 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLahjoita puhetta -- a large-scale corpus of spoken Finnish with some benchmarks
Mar 24, 2022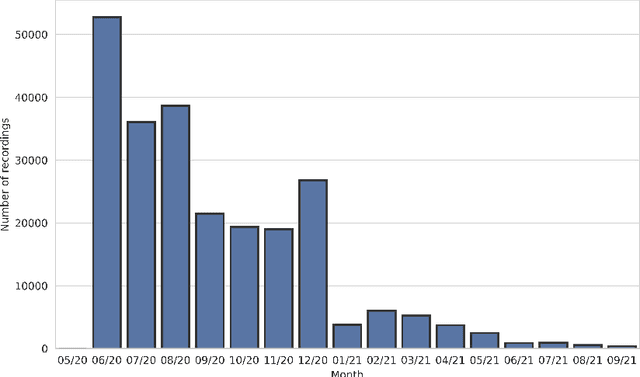
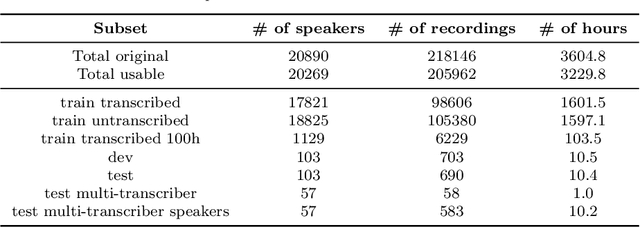
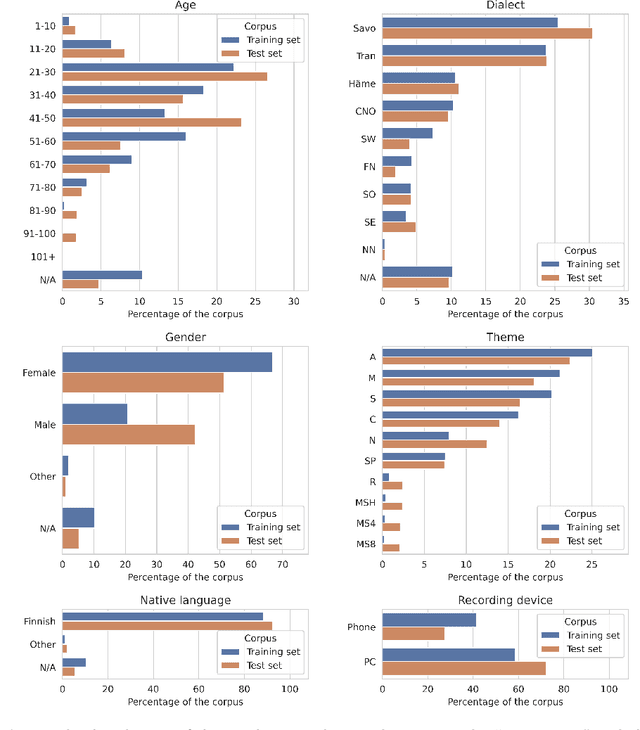
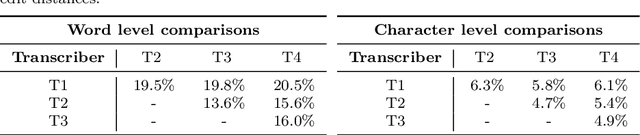
The Donate Speech campaign has so far succeeded in gathering approximately 3600 hours of ordinary, colloquial Finnish speech into the Lahjoita puhetta (Donate Speech) corpus. The corpus includes over twenty thousand speakers from all the regions of Finland and from all age brackets. The primary goals of the collection were to create a representative, large-scale resource to study spontaneous spoken Finnish and to accelerate the development of language technology and speech-based services. In this paper, we present the collection process and the collected corpus, and showcase its versatility through multiple use cases. The evaluated use cases include: automatic speech recognition of spontaneous speech, detection of age, gender, dialect and topic and metadata analysis. We provide benchmarks for the use cases, as well down loadable, trained baseline systems with open-source code for reproducibility. One further use case is to verify the metadata and transcripts given in this corpus itself, and to suggest artificial metadata and transcripts for the part of the corpus where it is missing.
FinnSentiment -- A Finnish Social Media Corpus for Sentiment Polarity Annotation
Dec 04, 2020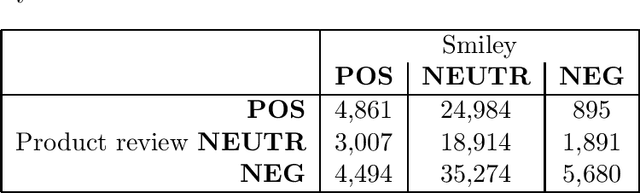
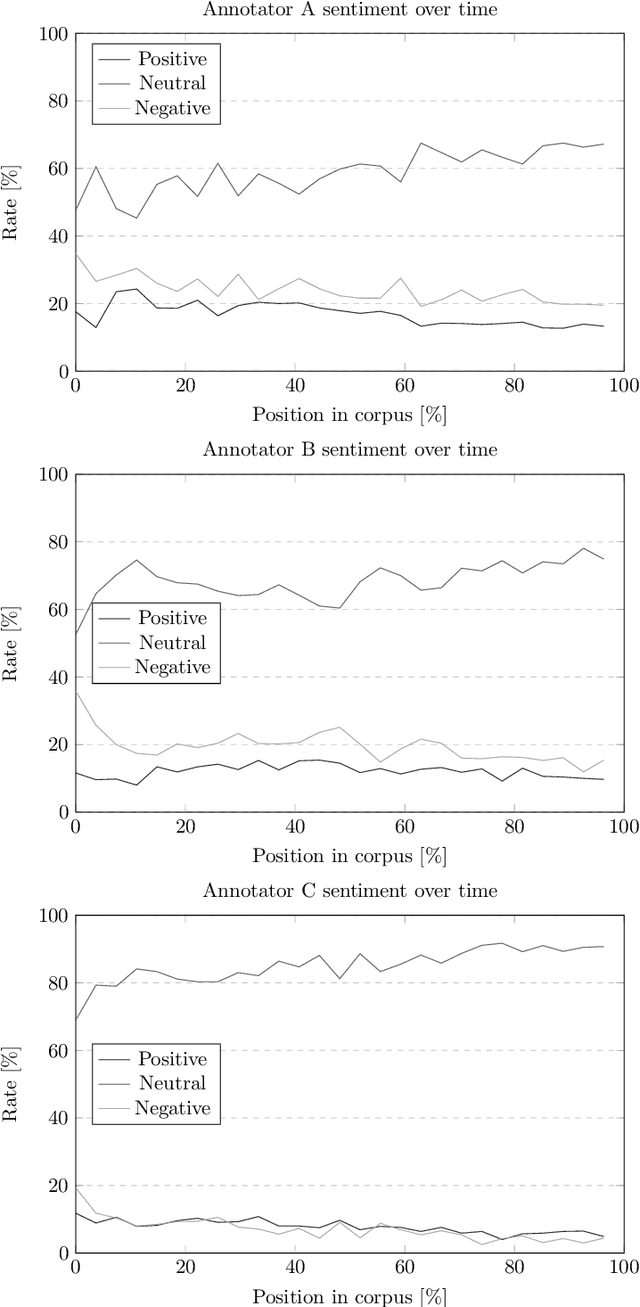
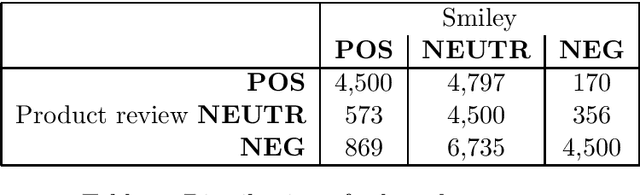
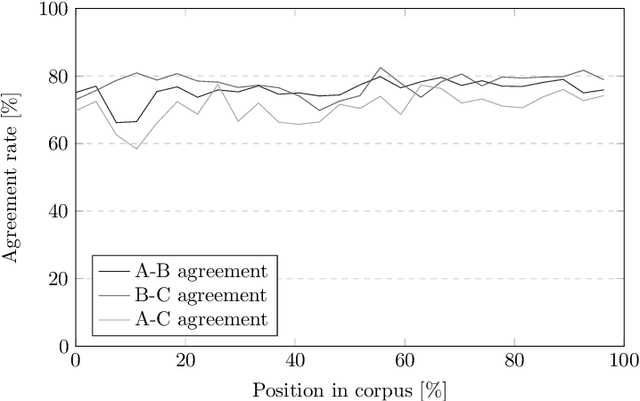
Sentiment analysis and opinion mining is an important task with obvious application areas in social media, e.g. when indicating hate speech and fake news. In our survey of previous work, we note that there is no large-scale social media data set with sentiment polarity annotations for Finnish. This publications aims to remedy this shortcoming by introducing a 27,000 sentence data set annotated independently with sentiment polarity by three native annotators. We had the same three annotators for the whole data set, which provides a unique opportunity for further studies of annotator behaviour over time. We analyse their inter-annotator agreement and provide two baselines to validate the usefulness of the data set.
Uralic Language Identification (ULI) 2020 shared task dataset and the Wanca 2017 corpus
Aug 27, 2020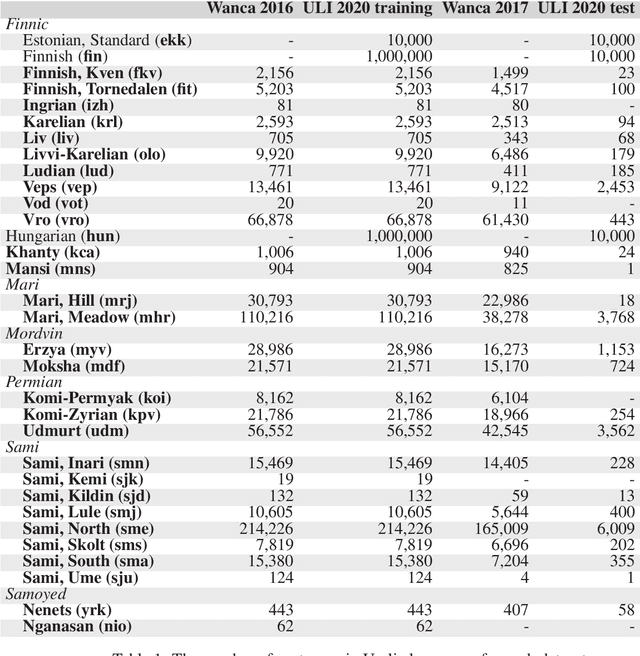

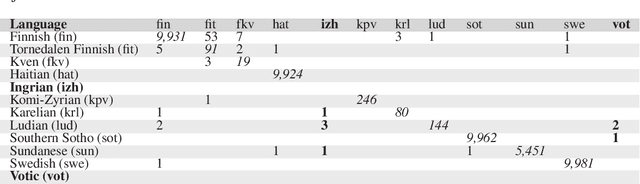
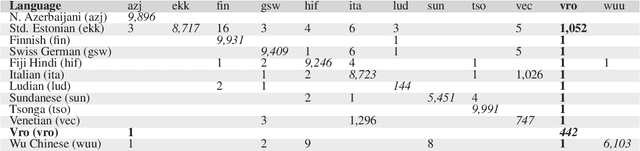
This article introduces the Wanca 2017 corpus of texts crawled from the internet from which the sentences in rare Uralic languages for the use of the Uralic Language Identification (ULI) 2020 shared task were collected. We describe the ULI dataset and how it was constructed using the Wanca 2017 corpus and texts in different languages from the Leipzig corpora collection. We also provide baseline language identification experiments conducted using the ULI 2020 dataset.
The European Language Technology Landscape in 2020: Language-Centric and Human-Centric AI for Cross-Cultural Communication in Multilingual Europe
Mar 30, 2020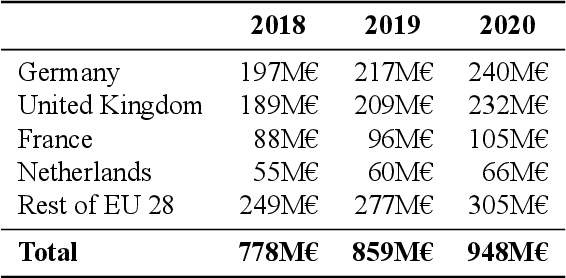
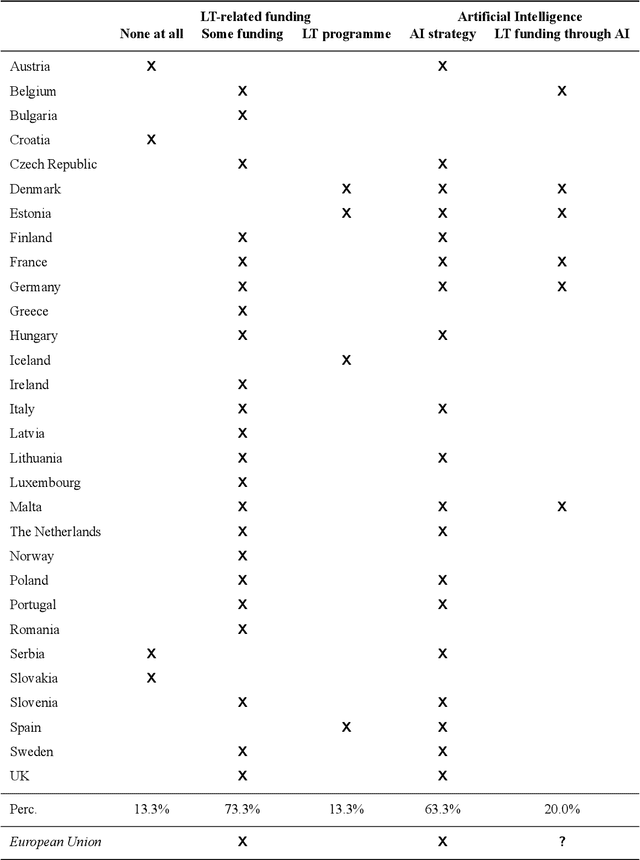
Multilingualism is a cultural cornerstone of Europe and firmly anchored in the European treaties including full language equality. However, language barriers impacting business, cross-lingual and cross-cultural communication are still omnipresent. Language Technologies (LTs) are a powerful means to break down these barriers. While the last decade has seen various initiatives that created a multitude of approaches and technologies tailored to Europe's specific needs, there is still an immense level of fragmentation. At the same time, AI has become an increasingly important concept in the European Information and Communication Technology area. For a few years now, AI, including many opportunities, synergies but also misconceptions, has been overshadowing every other topic. We present an overview of the European LT landscape, describing funding programmes, activities, actions and challenges in the different countries with regard to LT, including the current state of play in industry and the LT market. We present a brief overview of the main LT-related activities on the EU level in the last ten years and develop strategic guidance with regard to four key dimensions.
A Finnish News Corpus for Named Entity Recognition
Aug 12, 2019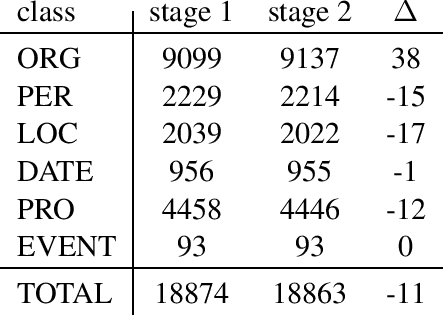
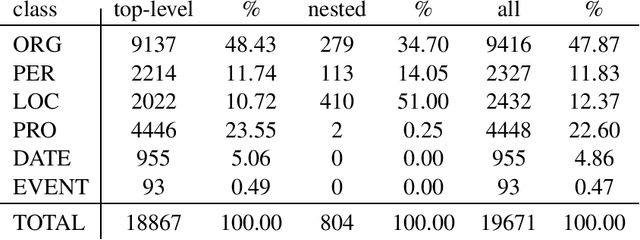
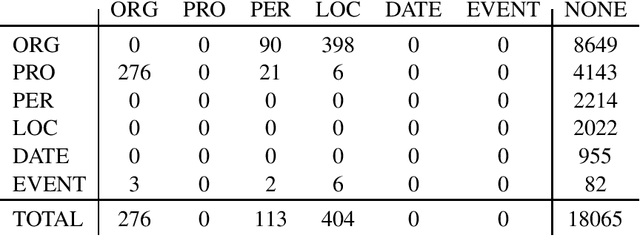
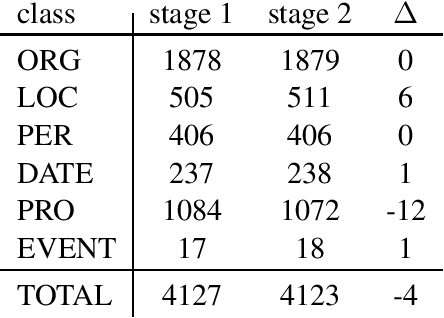
We present a corpus of Finnish news articles with a manually prepared named entity annotation. The corpus consists of 953 articles (193,742 word tokens) with six named entity classes (organization, location, person, product, event, and date). The articles are extracted from the archives of Digitoday, a Finnish online technology news source. The corpus is available for research purposes. We present baseline experiments on the corpus using a rule-based and two deep learning systems on two, in-domain and out-of-domain, test sets.
Language Model Adaptation for Language and Dialect Identification of Text
Mar 26, 2019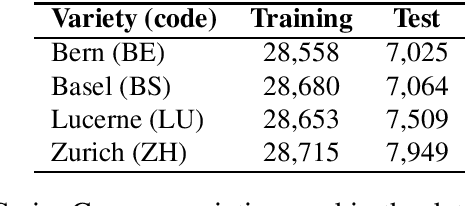
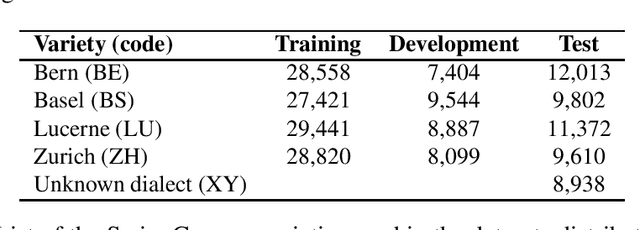
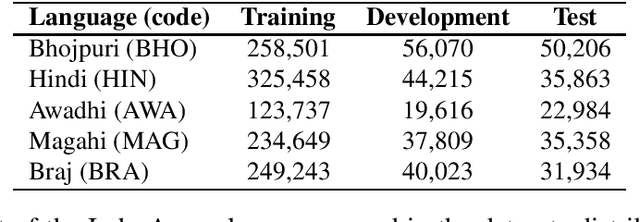
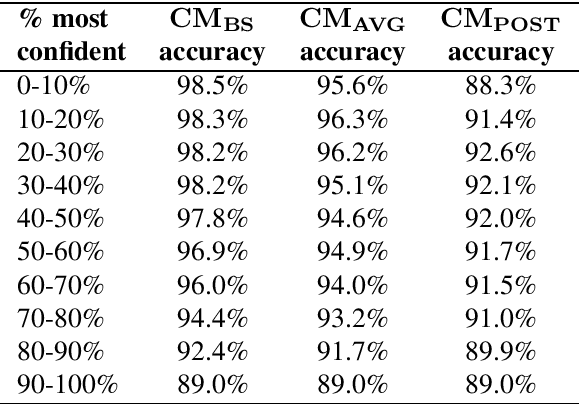
This article describes an unsupervised language model adaptation approach that can be used to enhance the performance of language identification methods. The approach is applied to a current version of the HeLI language identification method, which is now called HeLI 2.0. We describe the HeLI 2.0 method in detail. The resulting system is evaluated using the datasets from the German dialect identification and Indo-Aryan language identification shared tasks of the VarDial workshops 2017 and 2018. The new approach with language identification provides considerably higher F1-scores than the previous HeLI method or the other systems which participated in the shared tasks. The results indicate that unsupervised language model adaptation should be considered as an option in all language identification tasks, especially in those where encountering out-of-domain data is likely.
Language and Dialect Identification of Cuneiform Texts
Mar 13, 2019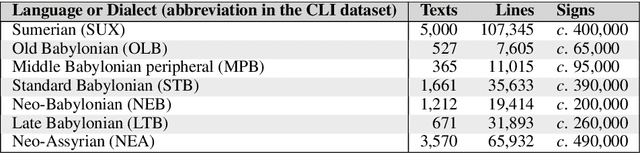
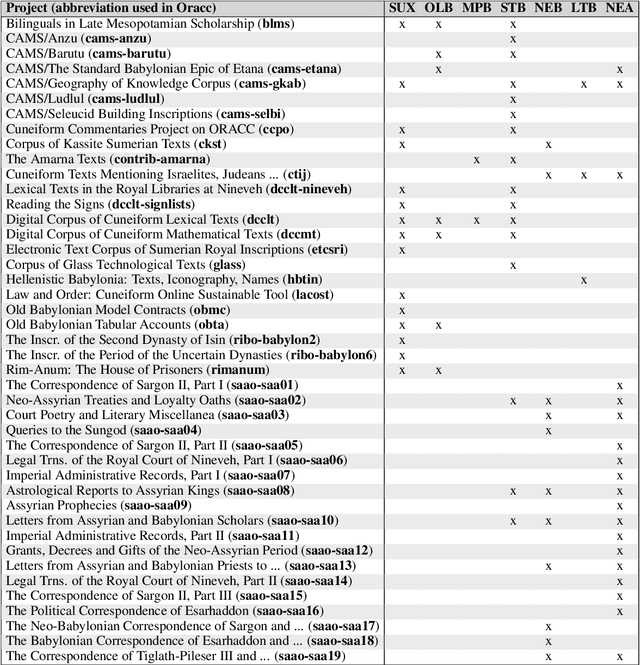

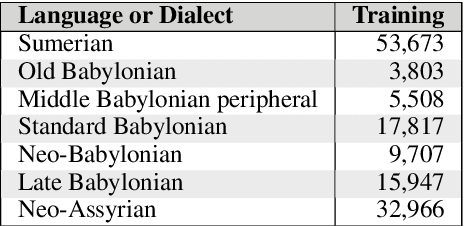
This article introduces a corpus of cuneiform texts from which the dataset for the use of the Cuneiform Language Identification (CLI) 2019 shared task was derived as well as some preliminary language identification experiments conducted using that corpus. We also describe the CLI dataset and how it was derived from the corpus. In addition, we provide some baseline language identification results using the CLI dataset. To the best of our knowledge, the experiments detailed here are the first time automatic language identification methods have been used on cuneiform data.
Automatic Language Identification in Texts: A Survey
Apr 22, 2018
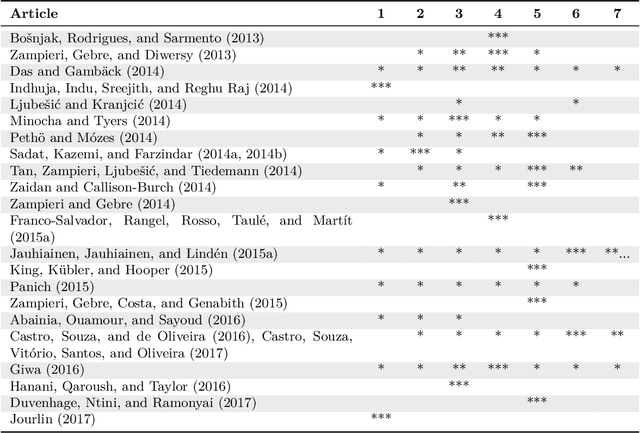
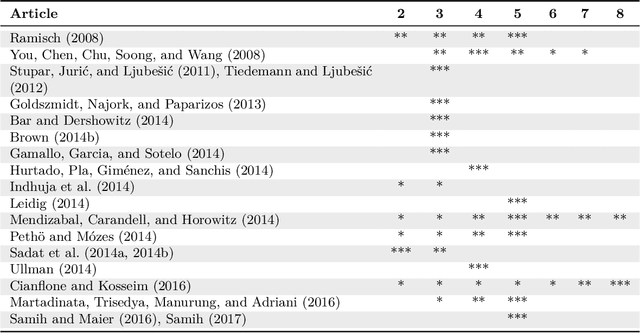
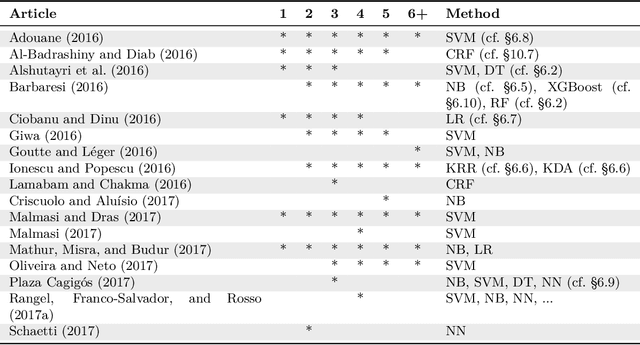
Language identification (LI) is the problem of determining the natural language that a document or part thereof is written in. Automatic LI has been extensively researched for over fifty years. Today, LI is a key part of many text processing pipelines, as text processing techniques generally assume that the language of the input text is known. Research in this area has recently been especially active. This article provides a brief history of LI research, and an extensive survey of the features and methods used so far in the LI literature. For describing the features and methods we introduce a unified notation. We discuss evaluation methods, applications of LI, as well as off-the-shelf LI systems that do not require training by the end user. Finally, we identify open issues, survey the work to date on each issue, and propose future directions for research in LI.