 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate GPU Memory Prediction for Deep Learning Jobs through Dynamic Analysis
Apr 04, 2025



The benefits of Deep Learning (DL) impose significant pressure on GPU resources, particularly within GPU cluster, where Out-Of-Memory (OOM) errors present a primary impediment to model training and efficient resource utilization. Conventional OOM estimation techniques, relying either on static graph analysis or direct GPU memory profiling, suffer from inherent limitations: static analysis often fails to capture model dynamics, whereas GPU-based profiling intensifies contention for scarce GPU resources. To overcome these constraints, VeritasEst emerges. It is an innovative, entirely CPU-based analysis tool capable of accurately predicting the peak GPU memory required for DL training tasks without accessing the target GPU. This "offline" prediction capability is core advantage of VeritasEst, allowing accurate memory footprint information to be obtained before task scheduling, thereby effectively preventing OOM and optimizing GPU allocation. Its performance was validated through thousands of experimental runs across convolutional neural network (CNN) models: Compared to baseline GPU memory estimators, VeritasEst significantly reduces the relative error by 84% and lowers the estimation failure probability by 73%. VeritasEst represents a key step towards efficient and predictable DL training in resource-constrained environments.
Optimizing Deep Learning Inference on Embedded Systems Through Adaptive Model Selection
Nov 09, 2019

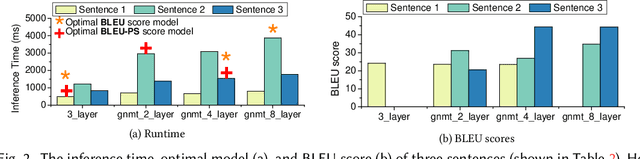

Deep neural networks ( DNNs ) are becoming a key enabling technology for many application domains. However, on-device inference on battery-powered, resource-constrained embedding systems is often infeasible due to prohibitively long inferencing time and resource requirements of many DNNs. Offloading computation into the cloud is often unacceptable due to privacy concerns, high latency, or the lack of connectivity. While compression algorithms often succeed in reducing inferencing times, they come at the cost of reduced accuracy. This paper presents a new, alternative approach to enable efficient execution of DNNs on embedded devices. Our approach dynamically determines which DNN to use for a given input, by considering the desired accuracy and inference time. It employs machine learning to develop a low-cost predictive model to quickly select a pre-trained DNN to use for a given input and the optimization constraint. We achieve this by first off-line training a predictive model, and then using the learned model to select a DNN model to use for new, unseen inputs. We apply our approach to two representative DNN domains: image classification and machine translation. We evaluate our approach on a Jetson TX2 embedded deep learning platform and consider a range of influential DNN models including convolutional and recurrent neural networks. For image classification, we achieve a 1.8x reduction in inference time with a 7.52% improvement in accuracy, over the most-capable single DNN model. For machine translation, we achieve a 1.34x reduction in inference time over the most-capable single model, with little impact on the quality of translation.
Transferable Knowledge for Low-cost Decision Making in Cloud Environments
May 07, 2019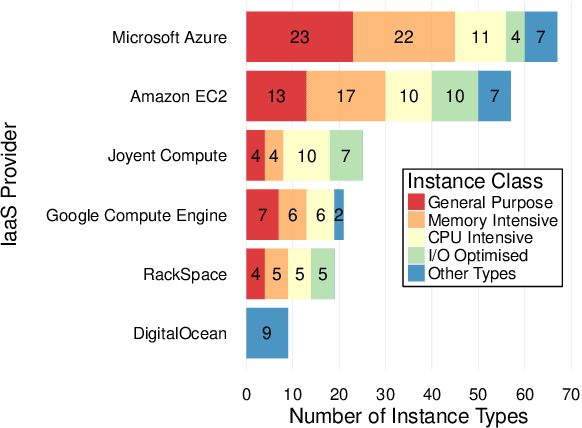
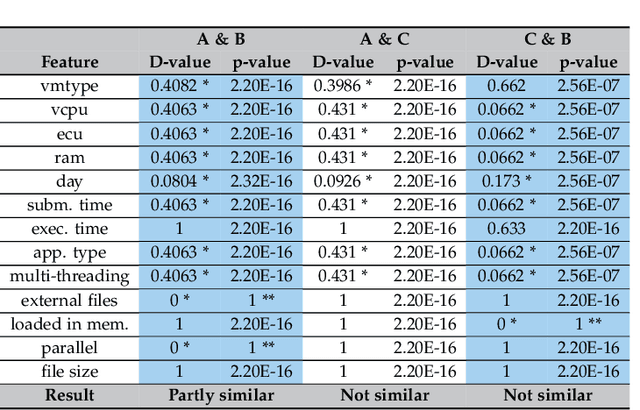
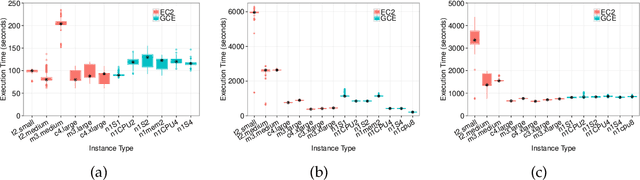
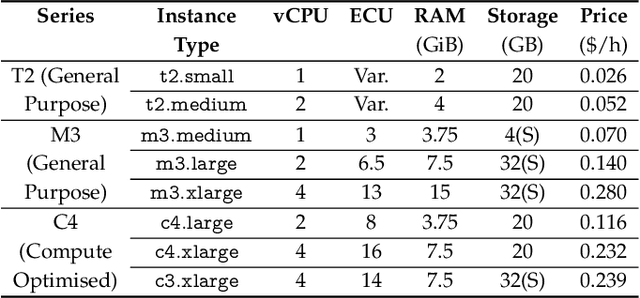
Users of cloud computing are increasingly overwhelmed with the wide range of providers and services offered by each provider. As such, many users select cloud services based on description alone. An emerging alternative is to use a decision support system (DSS), which typically relies on gaining insights from observational data in order to assist a customer in making decisions regarding optimal deployment or redeployment of cloud applications. The primary activity of such systems is the generation of a prediction model (e.g. using machine learning), which requires a significantly large amount of training data. However, considering the varying architectures of applications, cloud providers, and cloud offerings, this activity is not sustainable as it incurs additional time and cost to collect training data and subsequently train the models. We overcome this through developing a Transfer Learning (TL) approach where the knowledge (in the form of the prediction model and associated data set) gained from running an application on a particular cloud infrastructure is transferred in order to substantially reduce the overhead of building new models for the performance of new applications and/or cloud infrastructures. In this paper, we present our approach and evaluate it through extensive experimentation involving three real world applications over two major public cloud providers, namely Amazon and Google. Our evaluation shows that our novel two-mode TL scheme increases overall efficiency with a factor of 60\% reduction in the time and cost of generating a new prediction model. We test this under a number of cross-application and cross-cloud scenarios.
Navigating Diverse Data Science Learning: Critical Reflections Towards Future Practice
Jul 05, 2018
Data Science is currently a popular field of science attracting expertise from very diverse backgrounds. Current learning practices need to acknowledge this and adapt to it. This paper summarises some experiences relating to such learning approaches from teaching a postgraduate Data Science module, and draws some learned lessons that are of relevance to others teaching Data Science.
Adaptive Selection of Deep Learning Models on Embedded Systems
May 11, 2018
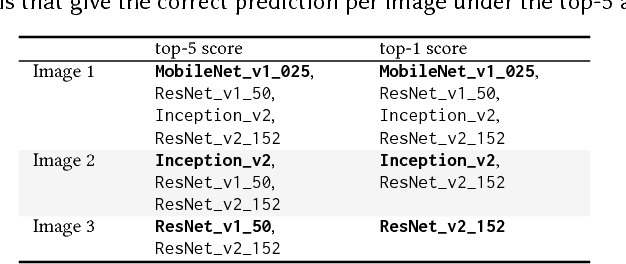


The recent ground-breaking advances in deep learning networks ( DNNs ) make them attractive for embedded systems. However, it can take a long time for DNNs to make an inference on resource-limited embedded devices. Offloading the computation into the cloud is often infeasible due to privacy concerns, high latency, or the lack of connectivity. As such, there is a critical need to find a way to effectively execute the DNN models locally on the devices. This paper presents an adaptive scheme to determine which DNN model to use for a given input, by considering the desired accuracy and inference time. Our approach employs machine learning to develop a predictive model to quickly select a pre-trained DNN to use for a given input and the optimization constraint. We achieve this by first training off-line a predictive model, and then use the learnt model to select a DNN model to use for new, unseen inputs. We apply our approach to the image classification task and evaluate it on a Jetson TX2 embedded deep learning platform using the ImageNet ILSVRC 2012 validation dataset. We consider a range of influential DNN models. Experimental results show that our approach achieves a 7.52% improvement in inference accuracy, and a 1.8x reduction in inference time over the most-capable single DNN model.
Unsupervised Machine Learning for Networking: Techniques, Applications and Research Challenges
Sep 19, 2017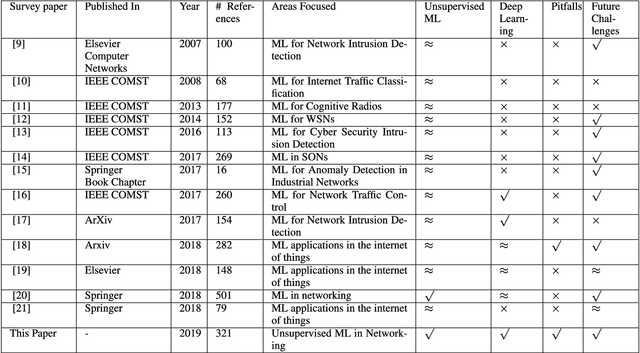
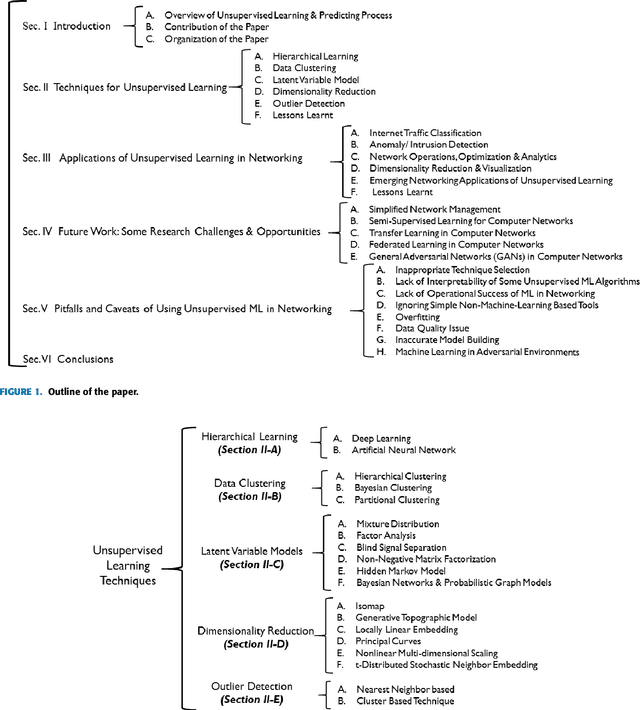
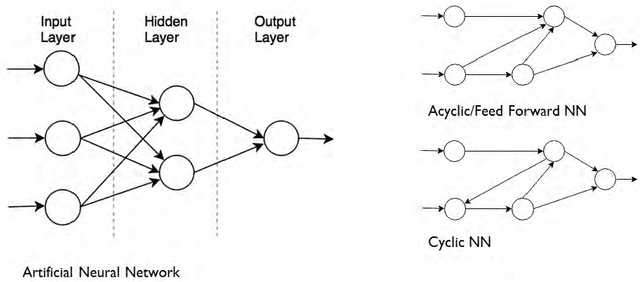
While machine learning and artificial intelligence have long been applied in networking research, the bulk of such works has focused on supervised learning. Recently there has been a rising trend of employing unsupervised machine learning using unstructured raw network data to improve network performance and provide services such as traffic engineering, anomaly detection, Internet traffic classification, and quality of service optimization. The interest in applying unsupervised learning techniques in networking emerges from their great success in other fields such as computer vision, natural language processing, speech recognition, and optimal control (e.g., for developing autonomous self-driving cars). Unsupervised learning is interesting since it can unconstrain us from the need of labeled data and manual handcrafted feature engineering thereby facilitating flexible, general, and automated methods of machine learning. The focus of this survey paper is to provide an overview of the applications of unsupervised learning in the domain of networking. We provide a comprehensive survey highlighting the recent advancements in unsupervised learning techniques and describe their applications for various learning tasks in the context of networking. We also provide a discussion on future directions and open research issues, while also identifying potential pitfalls. While a few survey papers focusing on the applications of machine learning in networking have previously been published, a survey of similar scope and breadth is missing in literature. Through this paper, we advance the state of knowledge by carefully synthesizing the insights from these survey papers while also providing contemporary coverage of recent advances.
Daleel: Simplifying Cloud Instance Selection Using Machine Learning
Feb 05, 2016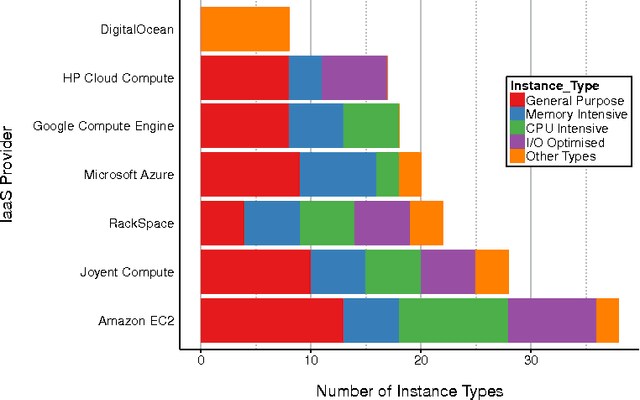
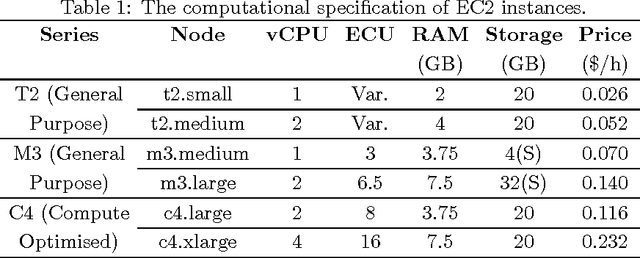
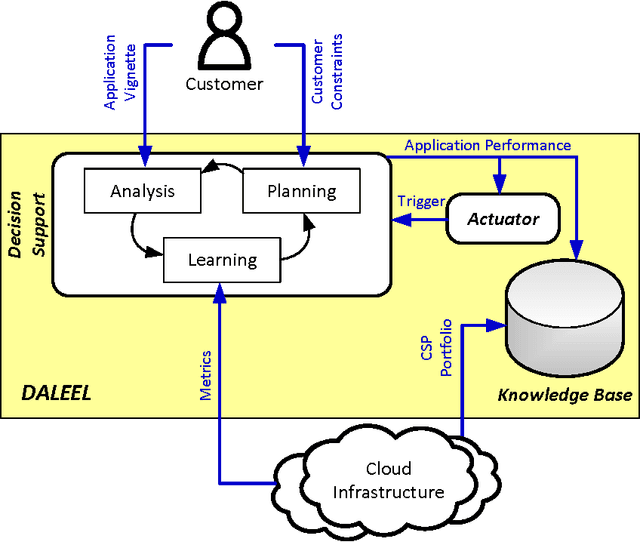
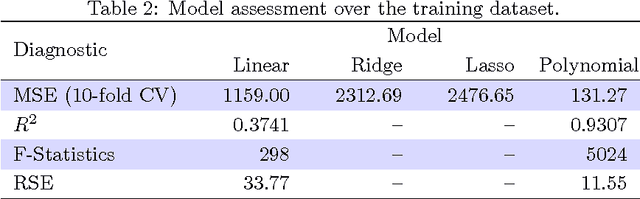
Decision making in cloud environments is quite challenging due to the diversity in service offerings and pricing models, especially considering that the cloud market is an incredibly fast moving one. In addition, there are no hard and fast rules, each customer has a specific set of constraints (e.g. budget) and application requirements (e.g. minimum computational resources). Machine learning can help address some of the complicated decisions by carrying out customer-specific analytics to determine the most suitable instance type(s) and the most opportune time for starting or migrating instances. We employ machine learning techniques to develop an adaptive deployment policy, providing an optimal match between the customer demands and the available cloud service offerings. We provide an experimental study based on extensive set of job executions over a major public cloud infrastructure.