 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Score Expansion with Variable-Length Infilling
Nov 11, 2021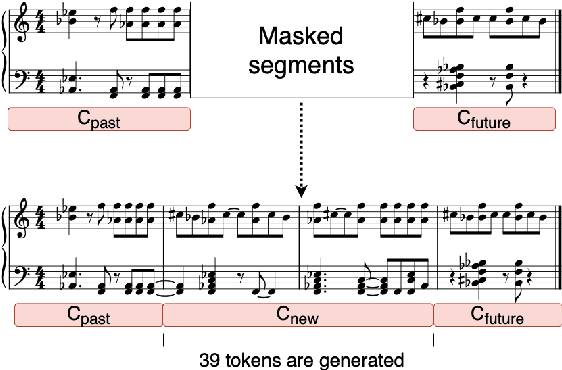
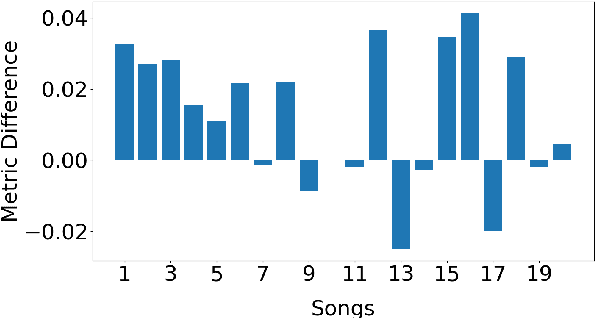
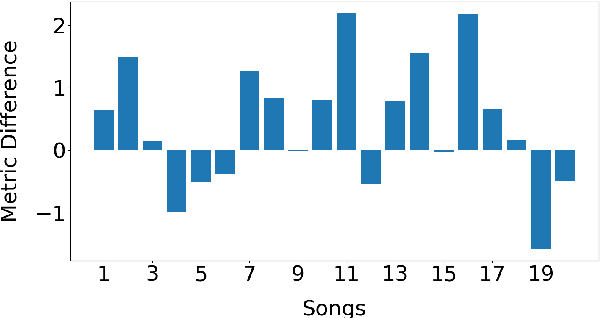
In this paper, we investigate using the variable-length infilling (VLI) model, which is originally proposed to infill missing segments, to "prolong" existing musical segments at musical boundaries. Specifically, as a case study, we expand 20 musical segments from 12 bars to 16 bars, and examine the degree to which the VLI model preserves musical boundaries in the expanded results using a few objective metrics, including the Register Histogram Similarity we newly propose. The results show that the VLI model has the potential to address the expansion task.
Theme Transformer: Symbolic Music Generation with Theme-Conditioned Transformer
Nov 07, 2021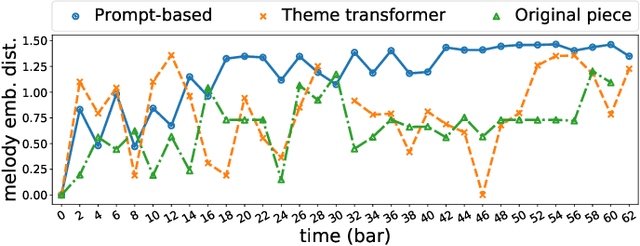
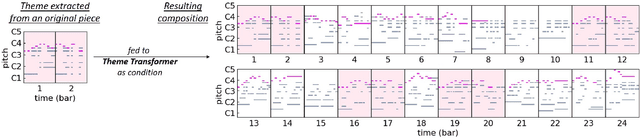
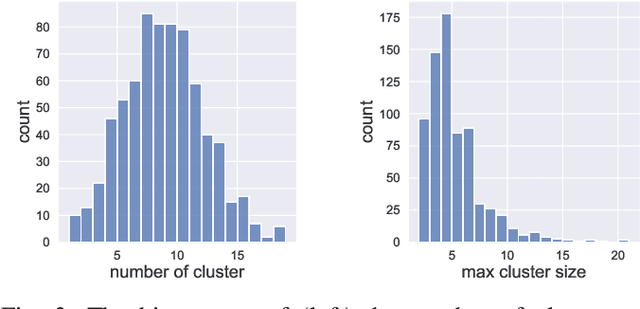
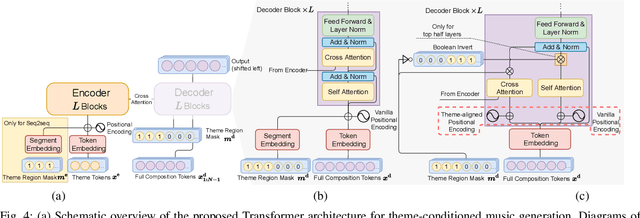
Attention-based Transformer models have been increasingly employed for automatic music generation. To condition the generation process of such a model with a user-specified sequence, a popular approach is to take that conditioning sequence as a priming sequence and ask a Transformer decoder to generate a continuation. However, this prompt-based conditioning cannot guarantee that the conditioning sequence would develop or even simply repeat itself in the generated continuation. In this paper, we propose an alternative conditioning approach, called theme-based conditioning, that explicitly trains the Transformer to treat the conditioning sequence as a thematic material that has to manifest itself multiple times in its generation result. This is achieved with two main technical contributions. First, we propose a deep learning-based approach that uses contrastive representation learning and clustering to automatically retrieve thematic materials from music pieces in the training data. Second, we propose a novel gated parallel attention module to be used in a sequence-to-sequence (seq2seq) encoder/decoder architecture to more effectively account for a given conditioning thematic material in the generation process of the Transformer decoder. We report on objective and subjective evaluations of variants of the proposed Theme Transformer and the conventional prompt-based baseline, showing that our best model can generate, to some extent, polyphonic pop piano music with repetition and plausible variations of a given condition.
Learning To Generate Piano Music With Sustain Pedals
Nov 01, 2021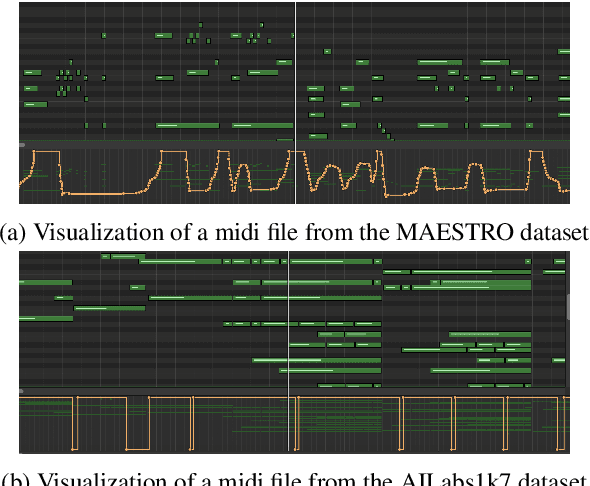
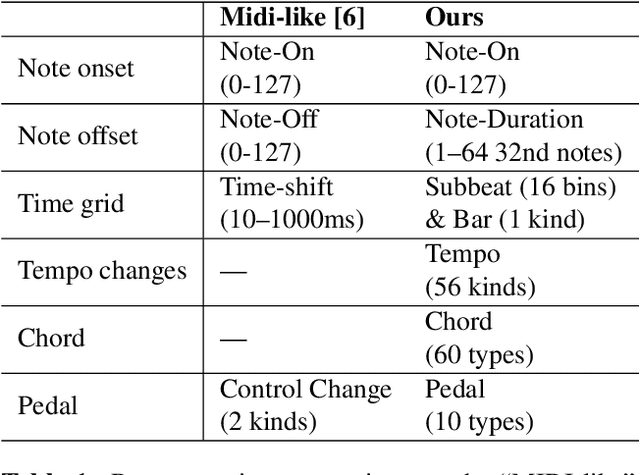
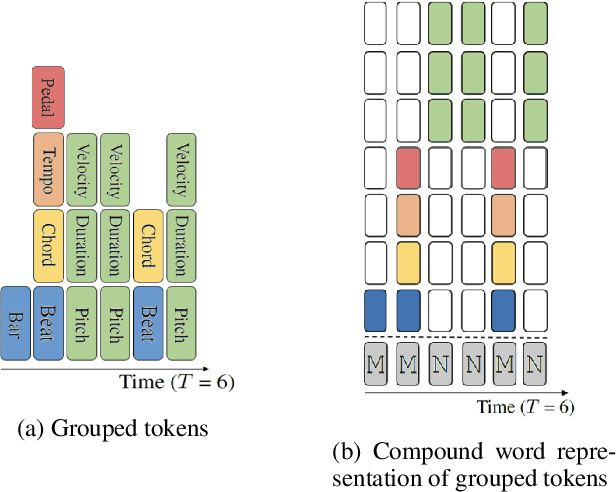
Recent years have witnessed a growing interest in research related to the detection of piano pedals from audio signals in the music information retrieval community. However, to our best knowledge, recent generative models for symbolic music have rarely taken piano pedals into account. In this work, we employ the transcription model proposed by Kong et al. to get pedal information from the audio recordings of piano performance in the AILabs1k7 dataset, and then modify the Compound Word Transformer proposed by Hsiao et al. to build a Transformer decoder that generates pedal-related tokens along with other musical tokens. While the work is done by using inferred sustain pedal information as training data, the result shows hope for further improvement and the importance of the involvement of sustain pedal in tasks of piano performance generations.
Deep Learning Based EDM Subgenre Classification using Mel-Spectrogram and Tempogram Features
Oct 17, 2021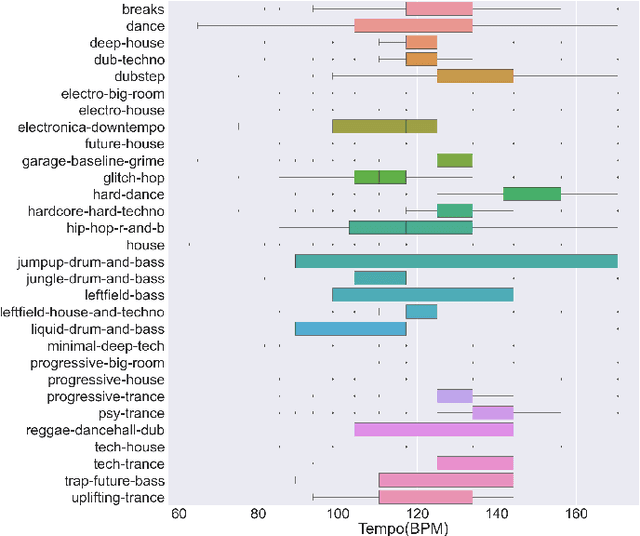
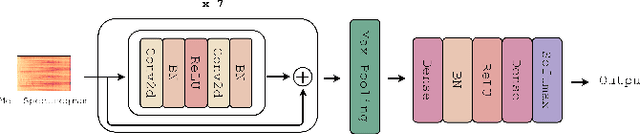
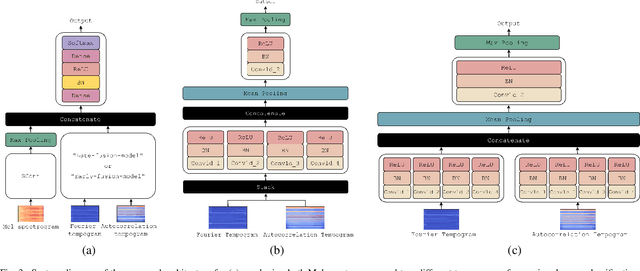
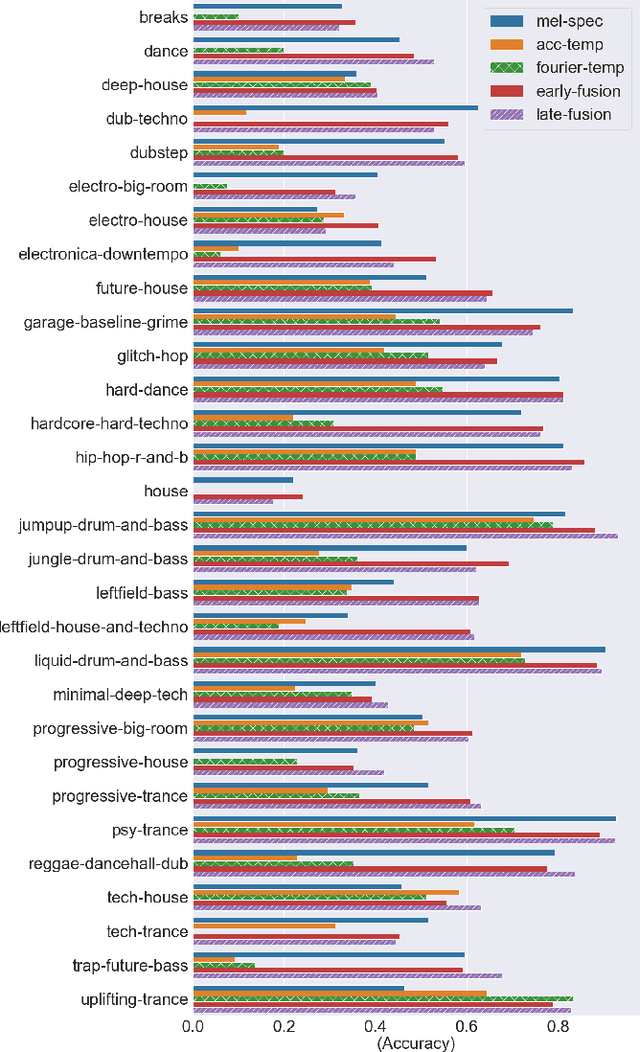
Along with the evolution of music technology, a large number of styles, or "subgenres," of Electronic Dance Music(EDM) have emerged in recent years. While the classification task of distinguishing between EDM and non-EDM has been often studied in the context of music genre classification, little work has been done on the more challenging EDM subgenre classification. The state-of-art model is based on extremely randomized trees and could be improved by deep learning methods. In this paper, we extend the state-of-art music auto-tagging model "short-chunkCNN+Resnet" to EDM subgenre classification, with the addition of two mid-level tempo-related feature representations, called the Fourier tempogram and autocorrelation tempogram. And, we explore two fusion strategies, early fusion and late fusion, to aggregate the two types of tempograms. We evaluate the proposed models using a large dataset consisting of 75,000 songs for 30 different EDM subgenres, and show that the adoption of deep learning models and tempo features indeed leads to higher classification accuracy.
Automatic DJ Transitions with Differentiable Audio Effects and Generative Adversarial Networks
Oct 13, 2021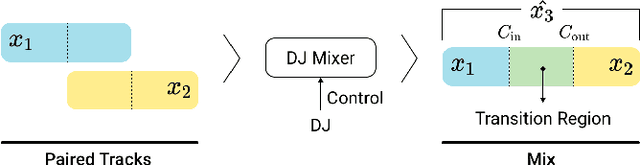
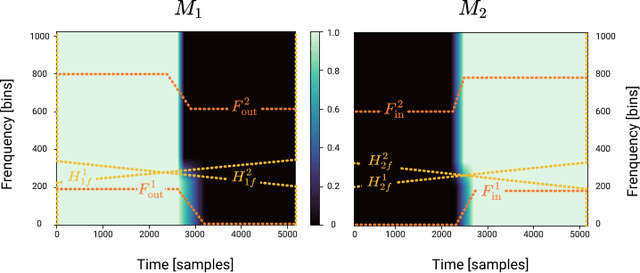
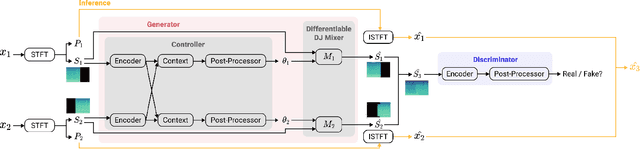

A central task of a Disc Jockey (DJ) is to create a mixset of mu-sic with seamless transitions between adjacent tracks. In this paper, we explore a data-driven approach that uses a generative adversarial network to create the song transition by learning from real-world DJ mixes. In particular, the generator of the model uses two differentiable digital signal processing components, an equalizer (EQ) and a fader, to mix two tracks selected by a data generation pipeline. The generator has to set the parameters of the EQs and fader in such away that the resulting mix resembles real mixes created by humanDJ, as judged by the discriminator counterpart. Result of a listening test shows that the model can achieve competitive results compared with a number of baselines.
KaraSinger: Score-Free Singing Voice Synthesis with VQ-VAE using Mel-spectrograms
Oct 08, 2021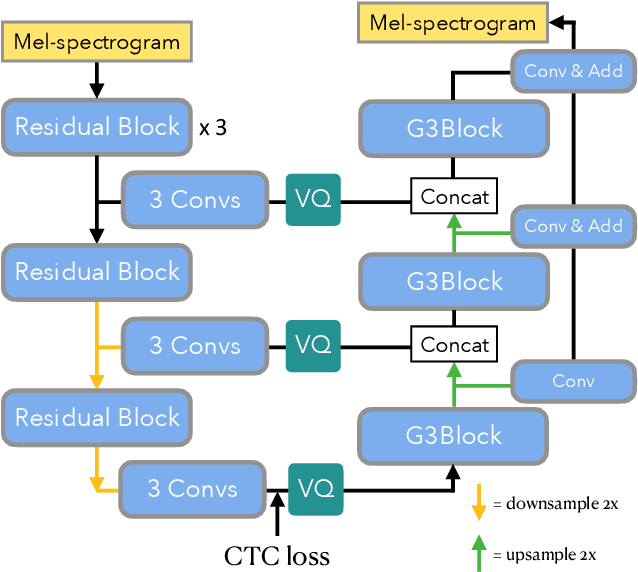
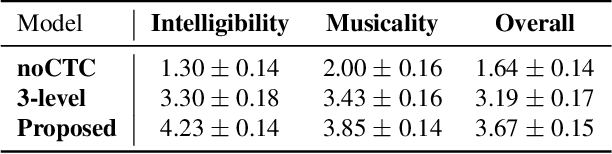
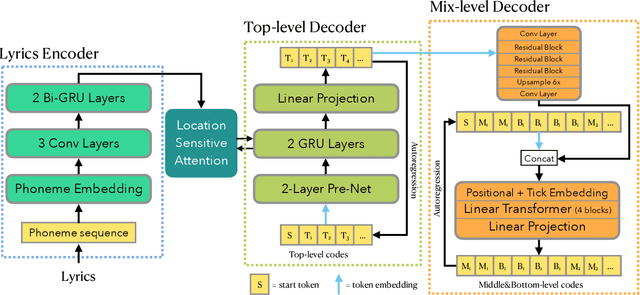

In this paper, we propose a novel neural network model called KaraSinger for a less-studied singing voice synthesis (SVS) task named score-free SVS, in which the prosody and melody are spontaneously decided by machine. KaraSinger comprises a vector-quantized variational autoencoder (VQ-VAE) that compresses the Mel-spectrograms of singing audio to sequences of discrete codes, and a language model (LM) that learns to predict the discrete codes given the corresponding lyrics. For the VQ-VAE part, we employ a Connectionist Temporal Classification (CTC) loss to encourage the discrete codes to carry phoneme-related information. For the LM part, we use location-sensitive attention for learning a robust alignment between the input phoneme sequence and the output discrete code. We keep the architecture of both the VQ-VAE and LM light-weight for fast training and inference speed. We validate the effectiveness of the proposed design choices using a proprietary collection of 550 English pop songs sung by multiple amateur singers. The result of a listening test shows that KaraSinger achieves high scores in intelligibility, musicality, and the overall quality.
Variable-Length Music Score Infilling via XLNet and Musically Specialized Positional Encoding
Aug 11, 2021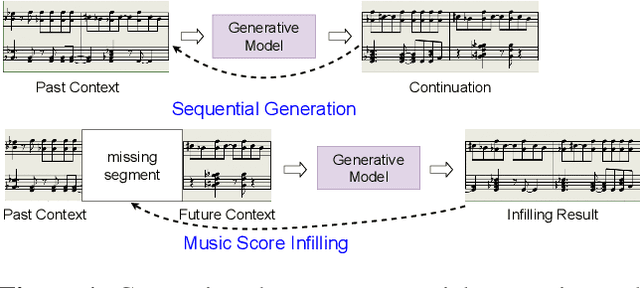
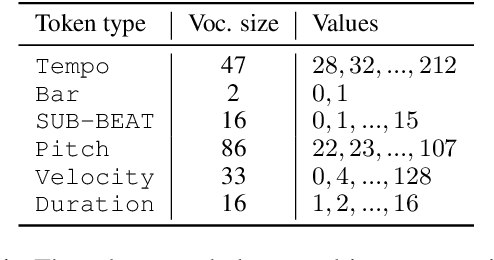
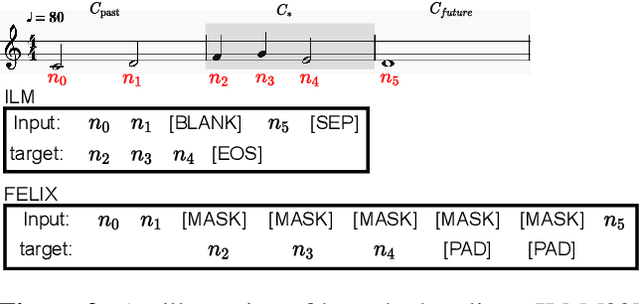

This paper proposes a new self-attention based model for music score infilling, i.e., to generate a polyphonic music sequence that fills in the gap between given past and future contexts. While existing approaches can only fill in a short segment with a fixed number of notes, or a fixed time span between the past and future contexts, our model can infill a variable number of notes (up to 128) for different time spans. We achieve so with three major technical contributions. First, we adapt XLNet, an autoregressive model originally proposed for unsupervised model pre-training, to music score infilling. Second, we propose a new, musically specialized positional encoding called relative bar encoding that better informs the model of notes' position within the past and future context. Third, to capitalize relative bar encoding, we perform look-ahead onset prediction to predict the onset of a note one time step before predicting the other attributes of the note. We compare our proposed model with two strong baselines and show that our model is superior in both objective and subjective analyses.
A Benchmarking Initiative for Audio-Domain Music Generation Using the Freesound Loop Dataset
Aug 03, 2021
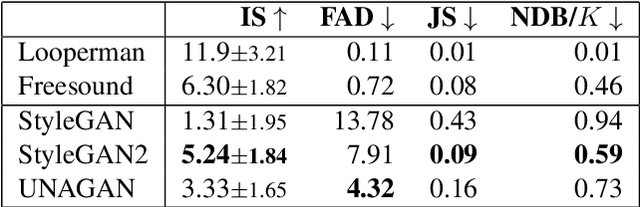
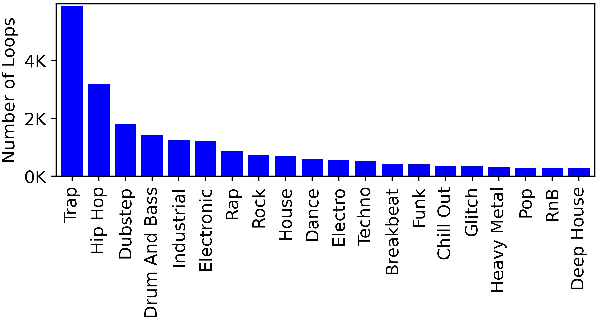

This paper proposes a new benchmark task for generat-ing musical passages in the audio domain by using thedrum loops from the FreeSound Loop Dataset, which arepublicly re-distributable. Moreover, we use a larger col-lection of drum loops from Looperman to establish fourmodel-based objective metrics for evaluation, releasingthese metrics as a library for quantifying and facilitatingthe progress of musical audio generation. Under this eval-uation framework, we benchmark the performance of threerecent deep generative adversarial network (GAN) mod-els we customize to generate loops, including StyleGAN,StyleGAN2, and UNAGAN. We also report a subjectiveevaluation of these models. Our evaluation shows that theone based on StyleGAN2 performs the best in both objec-tive and subjective metrics.
EMOPIA: A Multi-Modal Pop Piano Dataset For Emotion Recognition and Emotion-based Music Generation
Aug 03, 2021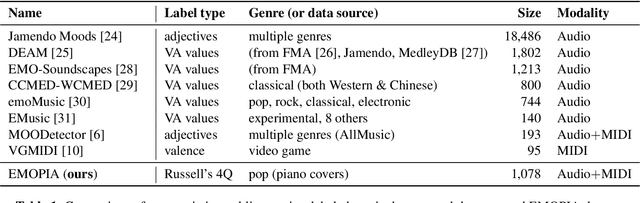
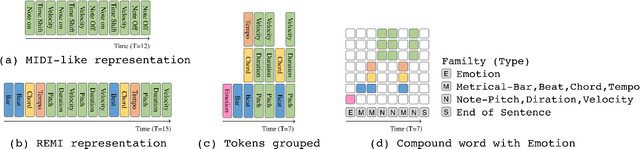
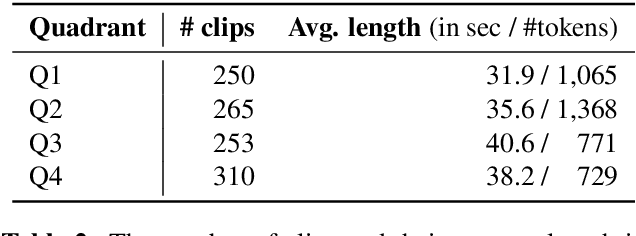
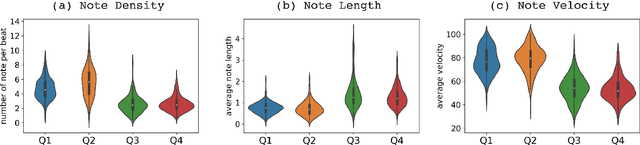
While there are many music datasets with emotion labels in the literature, they cannot be used for research on symbolic-domain music analysis or generation, as there are usually audio files only. In this paper, we present the EMOPIA (pronounced `yee-m\`{o}-pi-uh') dataset, a shared multi-modal (audio and MIDI) database focusing on perceived emotion in pop piano music, to facilitate research on various tasks related to music emotion. The dataset contains 1,087 music clips from 387 songs and clip-level emotion labels annotated by four dedicated annotators. Since the clips are not restricted to one clip per song, they can also be used for song-level analysis. We present the methodology for building the dataset, covering the song list curation, clip selection, and emotion annotation processes. Moreover, we prototype use cases on clip-level music emotion classification and emotion-based symbolic music generation by training and evaluating corresponding models using the dataset. The result demonstrates the potential of EMOPIA for being used in future exploration on piano emotion-related MIR tasks.
DadaGP: A Dataset of Tokenized GuitarPro Songs for Sequence Models
Jul 30, 2021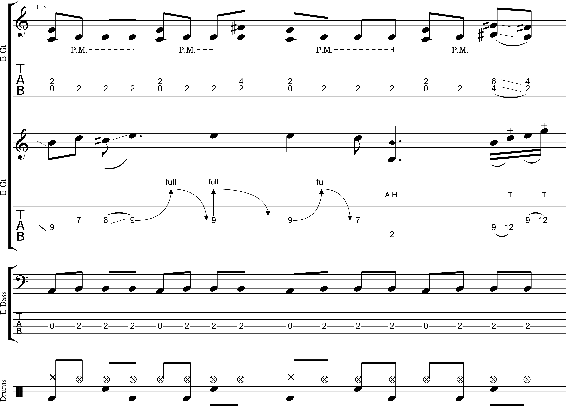

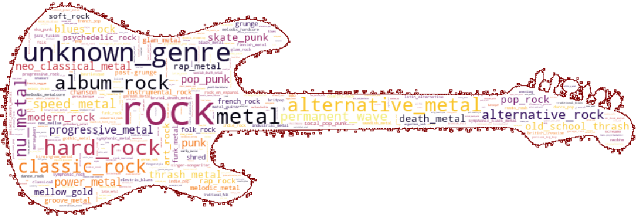
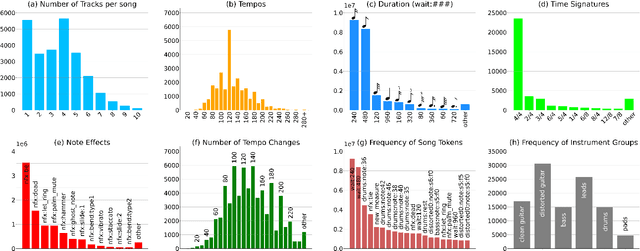
Originating in the Renaissance and burgeoning in the digital era, tablatures are a commonly used music notation system which provides explicit representations of instrument fingerings rather than pitches. GuitarPro has established itself as a widely used tablature format and software enabling musicians to edit and share songs for musical practice, learning, and composition. In this work, we present DadaGP, a new symbolic music dataset comprising 26,181 song scores in the GuitarPro format covering 739 musical genres, along with an accompanying tokenized format well-suited for generative sequence models such as the Transformer. The tokenized format is inspired by event-based MIDI encodings, often used in symbolic music generation models. The dataset is released with an encoder/decoder which converts GuitarPro files to tokens and back. We present results of a use case in which DadaGP is used to train a Transformer-based model to generate new songs in GuitarPro format. We discuss other relevant use cases for the dataset (guitar-bass transcription, music style transfer and artist/genre classification) as well as ethical implications. DadaGP opens up the possibility to train GuitarPro score generators, fine-tune models on custom data, create new styles of music, AI-powered songwriting apps, and human-AI improvisation.