 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Spatiotemporal Feature Learning by Video Geometric Transformations
Paper and Code
Nov 28, 2018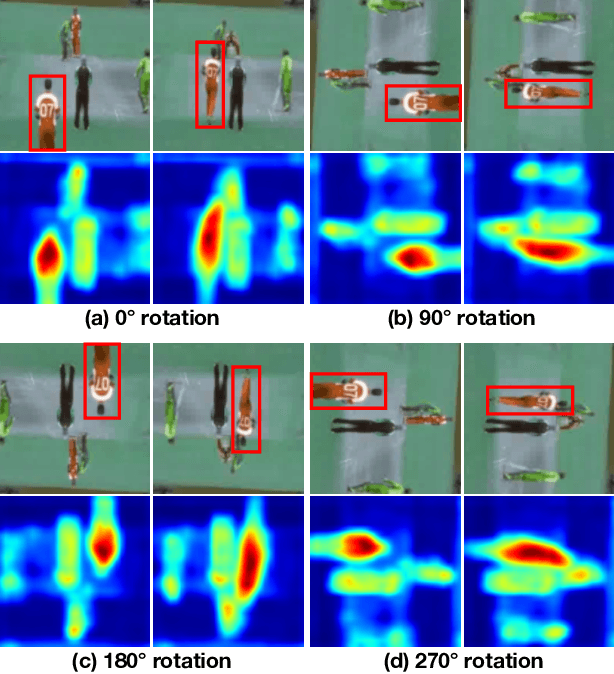
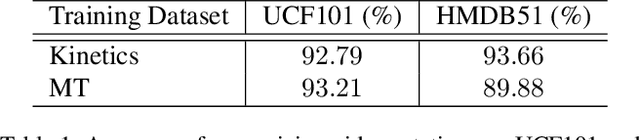
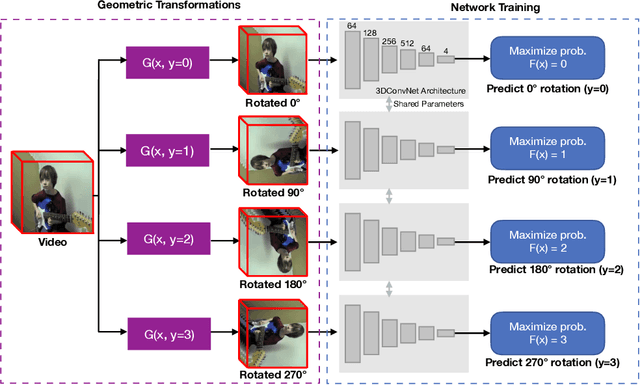

To alleviate the expensive cost of data collection and annotation, many self-supervised learning methods were proposed to learn image representations without human-labeled annotations. However, self-supervised learning for video representations is not yet well-addressed. In this paper, we propose a novel 3DConvNet-based fully self-supervised framework to learn spatiotemporal video features without using any human-labeled annotations. First, a set of pre-designed geometric transformations (e.g. rotating 0 degree, 90 degrees, 180 degrees, and 270 degrees) are applied to each video. Then a pretext task can be defined as "recognizing the pre-designed geometric transformations." Therefore, the spatiotemporal video features can be learned in the process of accomplishing this pretext task without using human-labeled annotations. The learned spatiotemporal video representations can further be employed as pretrained features for different video-related applications. The proposed geometric transformations (e.g. rotations) are proved to be effective to learn representative spatiotemporal features in our 3DConvNet-based fully self-supervised framework. With the pre-trained spatiotemporal features from two large video datasets, the performance of action recognition is significantly boosted up by 20.4% on UCF101 dataset and 16.7% on HMDB51 dataset respectively compared to that from the model trained from scratch. Furthermore, our framework outperforms the state-of-the-arts of fully self-supervised methods on both UCF101 and HMDB51 datasets and achieves 62.9% and 33.7% accuracy respectively.