 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Whisper to Grade Them All
Jul 23, 2025We present an efficient end-to-end approach for holistic Automatic Speaking Assessment (ASA) of multi-part second-language tests, developed for the 2025 Speak & Improve Challenge. Our system's main novelty is the ability to process all four spoken responses with a single Whisper-small encoder, combine all information via a lightweight aggregator, and predict the final score. This architecture removes the need for transcription and per-part models, cuts inference time, and makes ASA practical for large-scale Computer-Assisted Language Learning systems. Our system achieved a Root Mean Squared Error (RMSE) of 0.384, outperforming the text-based baseline (0.44) while using at most 168M parameters (about 70% of Whisper-small). Furthermore, we propose a data sampling strategy, allowing the model to train on only 44.8% of the speakers in the corpus and still reach 0.383 RMSE, demonstrating improved performance on imbalanced classes and strong data efficiency.
Non-native Children's Automatic Speech Assessment Challenge (NOCASA)
Apr 29, 2025



This paper presents the "Non-native Children's Automatic Speech Assessment" (NOCASA) - a data competition part of the IEEE MLSP 2025 conference. NOCASA challenges participants to develop new systems that can assess single-word pronunciations of young second language (L2) learners as part of a gamified pronunciation training app. To achieve this, several issues must be addressed, most notably the limited nature of available training data and the highly unbalanced distribution among the pronunciation level categories. To expedite the development, we provide a pseudo-anonymized training data (TeflonNorL2), containing 10,334 recordings from 44 speakers attempting to pronounce 205 distinct Norwegian words, human-rated on a 1 to 5 scale (number of stars that should be given in the game). In addition to the data, two already trained systems are released as official baselines: an SVM classifier trained on the ComParE_16 acoustic feature set and a multi-task wav2vec 2.0 model. The latter achieves the best performance on the challenge test set, with an unweighted average recall (UAR) of 36.37%.
Advancing Audio Emotion and Intent Recognition with Large Pre-Trained Models and Bayesian Inference
Oct 16, 2023


Large pre-trained models are essential in paralinguistic systems, demonstrating effectiveness in tasks like emotion recognition and stuttering detection. In this paper, we employ large pre-trained models for the ACM Multimedia Computational Paralinguistics Challenge, addressing the Requests and Emotion Share tasks. We explore audio-only and hybrid solutions leveraging audio and text modalities. Our empirical results consistently show the superiority of the hybrid approaches over the audio-only models. Moreover, we introduce a Bayesian layer as an alternative to the standard linear output layer. The multimodal fusion approach achieves an 85.4% UAR on HC-Requests and 60.2% on HC-Complaints. The ensemble model for the Emotion Share task yields the best rho value of .614. The Bayesian wav2vec2 approach, explored in this study, allows us to easily build ensembles, at the cost of fine-tuning only one model. Moreover, we can have usable confidence values instead of the usual overconfident posterior probabilities.
Lahjoita puhetta -- a large-scale corpus of spoken Finnish with some benchmarks
Mar 24, 2022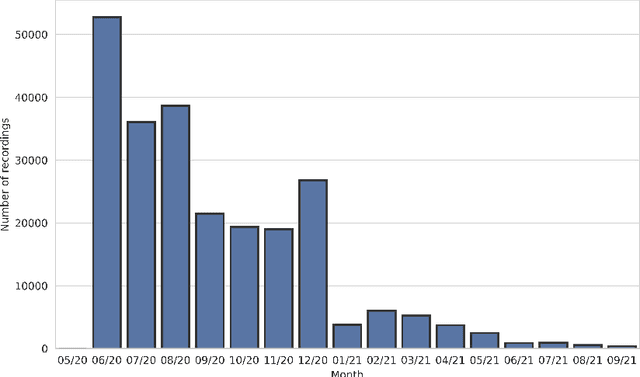
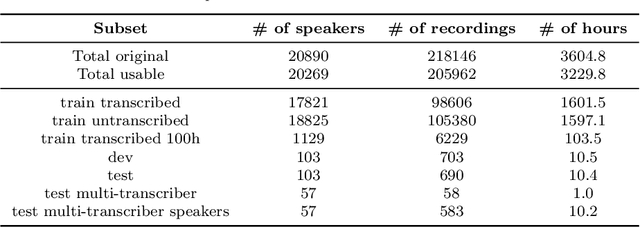
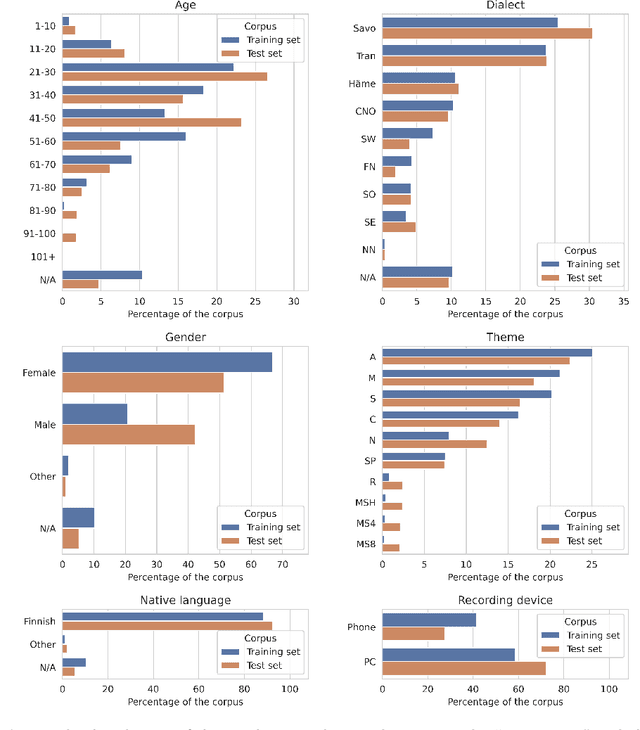
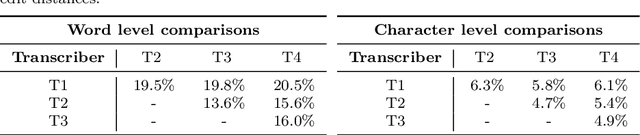
The Donate Speech campaign has so far succeeded in gathering approximately 3600 hours of ordinary, colloquial Finnish speech into the Lahjoita puhetta (Donate Speech) corpus. The corpus includes over twenty thousand speakers from all the regions of Finland and from all age brackets. The primary goals of the collection were to create a representative, large-scale resource to study spontaneous spoken Finnish and to accelerate the development of language technology and speech-based services. In this paper, we present the collection process and the collected corpus, and showcase its versatility through multiple use cases. The evaluated use cases include: automatic speech recognition of spontaneous speech, detection of age, gender, dialect and topic and metadata analysis. We provide benchmarks for the use cases, as well down loadable, trained baseline systems with open-source code for reproducibility. One further use case is to verify the metadata and transcripts given in this corpus itself, and to suggest artificial metadata and transcripts for the part of the corpus where it is missing.