 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Sensor Fusion in Visual Perception
Jun 23, 2020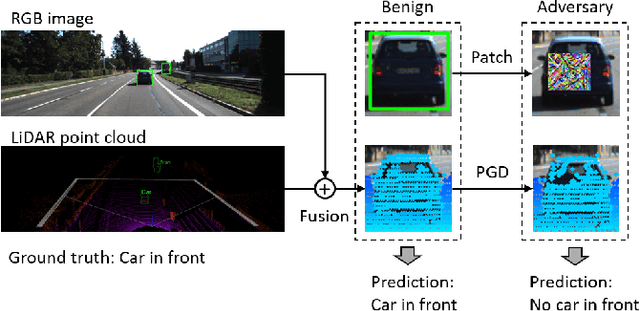
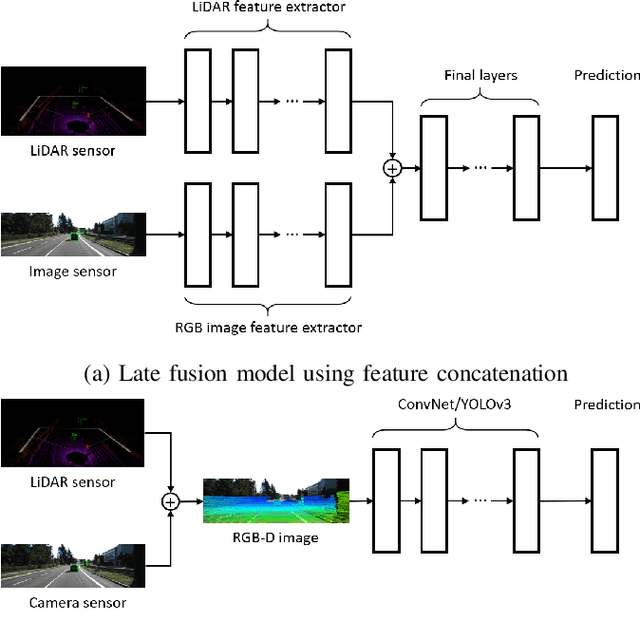
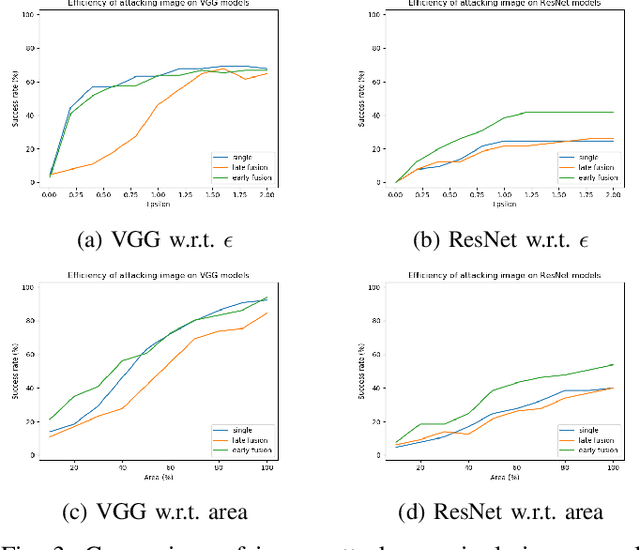
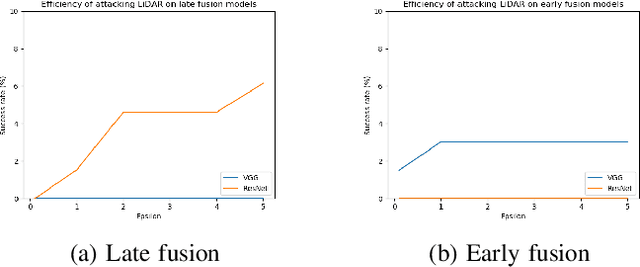
We study the problem of robust sensor fusion in visual perception, especially under the autonomous driving settings. We evaluate the robustness of RGB camera and LiDAR sensor fusion for binary classification and object detection. In this work, we are interested in the behavior of different fusion methods under adversarial attacks on different sensors. We first train both classification and detection models with early fusion and late fusion, then apply different combinations of adversarial attacks on both sensor inputs for evaluation. We also study the effectiveness of adversarial attacks with varying budgets. Experiment results show that while sensor fusion models are generally vulnerable to adversarial attacks, late fusion method is more robust than early fusion. The results also provide insights on further obtaining robust sensor fusion models.
Towards Robustness against Unsuspicious Adversarial Examples
May 08, 2020

Despite the remarkable success of deep neural networks, significant concerns have emerged about their robustness to adversarial perturbations to inputs. While most attacks aim to ensure that these are imperceptible, physical perturbation attacks typically aim for being unsuspicious, even if perceptible. However, there is no universal notion of what it means for adversarial examples to be unsuspicious. We propose an approach for modeling suspiciousness by leveraging cognitive salience. Specifically, we split an image into foreground (salient region) and background (the rest), and allow significantly larger adversarial perturbations in the background. We describe how to compute the resulting dual-perturbation attacks on both deterministic and stochastic classifiers. We then experimentally demonstrate that our attacks do not significantly change perceptual salience of the background, but are highly effective against classifiers robust to conventional attacks. Furthermore, we show that adversarial training with dual-perturbation attacks yields classifiers that are more robust to these than state-of-the-art robust learning approaches, and comparable in terms of robustness to conventional attacks.
On Algorithmic Decision Procedures in Emergency Response Systems in Smart and Connected Communities
Feb 27, 2020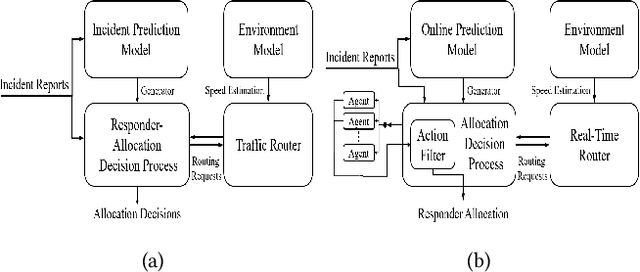
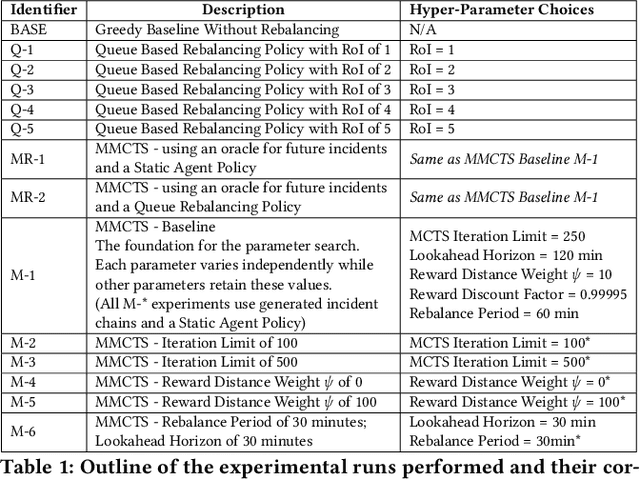
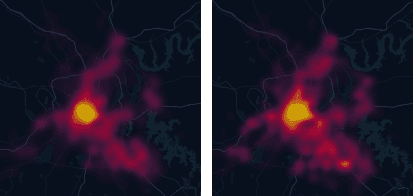
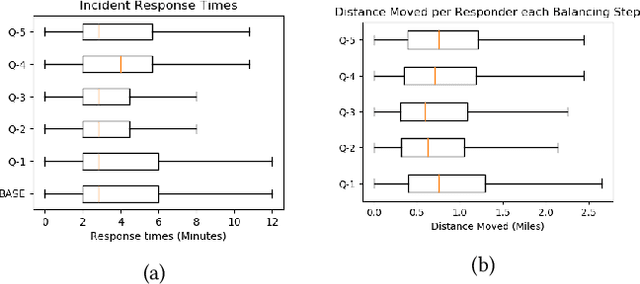
Emergency Response Management (ERM) is a critical problem faced by communities across the globe. Despite its importance, it is common for ERM systems to follow myopic and straight-forward decision policies in the real world. Principled approaches to aid decision-making under uncertainty have been explored in this context but have failed to be accepted into real systems. We identify a key issue impeding their adoption - algorithmic approaches to emergency response focus on reactive, post-incident dispatching actions, i.e. optimally dispatching a responder after incidents occur. However, the critical nature of emergency response dictates that when an incident occurs, first responders always dispatch the closest available responder to the incident. We argue that the crucial period of planning for ERM systems is not post-incident, but between incidents. However, this is not a trivial planning problem - a major challenge with dynamically balancing the spatial distribution of responders is the complexity of the problem. An orthogonal problem in ERM systems is to plan under limited communication, which is particularly important in disaster scenarios that affect communication networks. We address both the problems by proposing two partially decentralized multi-agent planning algorithms that utilize heuristics and the structure of the dispatch problem. We evaluate our proposed approach using real-world data, and find that in several contexts, dynamic re-balancing the spatial distribution of emergency responders reduces both the average response time as well as its variance.
Inducing Equilibria in Networked Public Goods Games through Network Structure Modification
Feb 25, 2020
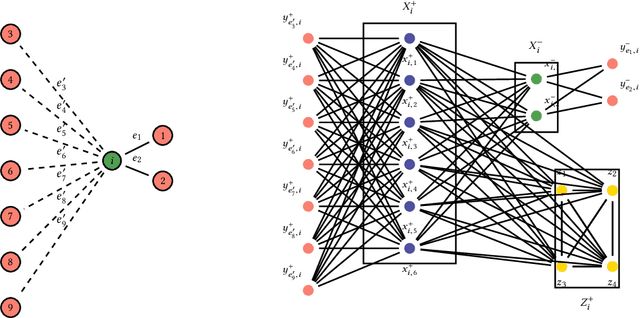
Networked public goods games model scenarios in which self-interested agents decide whether or how much to invest in an action that benefits not only themselves, but also their network neighbors. Examples include vaccination, security investment, and crime reporting. While every agent's utility is increasing in their neighbors' joint investment, the specific form can vary widely depending on the scenario. A principal, such as a policymaker, may wish to induce large investment from the agents. Besides direct incentives, an important lever here is the network structure itself: by adding and removing edges, for example, through community meetings, the principal can change the nature of the utility functions, resulting in different, and perhaps socially preferable, equilibrium outcomes. We initiate an algorithmic study of targeted network modifications with the goal of inducing equilibria of a particular form. We study this question for a variety of equilibrium forms (induce all agents to invest, at least a given set $S$, exactly a given set $S$, at least $k$ agents), and for a variety of utility functions. While we show that the problem is NP-complete for a number of these scenarios, we exhibit a broad array of scenarios in which the problem can be solved in polynomial time by non-trivial reductions to (minimum-cost) matching problems.
Protecting Geolocation Privacy of Photo Collections
Dec 04, 2019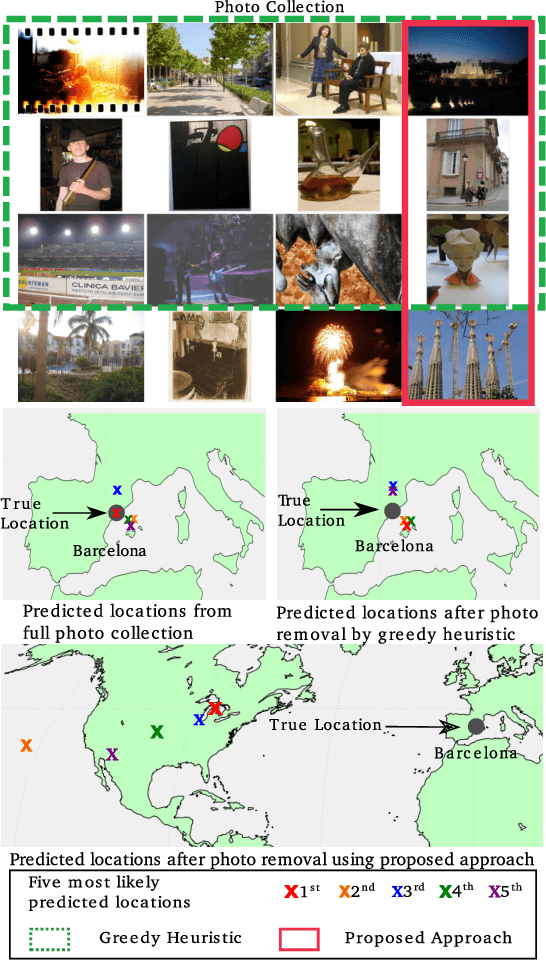
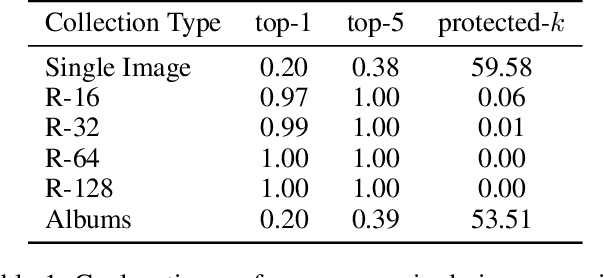
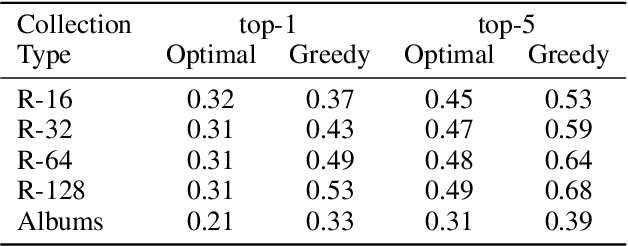
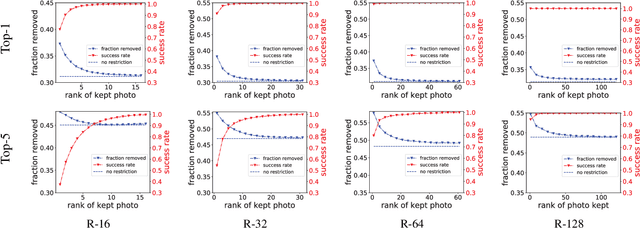
People increasingly share personal information, including their photos and photo collections, on social media. This information, however, can compromise individual privacy, particularly as social media platforms use it to infer detailed models of user behavior, including tracking their location. We consider the specific issue of location privacy as potentially revealed by posting photo collections, which facilitate accurate geolocation with the help of deep learning methods even in the absence of geotags. One means to limit associated inadvertent geolocation privacy disclosure is by carefully pruning select photos from photo collections before these are posted publicly. We study this problem formally as a combinatorial optimization problem in the context of geolocation prediction facilitated by deep learning. We first demonstrate the complexity both by showing that a natural greedy algorithm can be arbitrarily bad and by proving that the problem is NP-Hard. We then exhibit an important tractable special case, as well as a more general approach based on mixed-integer linear programming. Through extensive experiments on real photo collections, we demonstrate that our approaches are indeed highly effective at preserving geolocation privacy.
Deep Reinforcement Learning based Adaptive Moving Target Defense
Nov 27, 2019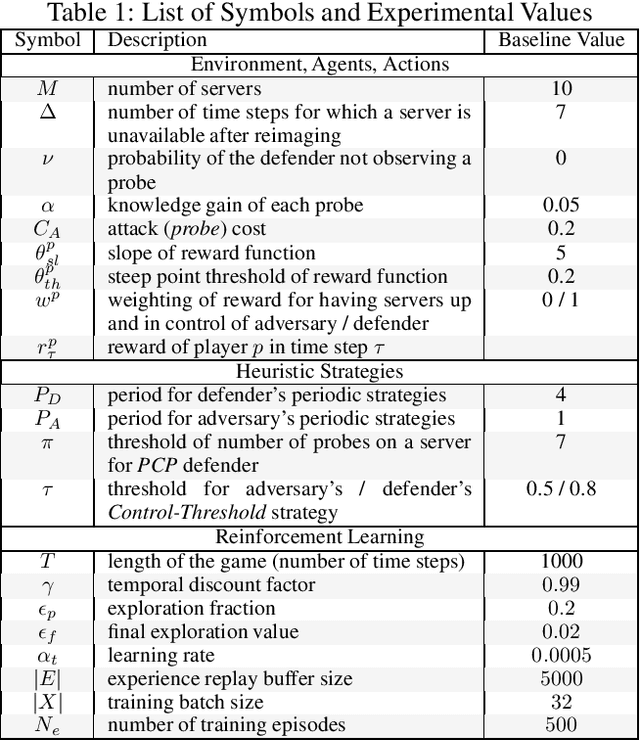
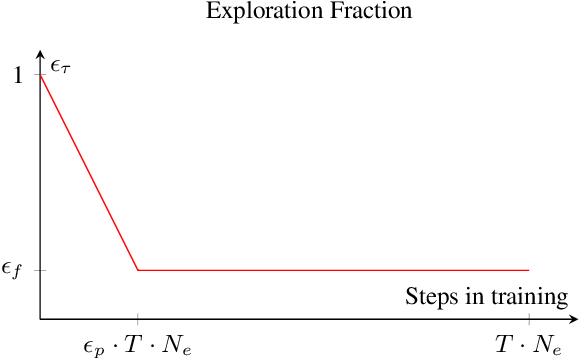
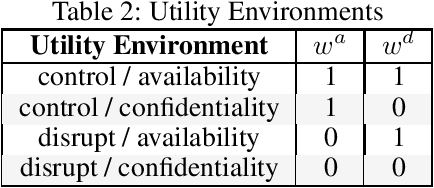
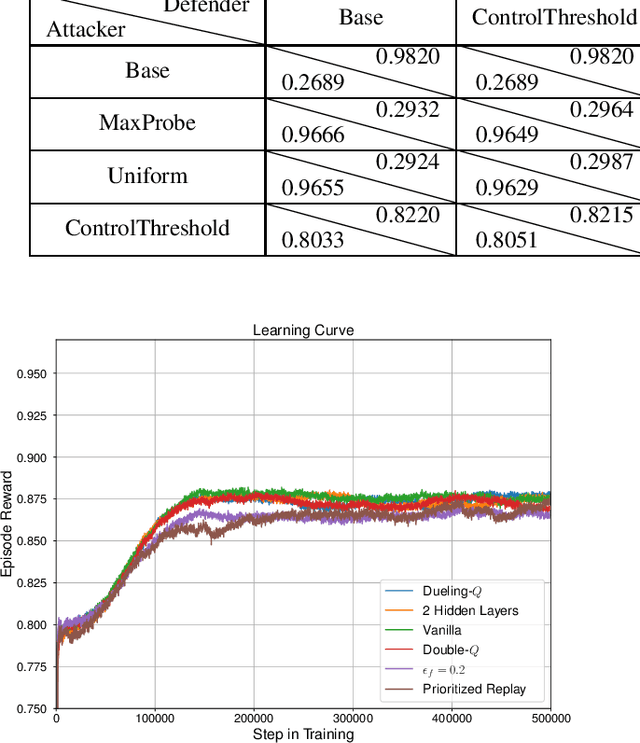
Moving target defense (MTD) is a proactive defense approach that aims to thwart attacks by continuously changing the attack surface of a system (e.g., changing host or network configurations), thereby increasing the adversary's uncertainty and attack cost. To maximize the impact of MTD, a defender must strategically choose when and what changes to make, taking into account both the characteristics of its system as well as the adversary's observed activities. Finding an optimal strategy for MTD presents a significant challenge, especially when facing a resourceful and determined adversary who may respond to the defender's actions. In this paper, we propose finding optimal MTD strategies using deep reinforcement learning. Based on an established model of adaptive MTD, we formulate finding an MTD strategy as finding a policy for a partially-observable Markov decision process. To significantly improve training performance, we introduce compact memory representations. To demonstrate our approach, we provide thorough numerical results, showing significant improvement over existing strategies.
Deception through Half-Truths
Nov 14, 2019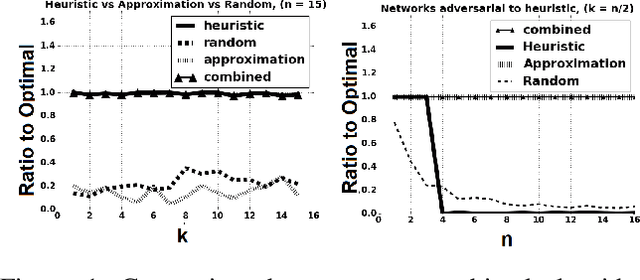
Deception is a fundamental issue across a diverse array of settings, from cybersecurity, where decoys (e.g., honeypots) are an important tool, to politics that can feature politically motivated "leaks" and fake news about candidates.Typical considerations of deception view it as providing false information.However, just as important but less frequently studied is a more tacit form where information is strategically hidden or leaked.We consider the problem of how much an adversary can affect a principal's decision by "half-truths", that is, by masking or hiding bits of information, when the principal is oblivious to the presence of the adversary. The principal's problem can be modeled as one of predicting future states of variables in a dynamic Bayes network, and we show that, while theoretically the principal's decisions can be made arbitrarily bad, the optimal attack is NP-hard to approximate, even under strong assumptions favoring the attacker. However, we also describe an important special case where the dependency of future states on past states is additive, in which we can efficiently compute an approximately optimal attack. Moreover, in networks with a linear transition function we can solve the problem optimally in polynomial time.
Computing Equilibria in Binary Networked Public Goods Games
Nov 13, 2019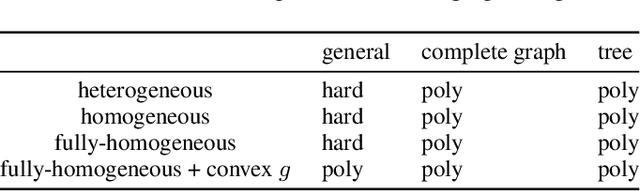
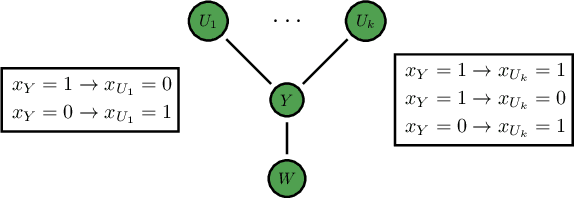
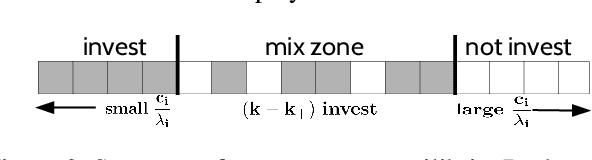
Public goods games study the incentives of individuals to contribute to a public good and their behaviors in equilibria. In this paper, we examine a specific type of public goods game where players are networked and each has binary actions, and focus on the algorithmic aspects of such games. First, we show that checking the existence of a pure-strategy Nash equilibrium is NP-Complete. We then identify tractable instances based on restrictions of either utility functions or of the underlying graphical structure. In certain cases, we also show that we can efficiently compute a socially optimal Nash equilibrium. Finally, we propose a heuristic approach for computing approximate equilibria in general binary networked public goods games, and experimentally demonstrate its effectiveness.
The Tale of Evil Twins: Adversarial Inputs versus Backdoored Models
Nov 05, 2019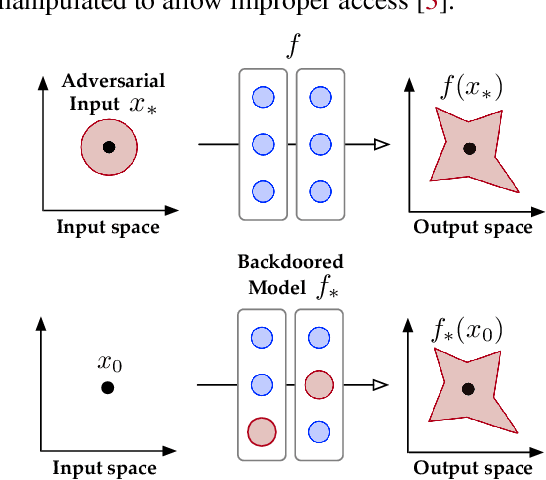
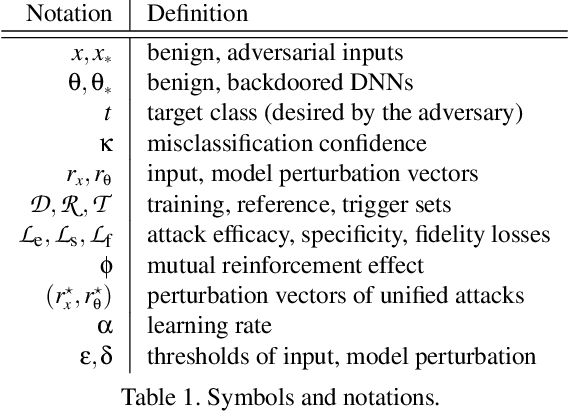
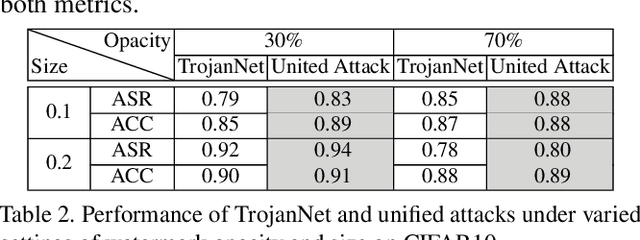
Despite their tremendous success in a wide range of applications, deep neural network (DNN) models are inherently vulnerable to two types of malicious manipulations: adversarial inputs, which are crafted samples that deceive target DNNs, and backdoored models, which are forged DNNs that misbehave on trigger-embedded inputs. While prior work has intensively studied the two attack vectors in parallel, there is still a lack of understanding about their fundamental connection, which is critical for assessing the holistic vulnerability of DNNs deployed in realistic settings. In this paper, we bridge this gap by conducting the first systematic study of the two attack vectors within a unified framework. More specifically, (i) we develop a new attack model that integrates both adversarial inputs and backdoored models; (ii) with both analytical and empirical evidence, we reveal that there exists an intricate "mutual reinforcement" effect between the two attack vectors; (iii) we demonstrate that this effect enables a large spectrum for the adversary to optimize the attack strategies, such as maximizing attack evasiveness with respect to various defenses and designing trigger patterns satisfying multiple desiderata; (v) finally, we discuss potential countermeasures against this unified attack and their technical challenges, which lead to several promising research directions.
Path Planning Games
Oct 30, 2019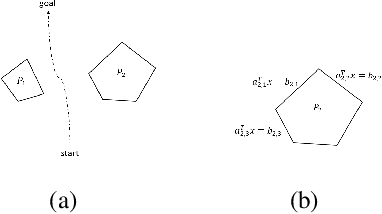
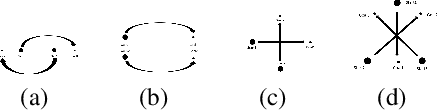
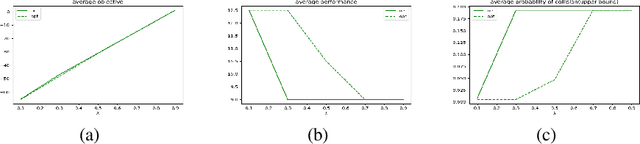
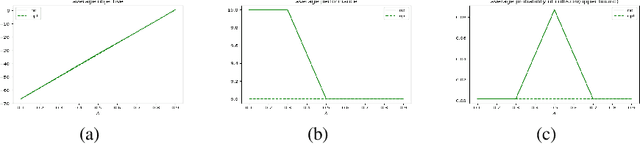
Path planning is a fundamental and extensively explored problem in robotic control. We present a novel economic perspective on path planning. Specifically, we investigate strategic interactions among path planning agents using a game theoretic path planning framework. Our focus is on economic tension between two important objectives: efficiency in the agents' achieving their goals, and safety in navigating towards these. We begin by developing a novel mathematical formulation for path planning that trades off these objectives, when behavior of other agents is fixed. We then use this formulation for approximating Nash equilibria in path planning games, as well as to develop a multi-agent cooperative path planning formulation. Through several case studies, we show that in a path planning game, safety is often significantly compromised compared to a cooperative solution.