 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness Research For Machine Learning Should Integrate Societal Considerations
Jun 14, 2025Enhancing fairness in machine learning (ML) systems is increasingly important nowadays. While current research focuses on assistant tools for ML pipelines to promote fairness within them, we argue that: 1) The significance of properly defined fairness measures remains underestimated; and 2) Fairness research in ML should integrate societal considerations. The reasons include that detecting discrimination is critical due to the widespread deployment of ML systems and that human-AI feedback loops amplify biases, even when only small social and political biases persist.
FairSHAP: Preprocessing for Fairness Through Attribution-Based Data Augmentation
May 16, 2025



Ensuring fairness in machine learning models is critical, particularly in high-stakes domains where biased decisions can lead to serious societal consequences. Existing preprocessing approaches generally lack transparent mechanisms for identifying which features or instances are responsible for unfairness. This obscures the rationale behind data modifications. We introduce FairSHAP, a novel pre-processing framework that leverages Shapley value attribution to improve both individual and group fairness. FairSHAP identifies fairness-critical instances in the training data using an interpretable measure of feature importance, and systematically modifies them through instance-level matching across sensitive groups. This process reduces discriminative risk - an individual fairness metric - while preserving data integrity and model accuracy. We demonstrate that FairSHAP significantly improves demographic parity and equality of opportunity across diverse tabular datasets, achieving fairness gains with minimal data perturbation and, in some cases, improved predictive performance. As a model-agnostic and transparent method, FairSHAP integrates seamlessly into existing machine learning pipelines and provides actionable insights into the sources of bias.Our code is on https://github.com/youlei202/FairSHAP.
Towards Trustworthy Federated Learning
Mar 05, 2025



This paper develops a comprehensive framework to address three critical trustworthy challenges in federated learning (FL): robustness against Byzantine attacks, fairness, and privacy preservation. To improve the system's defense against Byzantine attacks that send malicious information to bias the system's performance, we develop a Two-sided Norm Based Screening (TNBS) mechanism, which allows the central server to crop the gradients that have the l lowest norms and h highest norms. TNBS functions as a screening tool to filter out potential malicious participants whose gradients are far from the honest ones. To promote egalitarian fairness, we adopt the q-fair federated learning (q-FFL). Furthermore, we adopt a differential privacy-based scheme to prevent raw data at local clients from being inferred by curious parties. Convergence guarantees are provided for the proposed framework under different scenarios. Experimental results on real datasets demonstrate that the proposed framework effectively improves robustness and fairness while managing the trade-off between privacy and accuracy. This work appears to be the first study that experimentally and theoretically addresses fairness, privacy, and robustness in trustworthy FL.
Refining Counterfactual Explanations With Joint-Distribution-Informed Shapley Towards Actionable Minimality
Oct 07, 2024Counterfactual explanations (CE) identify data points that closely resemble the observed data but produce different machine learning (ML) model outputs, offering critical insights into model decisions. Despite the diverse scenarios, goals and tasks to which they are tailored, existing CE methods often lack actionable efficiency because of unnecessary feature changes included within the explanations that are presented to users and stakeholders. We address this problem by proposing a method that minimizes the required feature changes while maintaining the validity of CE, without imposing restrictions on models or CE algorithms, whether instance- or group-based. The key innovation lies in computing a joint distribution between observed and counterfactual data and leveraging it to inform Shapley values for feature attributions (FA). We demonstrate that optimal transport (OT) effectively derives this distribution, especially when the alignment between observed and counterfactual data is unclear in used CE methods. Additionally, a counterintuitive finding is uncovered: it may be misleading to rely on an exact alignment defined by the CE generation mechanism in conducting FA. Our proposed method is validated on extensive experiments across multiple datasets, showcasing its effectiveness in refining CE towards greater actionable efficiency.
Approximating Discrimination Within Models When Faced With Several Non-Binary Sensitive Attributes
Aug 12, 2024Discrimination mitigation with machine learning (ML) models could be complicated because multiple factors may interweave with each other including hierarchically and historically. Yet few existing fairness measures are able to capture the discrimination level within ML models in the face of multiple sensitive attributes. To bridge this gap, we propose a fairness measure based on distances between sets from a manifold perspective, named as 'harmonic fairness measure via manifolds (HFM)' with two optional versions, which can deal with a fine-grained discrimination evaluation for several sensitive attributes of multiple values. To accelerate the computation of distances of sets, we further propose two approximation algorithms named 'Approximation of distance between sets for one sensitive attribute with multiple values (ApproxDist)' and 'Approximation of extended distance between sets for several sensitive attributes with multiple values (ExtendDist)' to respectively resolve bias evaluation of one single sensitive attribute with multiple values and that of several sensitive attributes with multiple values. Moreover, we provide an algorithmic effectiveness analysis for ApproxDist under certain assumptions to explain how well it could work. The empirical results demonstrate that our proposed fairness measure HFM is valid and approximation algorithms (i.e., ApproxDist and ExtendDist) are effective and efficient.
Does Machine Bring in Extra Bias in Learning? Approximating Fairness in Models Promptly
May 15, 2024



Providing various machine learning (ML) applications in the real world, concerns about discrimination hidden in ML models are growing, particularly in high-stakes domains. Existing techniques for assessing the discrimination level of ML models include commonly used group and individual fairness measures. However, these two types of fairness measures are usually hard to be compatible with each other, and even two different group fairness measures might be incompatible as well. To address this issue, we investigate to evaluate the discrimination level of classifiers from a manifold perspective and propose a "harmonic fairness measure via manifolds (HFM)" based on distances between sets. Yet the direct calculation of distances might be too expensive to afford, reducing its practical applicability. Therefore, we devise an approximation algorithm named "Approximation of distance between sets (ApproxDist)" to facilitate accurate estimation of distances, and we further demonstrate its algorithmic effectiveness under certain reasonable assumptions. Empirical results indicate that the proposed fairness measure HFM is valid and that the proposed ApproxDist is effective and efficient.
Advancing Graph Neural Networks with HL-HGAT: A Hodge-Laplacian and Attention Mechanism Approach for Heterogeneous Graph-Structured Data
Mar 11, 2024



Graph neural networks (GNNs) have proven effective in capturing relationships among nodes in a graph. This study introduces a novel perspective by considering a graph as a simplicial complex, encompassing nodes, edges, triangles, and $k$-simplices, enabling the definition of graph-structured data on any $k$-simplices. Our contribution is the Hodge-Laplacian heterogeneous graph attention network (HL-HGAT), designed to learn heterogeneous signal representations across $k$-simplices. The HL-HGAT incorporates three key components: HL convolutional filters (HL-filters), simplicial projection (SP), and simplicial attention pooling (SAP) operators, applied to $k$-simplices. HL-filters leverage the unique topology of $k$-simplices encoded by the Hodge-Laplacian (HL) operator, operating within the spectral domain of the $k$-th HL operator. To address computation challenges, we introduce a polynomial approximation for HL-filters, exhibiting spatial localization properties. Additionally, we propose a pooling operator to coarsen $k$-simplices, combining features through simplicial attention mechanisms of self-attention and cross-attention via transformers and SP operators, capturing topological interconnections across multiple dimensions of simplices. The HL-HGAT is comprehensively evaluated across diverse graph applications, including NP-hard problems, graph multi-label and classification challenges, and graph regression tasks in logistics, computer vision, biology, chemistry, and neuroscience. The results demonstrate the model's efficacy and versatility in handling a wide range of graph-based scenarios.
Increasing Fairness in Compromise on Accuracy via Weighted Vote with Learning Guarantees
Jan 25, 2023As the bias issue is being taken more and more seriously in widely applied machine learning systems, the decrease in accuracy in most cases deeply disturbs researchers when increasing fairness. To address this problem, we present a novel analysis of the expected fairness quality via weighted vote, suitable for both binary and multi-class classification. The analysis takes the correction of biased predictions by ensemble members into account and provides learning bounds that are amenable to efficient minimisation. We further propose a pruning method based on this analysis and the concepts of domination and Pareto optimality, which is able to increase fairness under a prerequisite of little or even no accuracy decline. The experimental results indicate that the proposed learning bounds are faithful and that the proposed pruning method can indeed increase ensemble fairness without much accuracy degradation.
Adversarial Patch Attacks and Defences in Vision-Based Tasks: A Survey
Jun 16, 2022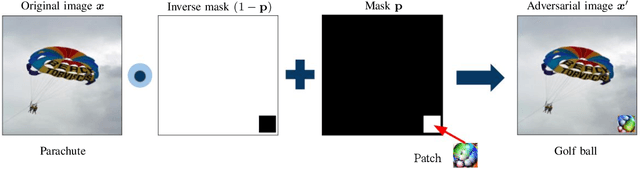


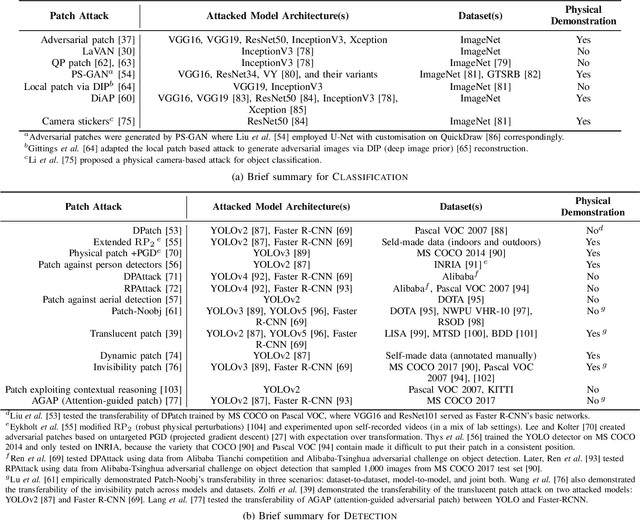
Adversarial attacks in deep learning models, especially for safety-critical systems, are gaining more and more attention in recent years, due to the lack of trust in the security and robustness of AI models. Yet the more primitive adversarial attacks might be physically infeasible or require some resources that are hard to access like the training data, which motivated the emergence of patch attacks. In this survey, we provide a comprehensive overview to cover existing techniques of adversarial patch attacks, aiming to help interested researchers quickly catch up with the progress in this field. We also discuss existing techniques for developing detection and defences against adversarial patches, aiming to help the community better understand this field and its applications in the real world.
When does Diversity Help Generalization in Classification Ensembles?
Oct 30, 2019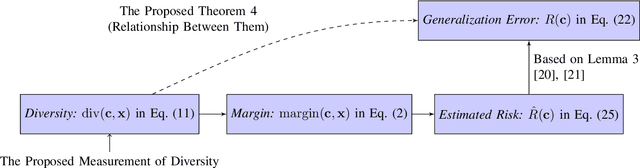
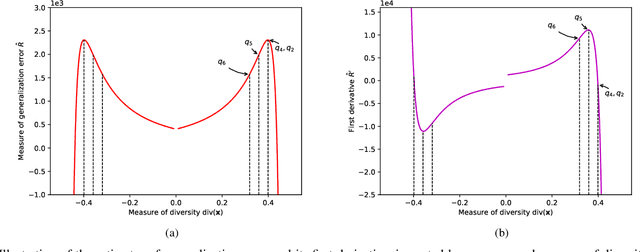
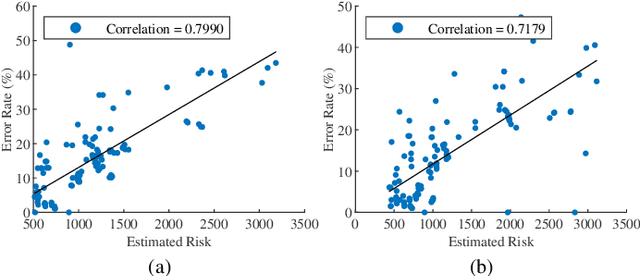
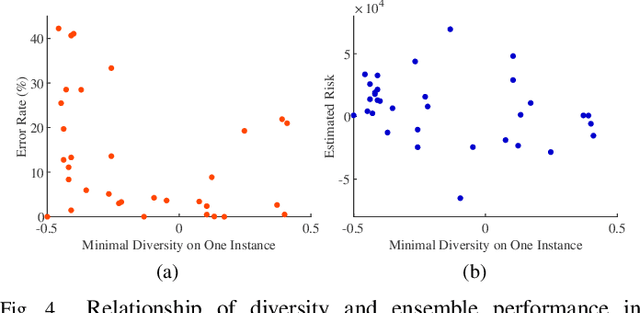
Ensembles, as a widely used and effective technique in the machine learning community, succeed within a key element--"diversity." The relationship between diversity and generalization, unfortunately, is not entirely understood and remains an open research issue. To reveal the effect of diversity on the generalization of classification ensembles, we investigate three issues on diversity, i.e., the measurement of diversity, the relationship between the proposed diversity and generalization error, and the utilization of this relationship for ensemble pruning. In the diversity measurement, we measure diversity by error decomposition inspired by regression ensembles, which decomposes the error of classification ensembles into accuracy and diversity. Then we formulate the relationship between the measured diversity and ensemble performance through the theorem of margin and generalization, and observe that the generalization error is reduced effectively only when the measured diversity is increased in a few specific ranges, while in other ranges larger diversity is less beneficial to increase generalization of an ensemble. Besides, we propose a pruning method based on diversity management to utilize this relationship, which could increase diversity appropriately and shrink the size of the ensemble with non-decreasing performance. The experiments validate the effectiveness of this proposed relationship between the proposed diversity and the ensemble generalization error.