 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRM-Text: Efficient Pretraining Beyond Scaling
May 20, 2026The current pretraining paradigm for large language models relies on massive compute and internet-scale raw text, creating a significant barrier to foundational research. In contrast, biological systems demonstrate highly sample-efficient learning through multi-timescale processing, such as the functional organization of the frontoparietal loop. Taking this as inspiration, we introduce HRM-Text, which replaces standard Transformers with a Hierarchical Recurrent Model (HRM) that decouples computation into slow-evolving strategic and fast-evolving execution layers. To stabilize this deep recurrence for language modeling, we introduce MagicNorm and warmup deep credit assignment. Furthermore, instead of standard raw-text pretraining, we train exclusively on instruction-response pairs using a task-completion objective and PrefixLM masking. Serving as an empirical existence proof of efficient pretraining, a 1B-parameter HRM-Text model trained from scratch on only 40 billion unique tokens and $1,500 budget achieves 60.7% on MMLU, 81.9% on ARC-C, 82.2% on DROP, 84.5% on GSM8K, and 56.2% on MATH. Despite utilizing roughly 100-900x fewer training tokens and 96-432x less estimated compute than standard baselines, HRM-Text performs competitively with 2-7B parameter open models. These results demonstrate that co-designing architectures and objectives can radically reduce the compute-to-performance ratio, making pretraining from scratch accessible to the broader research community.
Pointwise confidence estimation in the non-linear $\ell^2$-regularized least squares
Jun 08, 2025We consider a high-probability non-asymptotic confidence estimation in the $\ell^2$-regularized non-linear least-squares setting with fixed design. In particular, we study confidence estimation for local minimizers of the regularized training loss. We show a pointwise confidence bound, meaning that it holds for the prediction on any given fixed test input $x$. Importantly, the proposed confidence bound scales with similarity of the test input to the training data in the implicit feature space of the predictor (for instance, becoming very large when the test input lies far outside of the training data). This desirable last feature is captured by the weighted norm involving the inverse-Hessian matrix of the objective function, which is a generalized version of its counterpart in the linear setting, $x^{\top} \text{Cov}^{-1} x$. Our generalized result can be regarded as a non-asymptotic counterpart of the classical confidence interval based on asymptotic normality of the MLE estimator. We propose an efficient method for computing the weighted norm, which only mildly exceeds the cost of a gradient computation of the loss function. Finally, we complement our analysis with empirical evidence showing that the proposed confidence bound provides better coverage/width trade-off compared to a confidence estimation by bootstrapping, which is a gold-standard method in many applications involving non-linear predictors such as neural networks.
Low-rank bias, weight decay, and model merging in neural networks
Feb 24, 2025



We explore the low-rank structure of the weight matrices in neural networks originating from training with Gradient Descent (GD) and Gradient Flow (GF) with $L2$ regularization (also known as weight decay). We show several properties of GD-trained deep neural networks, induced by $L2$ regularization. In particular, for a stationary point of GD we show alignment of the parameters and the gradient, norm preservation across layers, and low-rank bias: properties previously known in the context of GF solutions. Experiments show that the assumptions made in the analysis only mildly affect the observations. In addition, we investigate a multitask learning phenomenon enabled by $L2$ regularization and low-rank bias. In particular, we show that if two networks are trained, such that the inputs in the training set of one network are approximately orthogonal to the inputs in the training set of the other network, the new network obtained by simply summing the weights of the two networks will perform as well on both training sets as the respective individual networks. We demonstrate this for shallow ReLU neural networks trained by GD, as well as deep linear and deep ReLU networks trained by GF.
HONE: Higher-Order Network Embeddings
May 30, 2018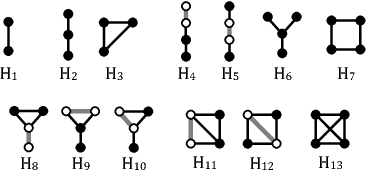
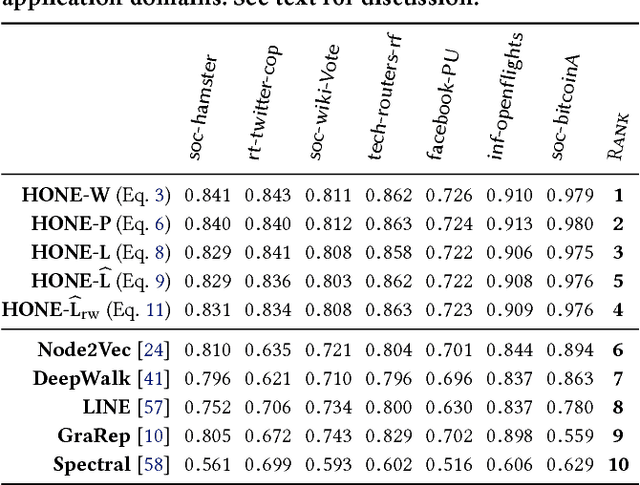
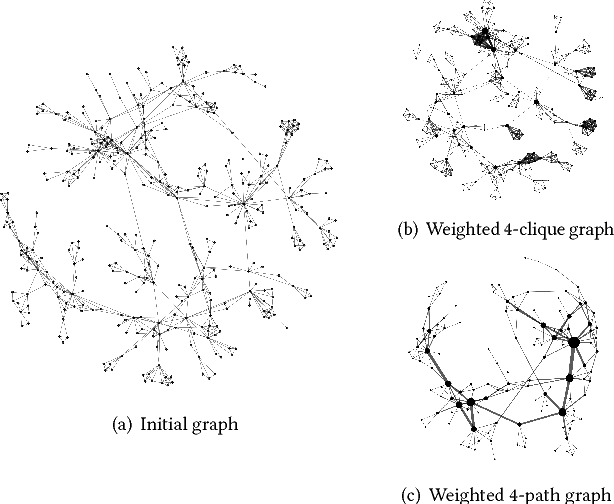
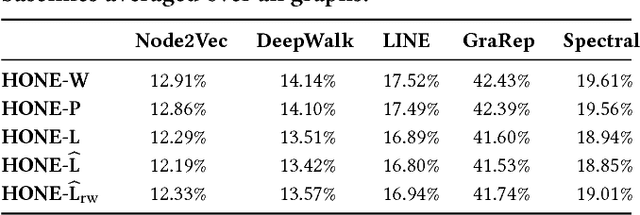
This paper describes a general framework for learning Higher-Order Network Embeddings (HONE) from graph data based on network motifs. The HONE framework is highly expressive and flexible with many interchangeable components. The experimental results demonstrate the effectiveness of learning higher-order network representations. In all cases, HONE outperforms recent embedding methods that are unable to capture higher-order structures with a mean relative gain in AUC of $19\%$ (and up to $75\%$ gain) across a wide variety of networks and embedding methods.