 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Guiding Multimodal LSTM - when we do not have a perfect training dataset for image captioning
Sep 15, 2017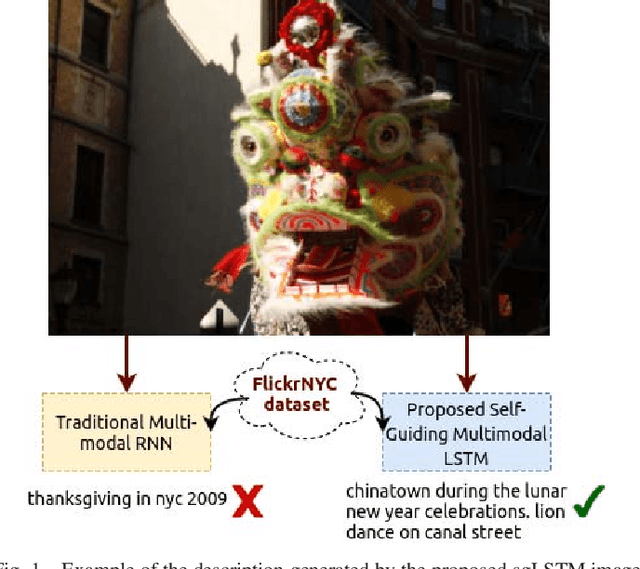

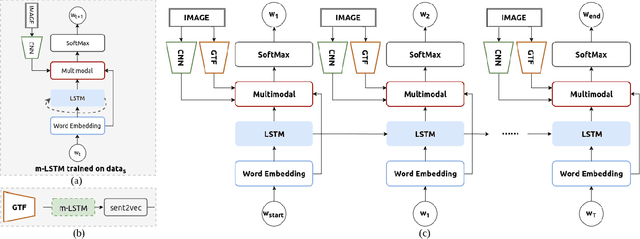

In this paper, a self-guiding multimodal LSTM (sg-LSTM) image captioning model is proposed to handle uncontrolled imbalanced real-world image-sentence dataset. We collect FlickrNYC dataset from Flickr as our testbed with 306,165 images and the original text descriptions uploaded by the users are utilized as the ground truth for training. Descriptions in FlickrNYC dataset vary dramatically ranging from short term-descriptions to long paragraph-descriptions and can describe any visual aspects, or even refer to objects that are not depicted. To deal with the imbalanced and noisy situation and to fully explore the dataset itself, we propose a novel guiding textual feature extracted utilizing a multimodal LSTM (m-LSTM) model. Training of m-LSTM is based on the portion of data in which the image content and the corresponding descriptions are strongly bonded. Afterwards, during the training of sg-LSTM on the rest training data, this guiding information serves as additional input to the network along with the image representations and the ground-truth descriptions. By integrating these input components into a multimodal block, we aim to form a training scheme with the textual information tightly coupled with the image content. The experimental results demonstrate that the proposed sg-LSTM model outperforms the traditional state-of-the-art multimodal RNN captioning framework in successfully describing the key components of the input images.