 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DFPN-HS$^2$: 3D Feature Pyramid Network Based High Sensitivity and Specificity Pulmonary Nodule Detection
Jun 11, 2019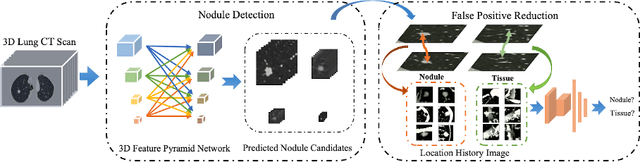

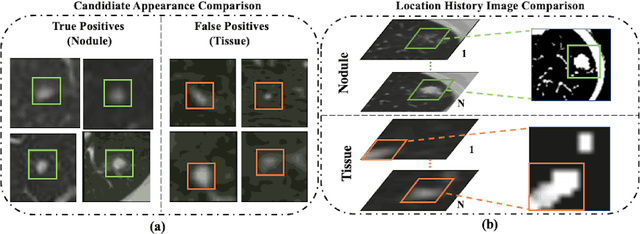

Accurate detection of pulmonary nodules with high sensitivity and specificity is essential for automatic lung cancer diagnosis from CT scans. Although many deep learning-based algorithms make great progress for improving the accuracy of nodule detection, the high false positive rate is still a challenging problem which limited the automatic diagnosis in routine clinical practice. In this paper, we propose a novel pulmonary nodule detection framework based on a 3D Feature Pyramid Network (3DFPN) to improve the sensitivity of nodule detection by employing multi-scale features to increase the resolution of nodules, as well as a parallel top-down path to transit the high-level semantic features to complement low-level general features. Furthermore, a High Sensitivity and Specificity (HS$^2$) network is introduced to eliminate the falsely detected nodule candidates by tracking the appearance changes in continuous CT slices of each nodule candidate. The proposed framework is evaluated on the public Lung Nodule Analysis (LUNA16) challenge dataset. Our method is able to accurately detect lung nodules at high sensitivity and specificity and achieves $90.4\%$ sensitivity with 1/8 false positive per scan which outperforms the state-of-the-art results $15.6\%$.
Recognizing American Sign Language Manual Signs from RGB-D Videos
Jun 07, 2019


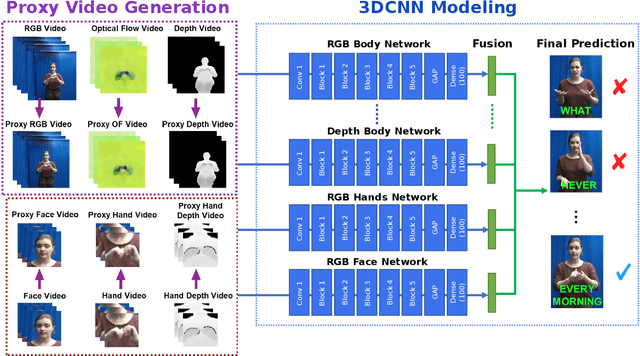
In this paper, we propose a 3D Convolutional Neural Network (3DCNN) based multi-stream framework to recognize American Sign Language (ASL) manual signs (consisting of movements of the hands, as well as non-manual face movements in some cases) in real-time from RGB-D videos, by fusing multimodality features including hand gestures, facial expressions, and body poses from multi-channels (RGB, depth, motion, and skeleton joints). To learn the overall temporal dynamics in a video, a proxy video is generated by selecting a subset of frames for each video which are then used to train the proposed 3DCNN model. We collect a new ASL dataset, ASL-100-RGBD, which contains 42 RGB-D videos captured by a Microsoft Kinect V2 camera, each of 100 ASL manual signs, including RGB channel, depth maps, skeleton joints, face features, and HDface. The dataset is fully annotated for each semantic region (i.e. the time duration of each word that the human signer performs). Our proposed method achieves 92.88 accuracy for recognizing 100 ASL words in our newly collected ASL-100-RGBD dataset. The effectiveness of our framework for recognizing hand gestures from RGB-D videos is further demonstrated on the Chalearn IsoGD dataset and achieves 76 accuracy which is 5.51 higher than the state-of-the-art work in terms of average fusion by using only 5 channels instead of 12 channels in the previous work.
Design and Control of a Quasi-Direct Drive Soft Hybrid Knee Exoskeleton for Injury Prevention during Squatting
Feb 19, 2019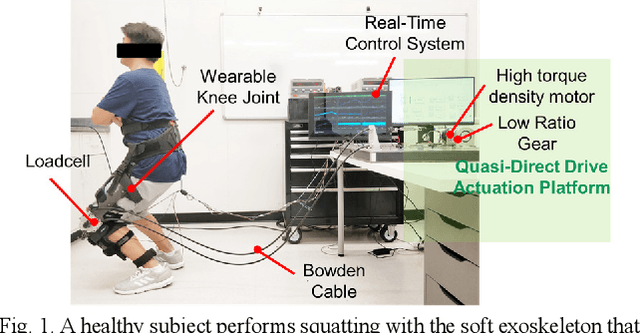
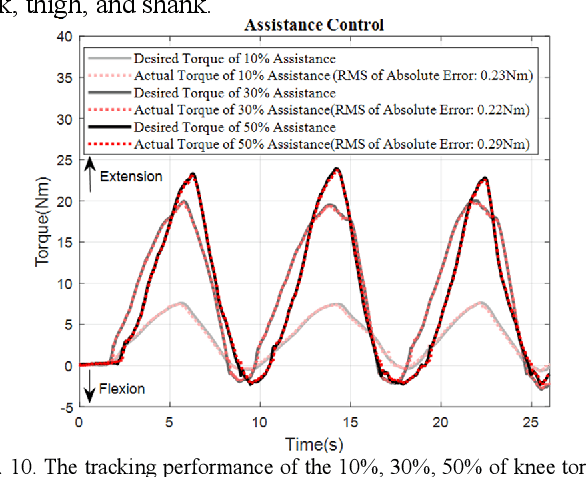
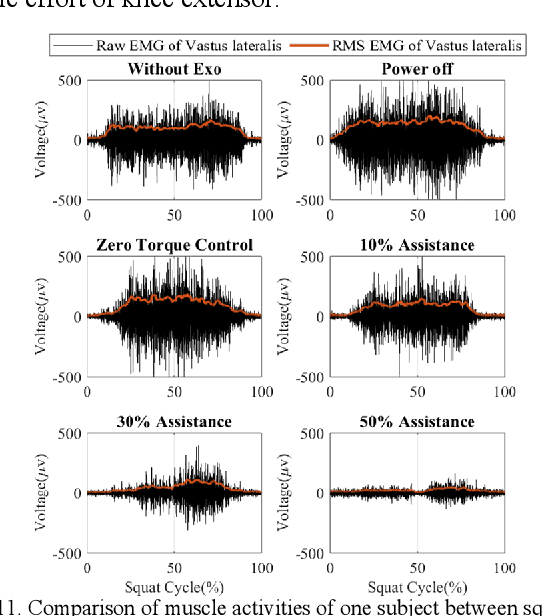
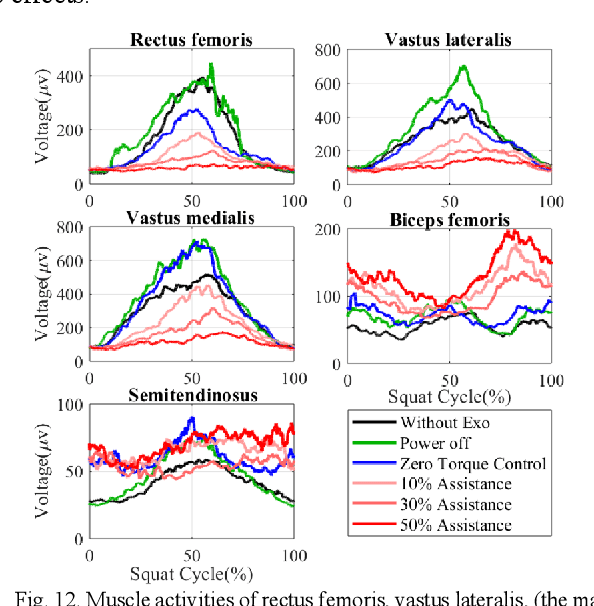
This paper presents a new design approach of wearable robots that tackle the three barriers to mainstay practical use of exoskeletons, namely discomfort, weight of the device, and symbiotic control of the exoskeleton-human co-robot system. The hybrid exoskeleton approach, demonstrated in a soft knee industrial exoskeleton case, mitigates the discomfort of wearers as it aims to avoid the drawbacks of rigid exoskeletons and textile-based soft exosuits. Quasi-direct drive actuation using high-torque density motors minimizes the weight of the device and presents high backdrivability that does not restrict natural movement. We derive a biomechanics model that is generic to both squat and stoop lifting motion. The control algorithm symbiotically detects posture using compact inertial measurement unit (IMU) sensors to generate an assistive profile that is proportional to the biological torque generated from our model. Experimental results demonstrate that the robot exhibits 1.5 Nm torque when it is unpowered and 0.5 Nm torque with zero-torque tracking control. The efficacy of injury prevention is demonstrated with one healthy subject. Root mean square (RMS) error of torque tracking is less than 0.29 Nm (1.21% of 24 Nm peak torque) for 50% assistance of biological torque. Comparing to the squat without exoskeleton, the maximum amplitude of the knee extensor muscle activity (rectus femoris) measured by Electromyography (EMG) sensors is reduced by 30% with 50% assistance of biological torque.
Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey
Feb 16, 2019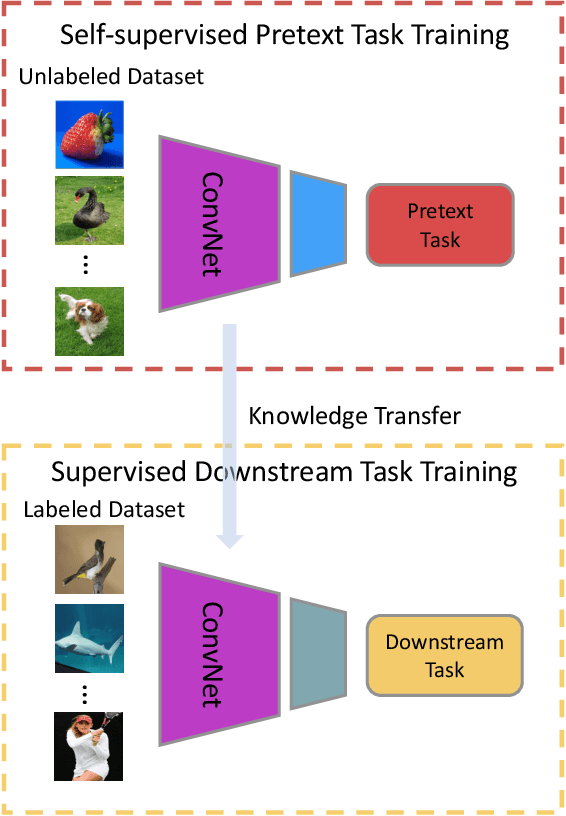
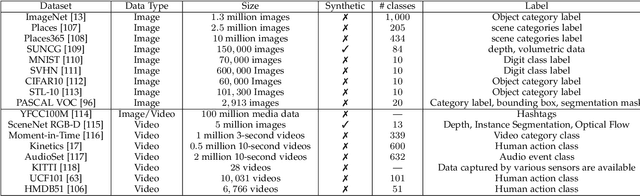
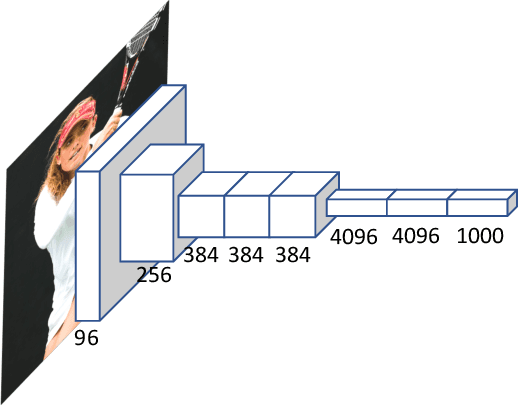
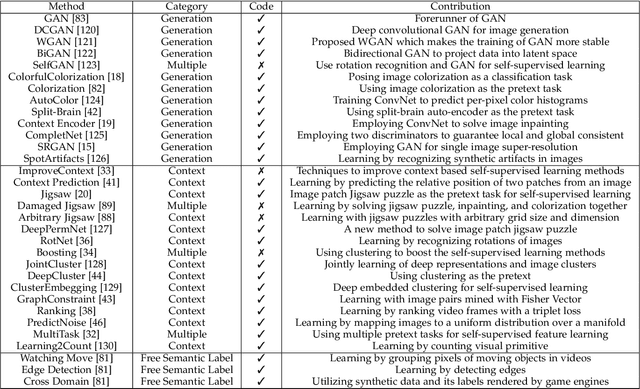
Large-scale labeled data are generally required to train deep neural networks in order to obtain better performance in visual feature learning from images or videos for computer vision applications. To avoid extensive cost of collecting and annotating large-scale datasets, as a subset of unsupervised learning methods, self-supervised learning methods are proposed to learn general image and video features from large-scale unlabeled data without using any human-annotated labels. This paper provides an extensive review of deep learning-based self-supervised general visual feature learning methods from images or videos. First, the motivation, general pipeline, and terminologies of this field are described. Then the common deep neural network architectures that used for self-supervised learning are summarized. Next, the main components and evaluation metrics of self-supervised learning methods are reviewed followed by the commonly used image and video datasets and the existing self-supervised visual feature learning methods. Finally, quantitative performance comparisons of the reviewed methods on benchmark datasets are summarized and discussed for both image and video feature learning. At last, this paper is concluded and lists a set of promising future directions for self-supervised visual feature learning.
LGAN: Lung Segmentation in CT Scans Using Generative Adversarial Network
Jan 11, 2019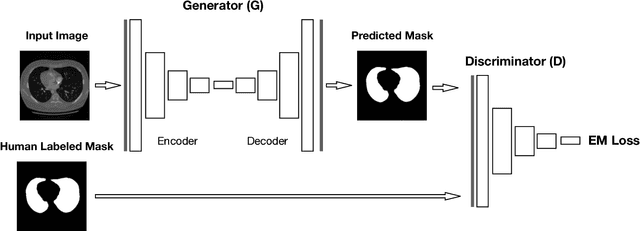
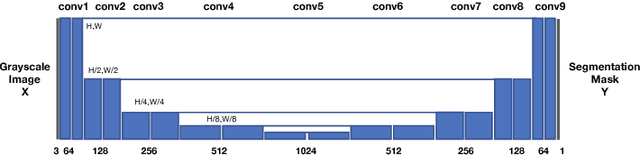
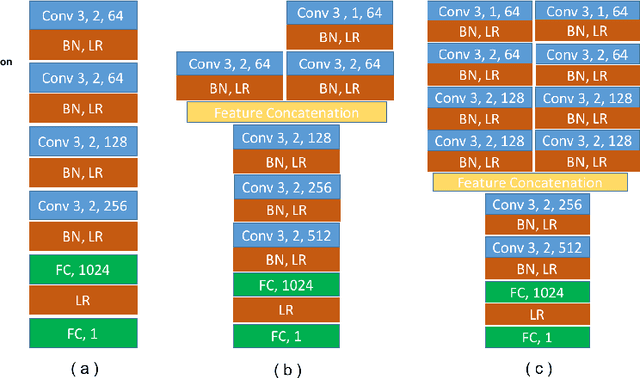
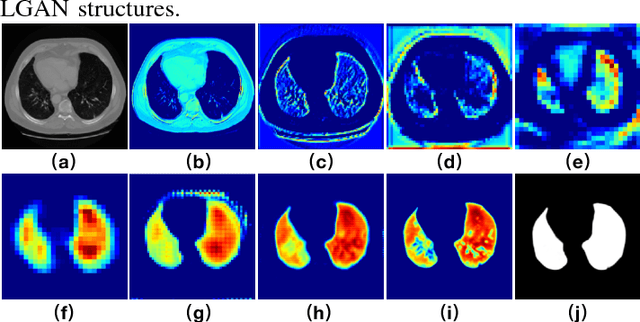
Lung segmentation in computerized tomography (CT) images is an important procedure in various lung disease diagnosis. Most of the current lung segmentation approaches are performed through a series of procedures with manually empirical parameter adjustments in each step. Pursuing an automatic segmentation method with fewer steps, in this paper, we propose a novel deep learning Generative Adversarial Network (GAN) based lung segmentation schema, which we denote as LGAN. Our proposed schema can be generalized to different kinds of neural networks for lung segmentation in CT images and is evaluated on a dataset containing 220 individual CT scans with two metrics: segmentation quality and shape similarity. Also, we compared our work with current state of the art methods. The results obtained with this study demonstrate that the proposed LGAN schema can be used as a promising tool for automatic lung segmentation due to its simplified procedure as well as its good performance.
Coarse-to-fine Semantic Segmentation from Image-level Labels
Dec 28, 2018
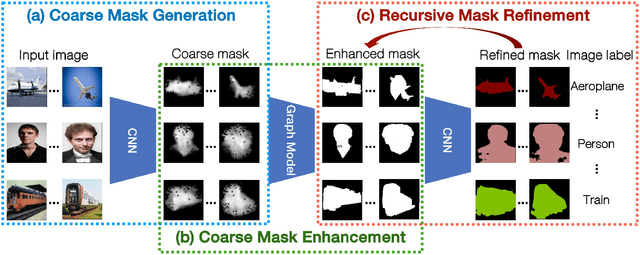
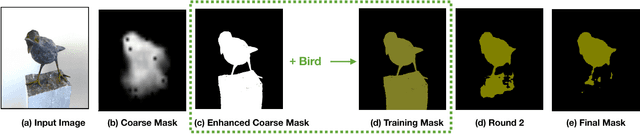

Deep neural network-based semantic segmentation generally requires large-scale cost extensive annotations for training to obtain better performance. To avoid pixel-wise segmentation annotations which are needed for most methods, recently some researchers attempted to use object-level labels (e.g. bounding boxes) or image-level labels (e.g. image categories). In this paper, we propose a novel recursive coarse-to-fine semantic segmentation framework based on only image-level category labels. For each image, an initial coarse mask is first generated by a convolutional neural network-based unsupervised foreground segmentation model and then is enhanced by a graph model. The enhanced coarse mask is fed to a fully convolutional neural network to be recursively refined. Unlike existing image-level label-based semantic segmentation methods which require to label all categories for images contain multiple types of objects, our framework only needs one label for each image and can handle images contains multi-category objects. With only trained on ImageNet, our framework achieves comparable performance on PASCAL VOC dataset as other image-level label-based state-of-the-arts of semantic segmentation. Furthermore, our framework can be easily extended to foreground object segmentation task and achieves comparable performance with the state-of-the-art supervised methods on the Internet Object dataset.
Discovering Spatio-Temporal Action Tubes
Nov 29, 2018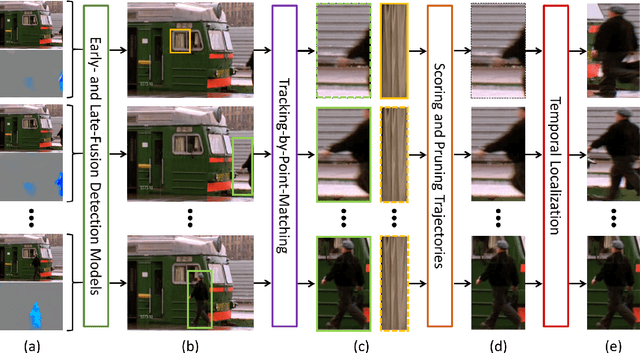
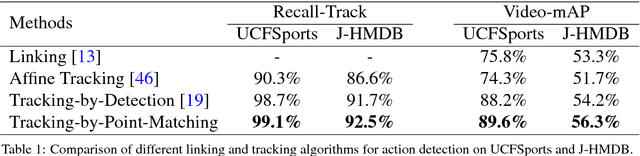
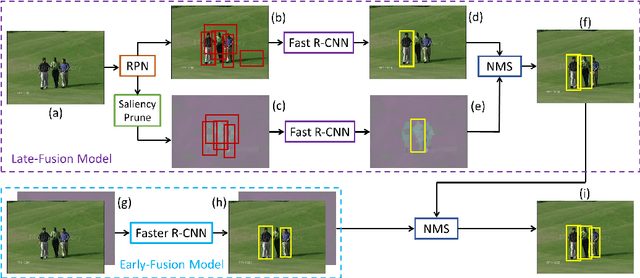
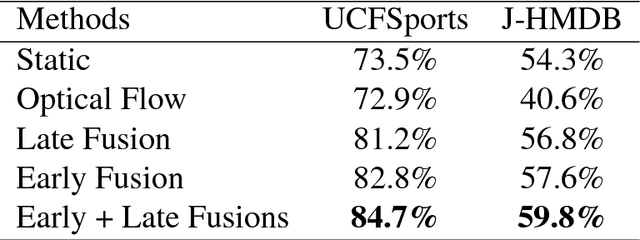
In this paper, we address the challenging problem of spatial and temporal action detection in videos. We first develop an effective approach to localize frame-level action regions through integrating static and kinematic information by the early- and late-fusion detection scheme. With the intention of exploring important temporal connections among the detected action regions, we propose a tracking-by-point-matching algorithm to stitch the discrete action regions into a continuous spatio-temporal action tube. Recurrent 3D convolutional neural network is used to predict action categories and determine temporal boundaries of the generated tubes. We then introduce an action footprint map to refine the candidate tubes based on the action-specific spatial characteristics preserved in the convolutional layers of R3DCNN. In the extensive experiments, our method achieves superior detection results on the three public benchmark datasets: UCFSports, J-HMDB and UCF101.
Self-supervised Spatiotemporal Feature Learning by Video Geometric Transformations
Nov 28, 2018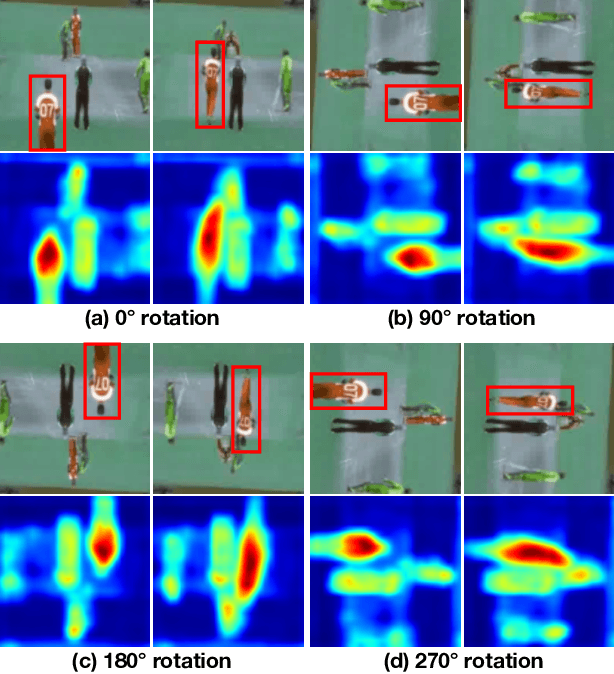
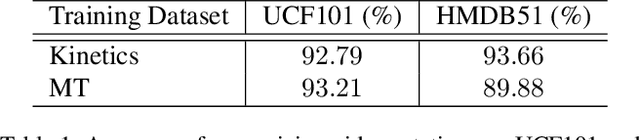
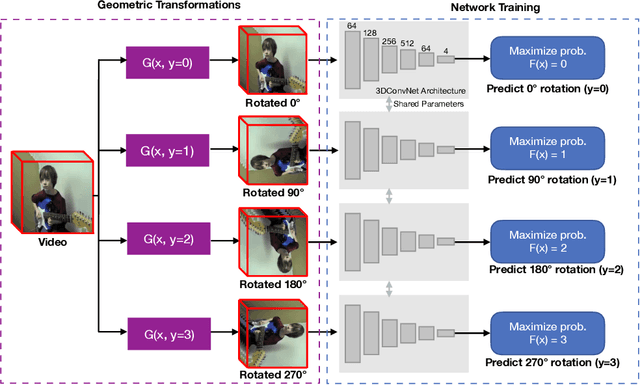

To alleviate the expensive cost of data collection and annotation, many self-supervised learning methods were proposed to learn image representations without human-labeled annotations. However, self-supervised learning for video representations is not yet well-addressed. In this paper, we propose a novel 3DConvNet-based fully self-supervised framework to learn spatiotemporal video features without using any human-labeled annotations. First, a set of pre-designed geometric transformations (e.g. rotating 0 degree, 90 degrees, 180 degrees, and 270 degrees) are applied to each video. Then a pretext task can be defined as "recognizing the pre-designed geometric transformations." Therefore, the spatiotemporal video features can be learned in the process of accomplishing this pretext task without using human-labeled annotations. The learned spatiotemporal video representations can further be employed as pretrained features for different video-related applications. The proposed geometric transformations (e.g. rotations) are proved to be effective to learn representative spatiotemporal features in our 3DConvNet-based fully self-supervised framework. With the pre-trained spatiotemporal features from two large video datasets, the performance of action recognition is significantly boosted up by 20.4% on UCF101 dataset and 16.7% on HMDB51 dataset respectively compared to that from the model trained from scratch. Furthermore, our framework outperforms the state-of-the-arts of fully self-supervised methods on both UCF101 and HMDB51 datasets and achieves 62.9% and 33.7% accuracy respectively.
Self-Guiding Multimodal LSTM - when we do not have a perfect training dataset for image captioning
Sep 15, 2017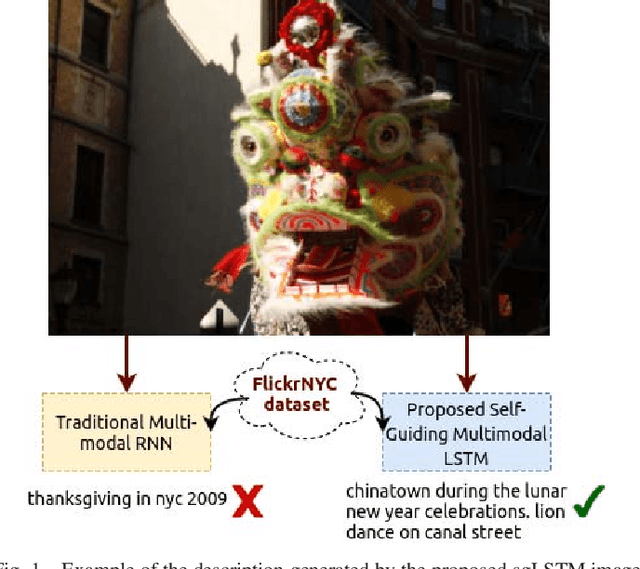

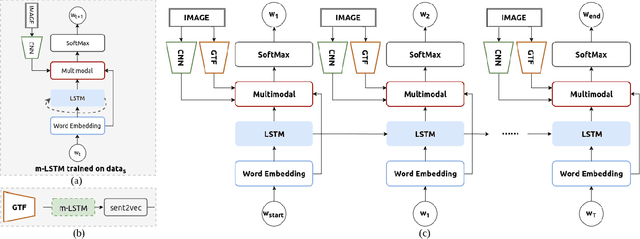

In this paper, a self-guiding multimodal LSTM (sg-LSTM) image captioning model is proposed to handle uncontrolled imbalanced real-world image-sentence dataset. We collect FlickrNYC dataset from Flickr as our testbed with 306,165 images and the original text descriptions uploaded by the users are utilized as the ground truth for training. Descriptions in FlickrNYC dataset vary dramatically ranging from short term-descriptions to long paragraph-descriptions and can describe any visual aspects, or even refer to objects that are not depicted. To deal with the imbalanced and noisy situation and to fully explore the dataset itself, we propose a novel guiding textual feature extracted utilizing a multimodal LSTM (m-LSTM) model. Training of m-LSTM is based on the portion of data in which the image content and the corresponding descriptions are strongly bonded. Afterwards, during the training of sg-LSTM on the rest training data, this guiding information serves as additional input to the network along with the image representations and the ground-truth descriptions. By integrating these input components into a multimodal block, we aim to form a training scheme with the textual information tightly coupled with the image content. The experimental results demonstrate that the proposed sg-LSTM model outperforms the traditional state-of-the-art multimodal RNN captioning framework in successfully describing the key components of the input images.