 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCoPnet: Exploring Local Motion and Contrast Priors for Infrared Small Target Super-Resolution
Jan 06, 2022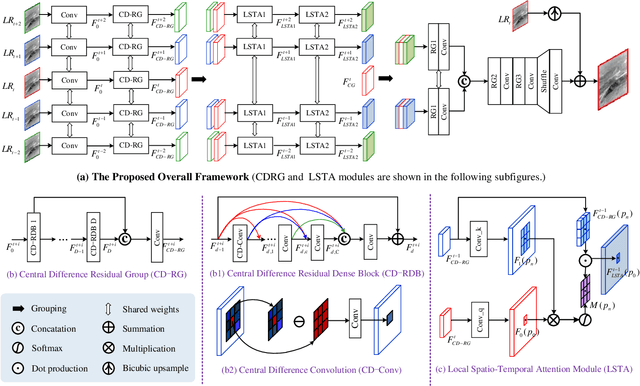
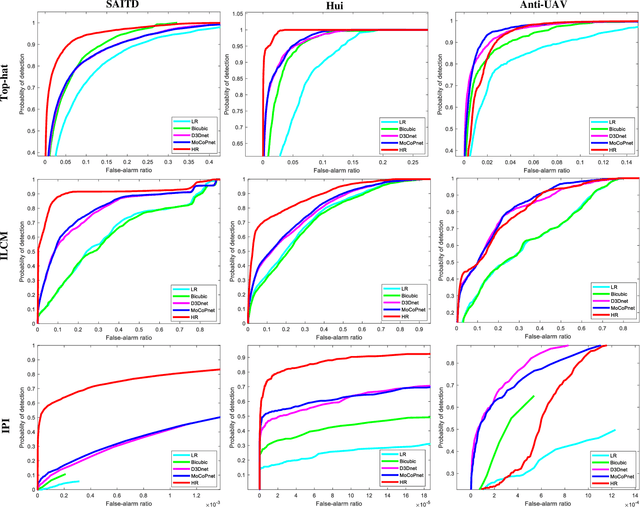

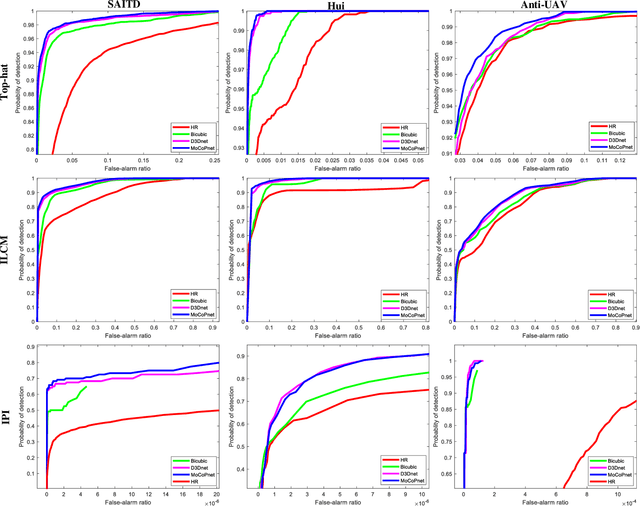
Infrared small target super-resolution (SR) aims to recover reliable and detailed high-resolution image with highcontrast targets from its low-resolution counterparts. Since the infrared small target lacks color and fine structure information, it is significant to exploit the supplementary information among sequence images to enhance the target. In this paper, we propose the first infrared small target SR method named local motion and contrast prior driven deep network (MoCoPnet) to integrate the domain knowledge of infrared small target into deep network, which can mitigate the intrinsic feature scarcity of infrared small targets. Specifically, motivated by the local motion prior in the spatio-temporal dimension, we propose a local spatiotemporal attention module to perform implicit frame alignment and incorporate the local spatio-temporal information to enhance the local features (especially for small targets). Motivated by the local contrast prior in the spatial dimension, we propose a central difference residual group to incorporate the central difference convolution into the feature extraction backbone, which can achieve center-oriented gradient-aware feature extraction to further improve the target contrast. Extensive experiments have demonstrated that our method can recover accurate spatial dependency and improve the target contrast. Comparative results show that MoCoPnet can outperform the state-of-the-art video SR and single image SR methods in terms of both SR performance and target enhancement. Based on the SR results, we further investigate the influence of SR on infrared small target detection and the experimental results demonstrate that MoCoPnet promotes the detection performance. The code is available at https://github.com/XinyiYing/MoCoPnet.
Detecting and Tracking Small and Dense Moving Objects in Satellite Videos: A Benchmark
Nov 25, 2021

Satellite video cameras can provide continuous observation for a large-scale area, which is important for many remote sensing applications. However, achieving moving object detection and tracking in satellite videos remains challenging due to the insufficient appearance information of objects and lack of high-quality datasets. In this paper, we first build a large-scale satellite video dataset with rich annotations for the task of moving object detection and tracking. This dataset is collected by the Jilin-1 satellite constellation and composed of 47 high-quality videos with 1,646,038 instances of interest for object detection and 3,711 trajectories for object tracking. We then introduce a motion modeling baseline to improve the detection rate and reduce false alarms based on accumulative multi-frame differencing and robust matrix completion. Finally, we establish the first public benchmark for moving object detection and tracking in satellite videos, and extensively evaluate the performance of several representative approaches on our dataset. Comprehensive experimental analyses and insightful conclusions are also provided. The dataset is available at https://github.com/QingyongHu/VISO.
Dense Dual-Attention Network for Light Field Image Super-Resolution
Oct 23, 2021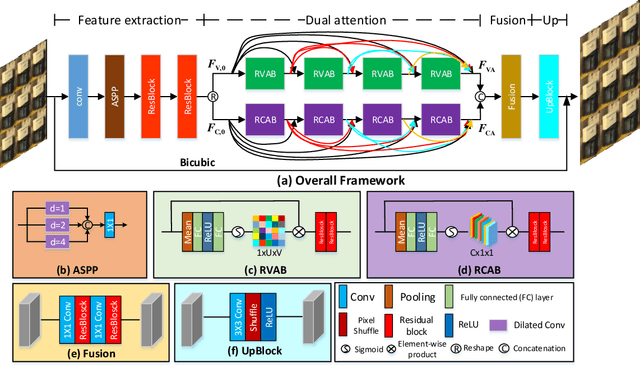
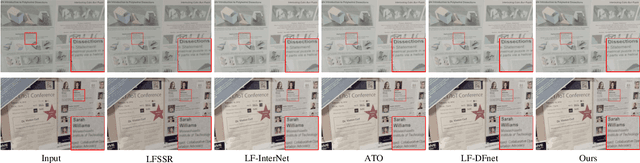

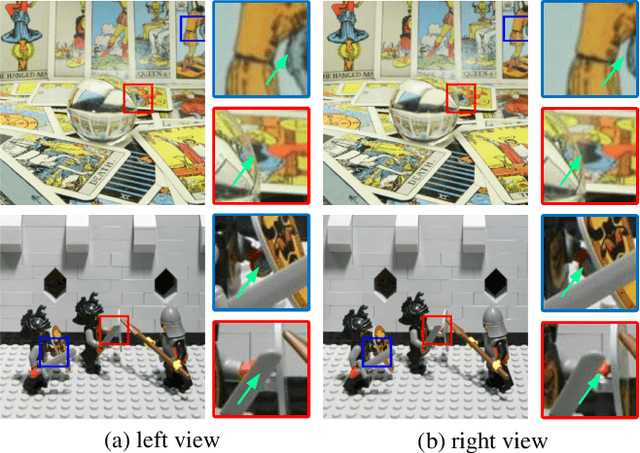
Light field (LF) images can be used to improve the performance of image super-resolution (SR) because both angular and spatial information is available. It is challenging to incorporate distinctive information from different views for LF image SR. Moreover, the long-term information from the previous layers can be weakened as the depth of network increases. In this paper, we propose a dense dual-attention network for LF image SR. Specifically, we design a view attention module to adaptively capture discriminative features across different views and a channel attention module to selectively focus on informative information across all channels. These two modules are fed to two branches and stacked separately in a chain structure for adaptive fusion of hierarchical features and distillation of valid information. Meanwhile, a dense connection is used to fully exploit multi-level information. Extensive experiments demonstrate that our dense dual-attention mechanism can capture informative information across views and channels to improve SR performance. Comparative results show the advantage of our method over state-of-the-art methods on public datasets.
DARDet: A Dense Anchor-free Rotated Object Detector in Aerial Images
Oct 03, 2021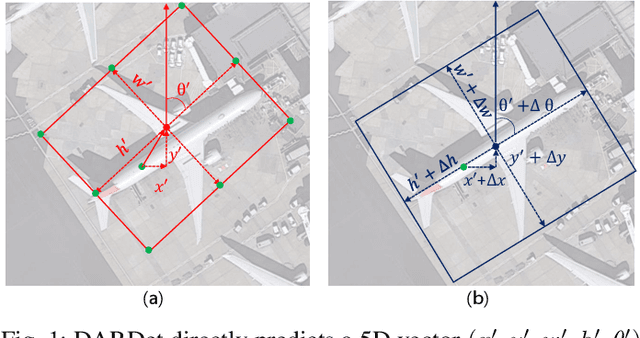
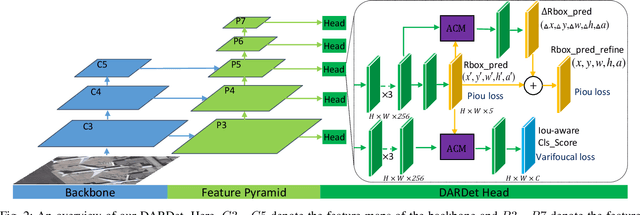
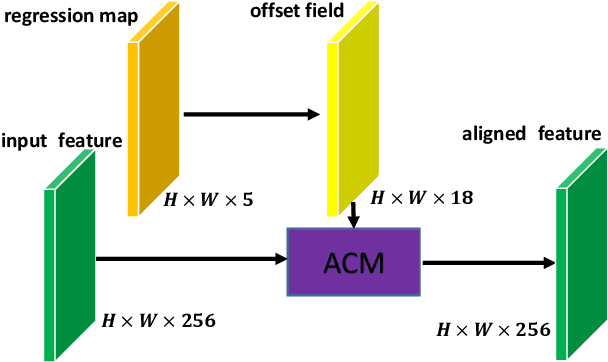
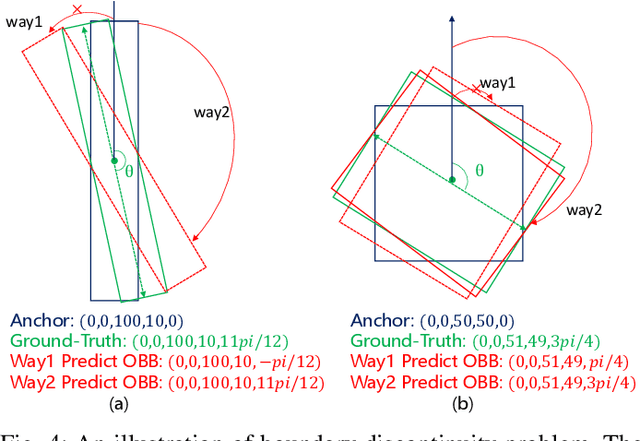
Rotated object detection in aerial images has received increasing attention for a wide range of applications. However, it is also a challenging task due to the huge variations of scale, rotation, aspect ratio, and densely arranged targets. Most existing methods heavily rely on a large number of pre-defined anchors with different scales, angles, and aspect ratios, and are optimized with a distance loss. Therefore, these methods are sensitive to anchor hyper-parameters and easily suffer from performance degradation caused by boundary discontinuity. To handle this problem, in this paper, we propose a dense anchor-free rotated object detector (DARDet) for rotated object detection in aerial images. Our DARDet directly predicts five parameters of rotated boxes at each foreground pixel of feature maps. We design a new alignment convolution module to extracts aligned features and introduce a PIoU loss for precise and stable regression. Our method achieves state-of-the-art performance on three commonly used aerial objects datasets (i.e., DOTA, HRSC2016, and UCAS-AOD) while keeping high efficiency. Code is available at https://github.com/zf020114/DARDet.
Light Field Image Super-Resolution with Transformers
Aug 17, 2021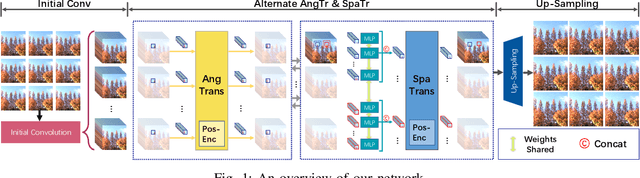

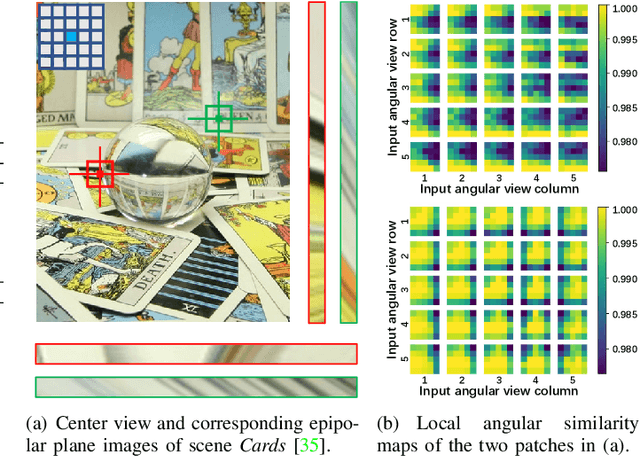
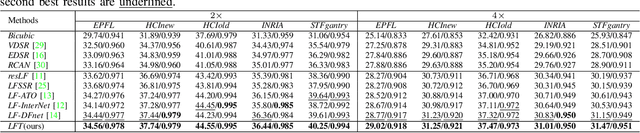
Light field (LF) image super-resolution (SR) aims at reconstructing high-resolution LF images from their low-resolution counterparts. Although CNN-based methods have achieved remarkable performance in LF image SR, these methods cannot fully model the non-local properties of the 4D LF data. In this paper, we propose a simple but effective Transformer-based method for LF image SR. In our method, an angular Transformer is designed to incorporate complementary information among different views, and a spatial Transformer is developed to capture both local and long-range dependencies within each sub-aperture image. With the proposed angular and spatial Transformers, the beneficial information in an LF can be fully exploited and the SR performance is boosted. We validate the effectiveness of our angular and spatial Transformers through extensive ablation studies, and compare our method to recent state-of-the-art methods on five public LF datasets. Our method achieves superior SR performance with a small model size and low computational cost.
Selective Light Field Refocusing for Camera Arrays Using Bokeh Rendering and Superresolution
Aug 09, 2021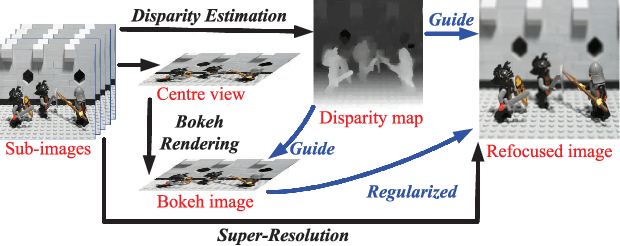
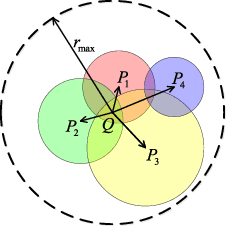


Camera arrays provide spatial and angular information within a single snapshot. With refocusing methods, focal planes can be altered after exposure. In this letter, we propose a light field refocusing method to improve the imaging quality of camera arrays. In our method, the disparity is first estimated. Then, the unfocused region (bokeh) is rendered by using a depth-based anisotropic filter. Finally, the refocused image is produced by a reconstruction-based superresolution approach where the bokeh image is used as a regularization term. Our method can selectively refocus images with focused region being superresolved and bokeh being aesthetically rendered. Our method also enables postadjustment of depth of field. We conduct experiments on both public and self-developed datasets. Our method achieves superior visual performance with acceptable computational cost as compared to other state-of-the-art methods. Code is available at https://github.com/YingqianWang/Selective-LF-Refocusing.
Dense Nested Attention Network for Infrared Small Target Detection
Jun 01, 2021

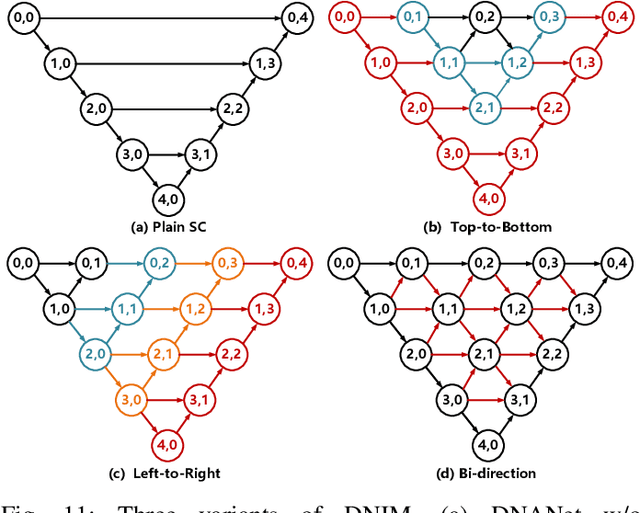
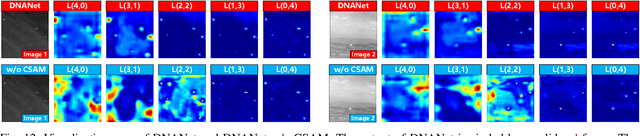
Single-frame infrared small target (SIRST) detection aims at separating small targets from clutter backgrounds. With the advances of deep learning, CNN-based methods have yielded promising results in generic object detection due to their powerful modeling capability. However, existing CNN-based methods cannot be directly applied for infrared small targets since pooling layers in their networks could lead to the loss of targets in deep layers. To handle this problem, we propose a dense nested attention network (DNANet) in this paper. Specifically, we design a dense nested interactive module (DNIM) to achieve progressive interaction among high-level and low-level features. With the repeated interaction in DNIM, infrared small targets in deep layers can be maintained. Based on DNIM, we further propose a cascaded channel and spatial attention module (CSAM) to adaptively enhance multi-level features. With our DNANet, contextual information of small targets can be well incorporated and fully exploited by repeated fusion and enhancement. Moreover, we develop an infrared small target dataset (namely, NUDT-SIRST) and propose a set of evaluation metrics to conduct comprehensive performance evaluation. Experiments on both public and our self-developed datasets demonstrate the effectiveness of our method. Compared to other state-of-the-art methods, our method achieves better performance in terms of probability of detection (Pd), false-alarm rate (Fa), and intersection of union (IoU).
Non-Convex Tensor Low-Rank Approximation for Infrared Small Target Detection
May 31, 2021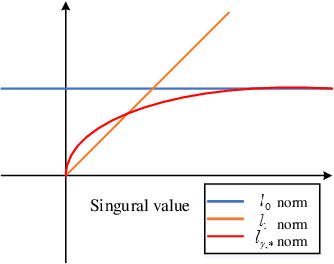



Infrared small target detection plays an important role in many infrared systems. Recently, many infrared small target detection methods have been proposed, in which the lowrank model has been used as a powerful tool. However, most low-rank-based methods assign the same weights for different singular values, which will lead to inaccurate background estimation. Considering that different singular values have different importance and should be treated discriminatively, in this paper, we propose a non-convex tensor low-rank approximation (NTLA) method for infrared small target detection. In our method, NTLA adaptively assigns different weights to different singular values for accurate background estimation. Based on the proposed NTLA, we use the asymmetric spatial-temporal total variation (ASTTV) to thoroughly describe background feature, which can achieve good background estimation and detection in complex scenes. Compared with the traditional total variation approach, ASTTV exploits different smoothness strength for spatial and temporal regularization. We develop an efficient algorithm to find the optimal solution of the proposed model. Compared with some state-of-the-art methods, the proposed method achieve an improvement in different evaluation metrics. Extensive experiments on both synthetic and real data demonstrate the proposed method provide a more robust detection in complex situations with low false rates.
Unsupervised Degradation Representation Learning for Blind Super-Resolution
Apr 01, 2021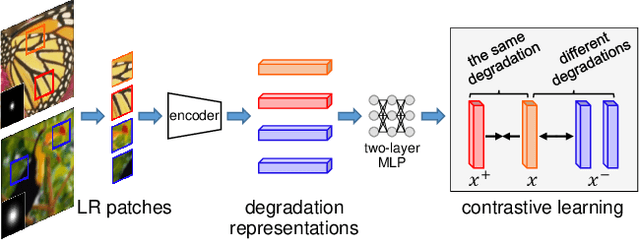

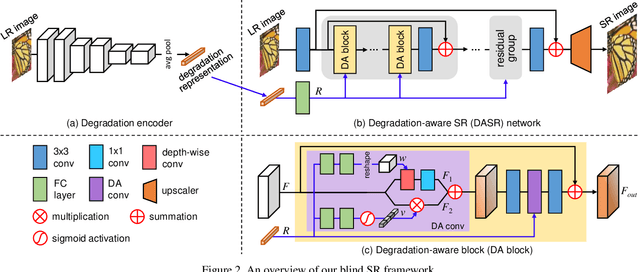
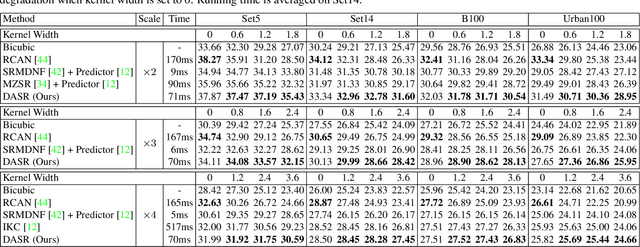
Most existing CNN-based super-resolution (SR) methods are developed based on an assumption that the degradation is fixed and known (e.g., bicubic downsampling). However, these methods suffer a severe performance drop when the real degradation is different from their assumption. To handle various unknown degradations in real-world applications, previous methods rely on degradation estimation to reconstruct the SR image. Nevertheless, degradation estimation methods are usually time-consuming and may lead to SR failure due to large estimation errors. In this paper, we propose an unsupervised degradation representation learning scheme for blind SR without explicit degradation estimation. Specifically, we learn abstract representations to distinguish various degradations in the representation space rather than explicit estimation in the pixel space. Moreover, we introduce a Degradation-Aware SR (DASR) network with flexible adaption to various degradations based on the learned representations. It is demonstrated that our degradation representation learning scheme can extract discriminative representations to obtain accurate degradation information. Experiments on both synthetic and real images show that our network achieves state-of-the-art performance for the blind SR task. Code is available at: https://github.com/LongguangWang/DASR.
ShipSRDet: An End-to-End Remote Sensing Ship Detector Using Super-Resolved Feature Representation
Mar 17, 2021
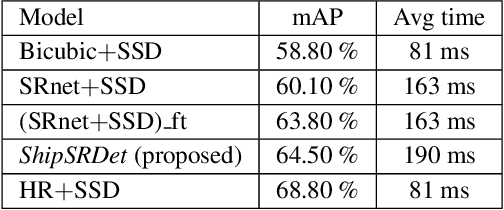
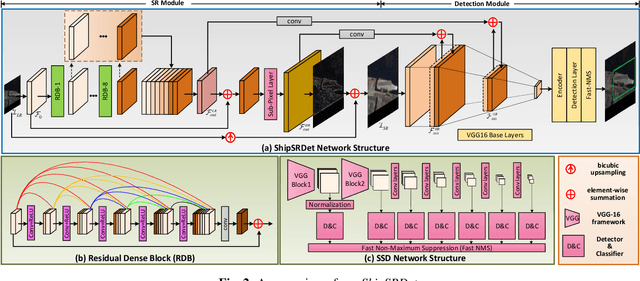

High-resolution remote sensing images can provide abundant appearance information for ship detection. Although several existing methods use image super-resolution (SR) approaches to improve the detection performance, they consider image SR and ship detection as two separate processes and overlook the internal coherence between these two correlated tasks. In this paper, we explore the potential benefits introduced by image SR to ship detection, and propose an end-to-end network named ShipSRDet. In our method, we not only feed the super-resolved images to the detector but also integrate the intermediate features of the SR network with those of the detection network. In this way, the informative feature representation extracted by the SR network can be fully used for ship detection. Experimental results on the HRSC dataset validate the effectiveness of our method. Our ShipSRDet can recover the missing details from the input image and achieves promising ship detection performance.