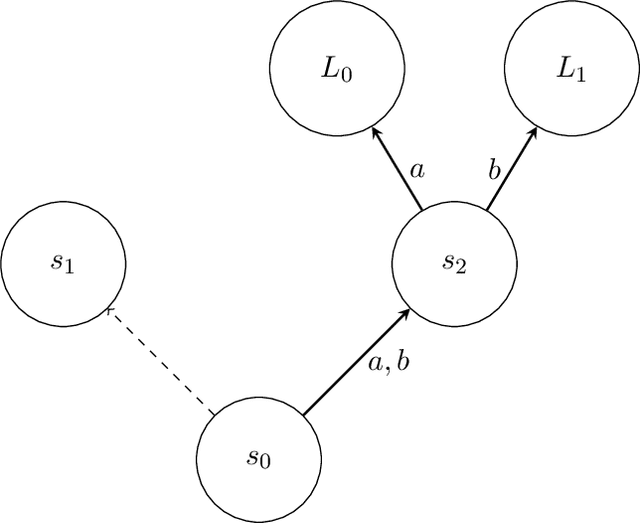
An abundance of recent impossibility results establish that regret minimization in Markov games with adversarial opponents is both statistically and computationally intractable. Nevertheless, none of these results preclude the possibility of regret minimization under the assumption that all parties adopt the same learning procedure. In this work, we present the first (to our knowledge) algorithm for learning in general-sum Markov games that provides sublinear regret guarantees when executed by all agents. The bounds we obtain are for swap regret, and thus, along the way, imply convergence to a correlated equilibrium. Our algorithm is decentralized, computationally efficient, and does not require any communication between agents. Our key observation is that online learning via policy optimization in Markov games essentially reduces to a form of weighted regret minimization, with unknown weights determined by the path length of the agents' policy sequence. Consequently, controlling the path length leads to weighted regret objectives for which sufficiently adaptive algorithms provide sublinear regret guarantees.
Optimism in Face of a Context: Regret Guarantees for Stochastic Contextual MDP
Jul 22, 2022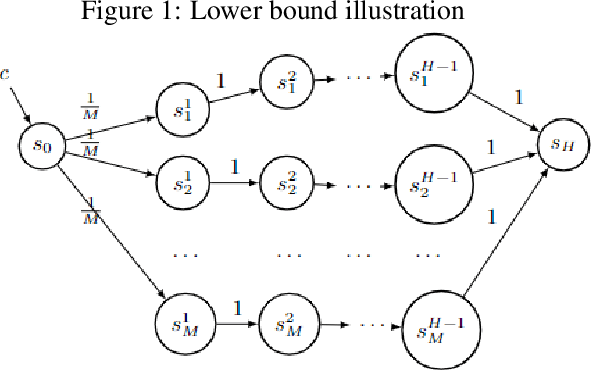
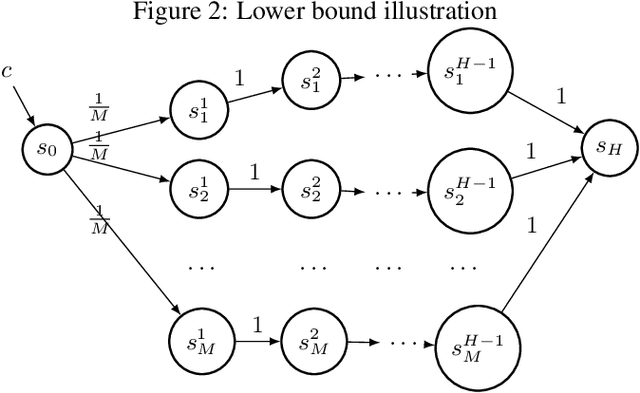
We present regret minimization algorithms for stochastic contextual MDPs under minimum reachability assumption, using an access to an offline least square regression oracle. We analyze three different settings: where the dynamics is known, where the dynamics is unknown but independent of the context and the most challenging setting where the dynamics is unknown and context-dependent. For the latter, our algorithm obtains $ \tilde{O}\left( \max\{H,{1}/{p_{min}}\}H|S|^{3/2}\sqrt{|A|T\log(\max\{|\mathcal{F}|,|\mathcal{P}|\}/\delta)} \right)$ regret bound, with probability $1-\delta$, where $\mathcal{P}$ and $\mathcal{F}$ are finite and realizable function classes used to approximate the dynamics and rewards respectively, $p_{min}$ is the minimum reachability parameter, $S$ is the set of states, $A$ the set of actions, $H$ the horizon, and $T$ the number of episodes. To our knowledge, our approach is the first optimistic approach applied to contextual MDPs with general function approximation (i.e., without additional knowledge regarding the function class, such as it being linear and etc.). In addition, we present a lower bound of $\Omega(\sqrt{T H |S| |A| \ln(|\mathcal{F}|/|S|)/\ln(|A|)})$, on the expected regret which holds even in the case of known dynamics.
Guarantees for Epsilon-Greedy Reinforcement Learning with Function Approximation
Jun 19, 2022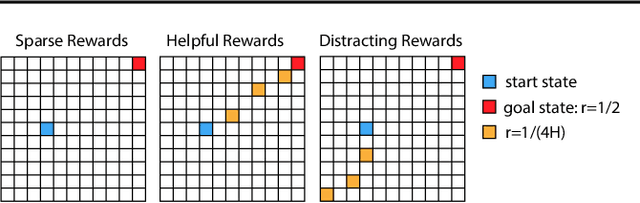
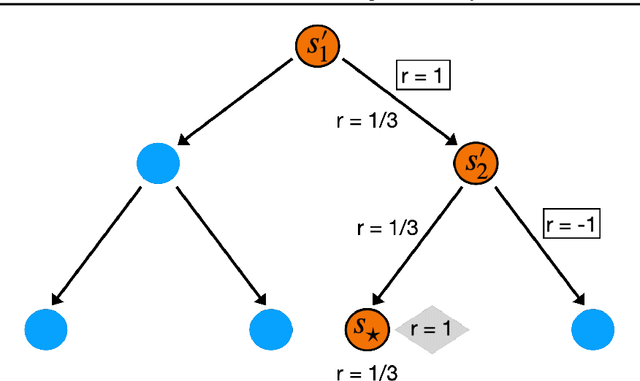
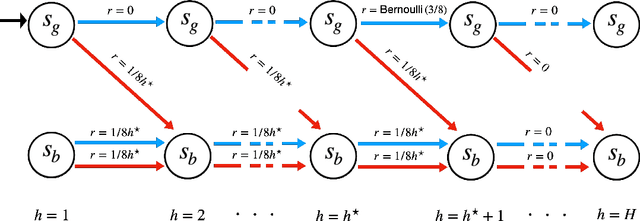
Myopic exploration policies such as epsilon-greedy, softmax, or Gaussian noise fail to explore efficiently in some reinforcement learning tasks and yet, they perform well in many others. In fact, in practice, they are often selected as the top choices, due to their simplicity. But, for what tasks do such policies succeed? Can we give theoretical guarantees for their favorable performance? These crucial questions have been scarcely investigated, despite the prominent practical importance of these policies. This paper presents a theoretical analysis of such policies and provides the first regret and sample-complexity bounds for reinforcement learning with myopic exploration. Our results apply to value-function-based algorithms in episodic MDPs with bounded Bellman Eluder dimension. We propose a new complexity measure called myopic exploration gap, denoted by alpha, that captures a structural property of the MDP, the exploration policy and the given value function class. We show that the sample-complexity of myopic exploration scales quadratically with the inverse of this quantity, 1 / alpha^2. We further demonstrate through concrete examples that myopic exploration gap is indeed favorable in several tasks where myopic exploration succeeds, due to the corresponding dynamics and reward structure.
There is no Accuracy-Interpretability Tradeoff in Reinforcement Learning for Mazes
Jun 09, 2022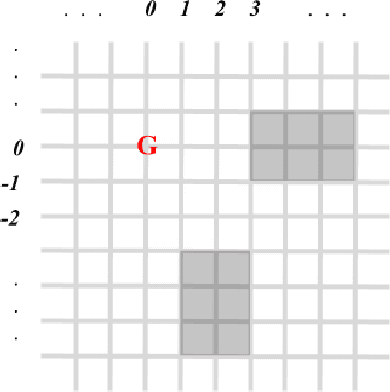

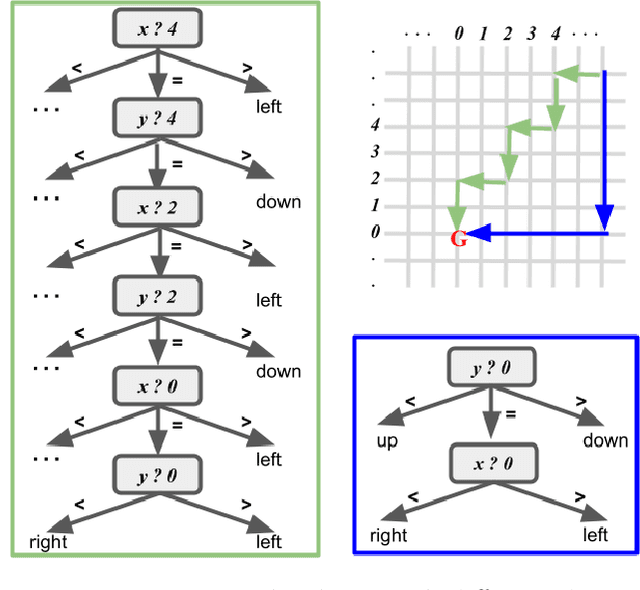
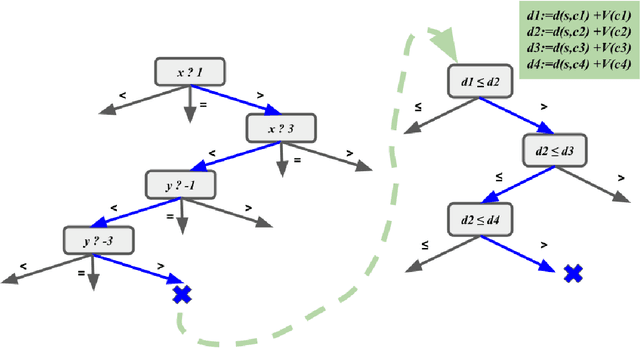
Interpretability is an essential building block for trustworthiness in reinforcement learning systems. However, interpretability might come at the cost of deteriorated performance, leading many researchers to build complex models. Our goal is to analyze the cost of interpretability. We show that in certain cases, one can achieve policy interpretability while maintaining its optimality. We focus on a classical problem from reinforcement learning: mazes with $k$ obstacles in $\mathbb{R}^d$. We prove the existence of a small decision tree with a linear function at each inner node and depth $O(\log k + 2^d)$ that represents an optimal policy. Note that for the interesting case of a constant $d$, we have $O(\log k)$ depth. Thus, in this setting, there is no accuracy-interpretability tradeoff. To prove this result, we use a new "compressing" technique that might be useful in additional settings.
What killed the Convex Booster ?
May 25, 2022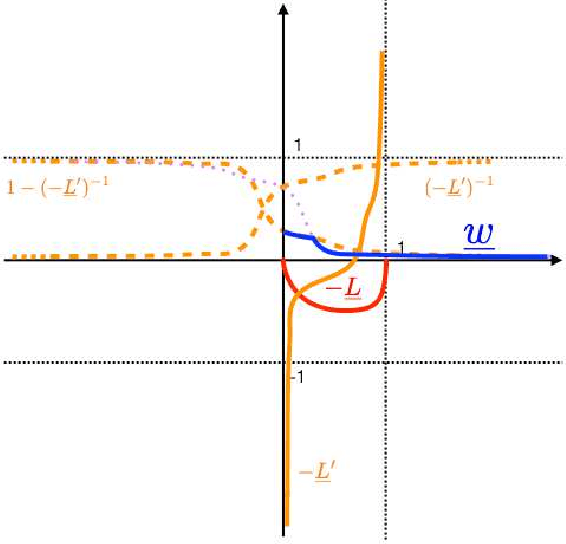
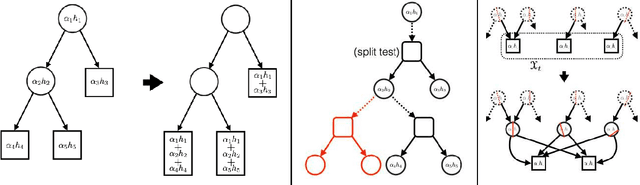

A landmark negative result of Long and Servedio established a worst-case spectacular failure of a supervised learning trio (loss, algorithm, model) otherwise praised for its high precision machinery. Hundreds of papers followed up on the two suspected culprits: the loss (for being convex) and/or the algorithm (for fitting a classical boosting blueprint). Here, we call to the half-century+ founding theory of losses for class probability estimation (properness), an extension of Long and Servedio's results and a new general boosting algorithm to demonstrate that the real culprit in their specific context was in fact the (linear) model class. We advocate for a more general stanpoint on the problem as we argue that the source of the negative result lies in the dark side of a pervasive -- and otherwise prized -- aspect of ML: \textit{parameterisation}.
Strategizing against Learners in Bayesian Games
May 17, 2022We study repeated two-player games where one of the players, the learner, employs a no-regret learning strategy, while the other, the optimizer, is a rational utility maximizer. We consider general Bayesian games, where the payoffs of both the optimizer and the learner could depend on the type, which is drawn from a publicly known distribution, but revealed privately to the learner. We address the following questions: (a) what is the bare minimum that the optimizer can guarantee to obtain regardless of the no-regret learning algorithm employed by the learner? (b) are there learning algorithms that cap the optimizer payoff at this minimum? (c) can these algorithms be implemented efficiently? While building this theory of optimizer-learner interactions, we define a new combinatorial notion of regret called polytope swap regret, that could be of independent interest in other settings.
Modeling Attrition in Recommender Systems with Departing Bandits
Mar 25, 2022

Traditionally, when recommender systems are formalized as multi-armed bandits, the policy of the recommender system influences the rewards accrued, but not the length of interaction. However, in real-world systems, dissatisfied users may depart (and never come back). In this work, we propose a novel multi-armed bandit setup that captures such policy-dependent horizons. Our setup consists of a finite set of user types, and multiple arms with Bernoulli payoffs. Each (user type, arm) tuple corresponds to an (unknown) reward probability. Each user's type is initially unknown and can only be inferred through their response to recommendations. Moreover, if a user is dissatisfied with their recommendation, they might depart the system. We first address the case where all users share the same type, demonstrating that a recent UCB-based algorithm is optimal. We then move forward to the more challenging case, where users are divided among two types. While naive approaches cannot handle this setting, we provide an efficient learning algorithm that achieves $\tilde{O}(\sqrt{T})$ regret, where $T$ is the number of users.
Learning Efficiently Function Approximation for Contextual MDP
Mar 02, 2022
We study learning contextual MDPs using a function approximation for both the rewards and the dynamics. We consider both the case where the dynamics is known and unknown, and the case that the dynamics dependent or independent of the context. For all four models we derive polynomial sample and time complexity (assuming an efficient ERM oracle). Our methodology gives a general reduction from learning contextual MDP to supervised learning.
Benign Underfitting of Stochastic Gradient Descent
Mar 01, 2022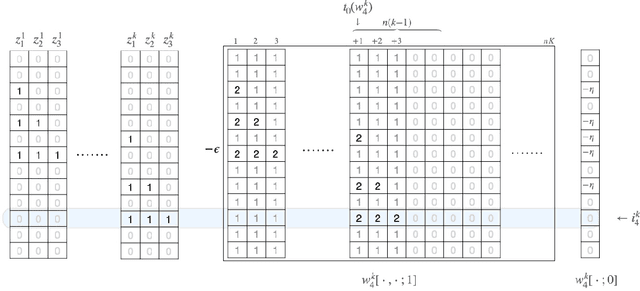
We study to what extent may stochastic gradient descent (SGD) be understood as a "conventional" learning rule that achieves generalization performance by obtaining a good fit to training data. We consider the fundamental stochastic convex optimization framework, where (one pass, without-replacement) SGD is classically known to minimize the population risk at rate $O(1/\sqrt n)$, and prove that, surprisingly, there exist problem instances where the SGD solution exhibits both empirical risk and generalization gap of $\Omega(1)$. Consequently, it turns out that SGD is not algorithmically stable in any sense, and its generalization ability cannot be explained by uniform convergence or any other currently known generalization bound technique for that matter (other than that of its classical analysis). We then continue to analyze the closely related with-replacement SGD, for which we show that an analogous phenomenon does not occur and prove that its population risk does in fact converge at the optimal rate. Finally, we interpret our main results in the context of without-replacement SGD for finite-sum convex optimization problems, and derive upper and lower bounds for the multi-epoch regime that significantly improve upon previously known results.