 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk Bounds and Rademacher Complexity in Batch Reinforcement Learning
Mar 25, 2021
This paper considers batch Reinforcement Learning (RL) with general value function approximation. Our study investigates the minimal assumptions to reliably estimate/minimize Bellman error, and characterizes the generalization performance by (local) Rademacher complexities of general function classes, which makes initial steps in bridging the gap between statistical learning theory and batch RL. Concretely, we view the Bellman error as a surrogate loss for the optimality gap, and prove the followings: (1) In double sampling regime, the excess risk of Empirical Risk Minimizer (ERM) is bounded by the Rademacher complexity of the function class. (2) In the single sampling regime, sample-efficient risk minimization is not possible without further assumptions, regardless of algorithms. However, with completeness assumptions, the excess risk of FQI and a minimax style algorithm can be again bounded by the Rademacher complexity of the corresponding function classes. (3) Fast statistical rates can be achieved by using tools of local Rademacher complexity. Our analysis covers a wide range of function classes, including finite classes, linear spaces, kernel spaces, sparse linear features, etc.
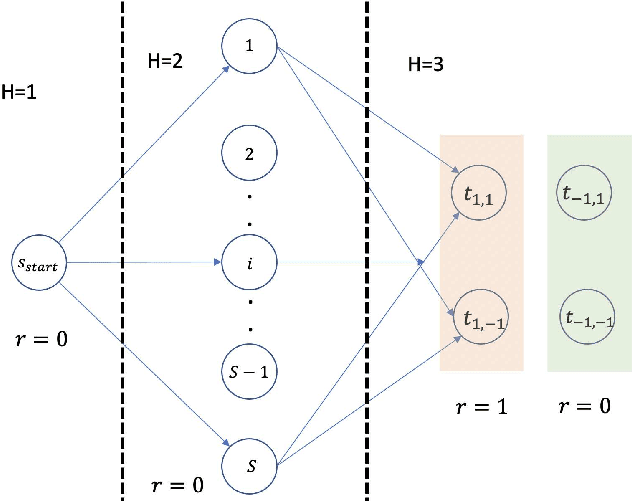
Bootstrapping Statistical Inference for Off-Policy Evaluation
Feb 09, 2021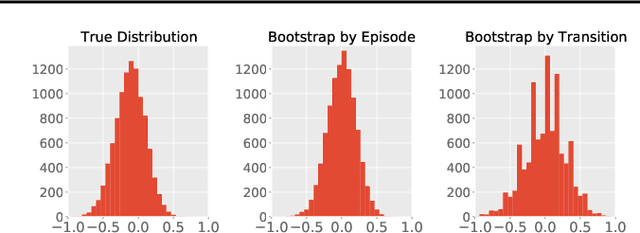
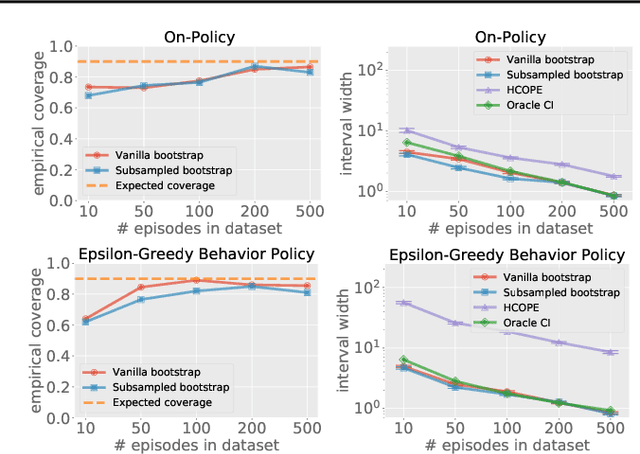
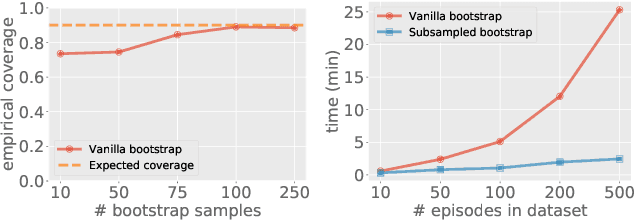
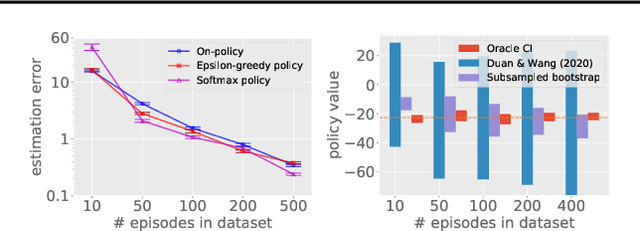
Bootstrapping provides a flexible and effective approach for assessing the quality of batch reinforcement learning, yet its theoretical property is less understood. In this paper, we study the use of bootstrapping in off-policy evaluation (OPE), and in particular, we focus on the fitted Q-evaluation (FQE) that is known to be minimax-optimal in the tabular and linear-model cases. We propose a bootstrapping FQE method for inferring the distribution of the policy evaluation error and show that this method is asymptotically efficient and distributionally consistent for off-policy statistical inference. To overcome the computation limit of bootstrapping, we further adapt a subsampling procedure that improves the runtime by an order of magnitude. We numerically evaluate the bootrapping method in classical RL environments for confidence interval estimation, estimating the variance of off-policy evaluator, and estimating the correlation between multiple off-policy evaluators.
Sparse Feature Selection Makes Batch Reinforcement Learning More Sample Efficient
Nov 08, 2020This paper provides a statistical analysis of high-dimensional batch Reinforcement Learning (RL) using sparse linear function approximation. When there is a large number of candidate features, our result sheds light on the fact that sparsity-aware methods can make batch RL more sample efficient. We first consider the off-policy policy evaluation problem. To evaluate a new target policy, we analyze a Lasso fitted Q-evaluation method and establish a finite-sample error bound that has no polynomial dependence on the ambient dimension. To reduce the Lasso bias, we further propose a post model-selection estimator that applies fitted Q-evaluation to the features selected via group Lasso. Under an additional signal strength assumption, we derive a sharper instance-dependent error bound that depends on a divergence function measuring the distribution mismatch between the data distribution and occupancy measure of the target policy. Further, we study the Lasso fitted Q-iteration for batch policy optimization and establish a finite-sample error bound depending on the ratio between the number of relevant features and restricted minimal eigenvalue of the data's covariance. In the end, we complement the results with minimax lower bounds for batch-data policy evaluation/optimization that nearly match our upper bounds. The results suggest that having well-conditioned data is crucial for sparse batch policy learning.
Minimax-Optimal Off-Policy Evaluation with Linear Function Approximation
Feb 21, 2020This paper studies the statistical theory of batch data reinforcement learning with function approximation. Consider the off-policy evaluation problem, which is to estimate the cumulative value of a new target policy from logged history generated by unknown behavioral policies. We study a regression-based fitted Q iteration method, and show that it is equivalent to a model-based method that estimates a conditional mean embedding of the transition operator. We prove that this method is information-theoretically optimal and has nearly minimal estimation error. In particular, by leveraging contraction property of Markov processes and martingale concentration, we establish a finite-sample instance-dependent error upper bound and a nearly-matching minimax lower bound. The policy evaluation error depends sharply on a restricted $\chi^2$-divergence over the function class between the long-term distribution of the target policy and the distribution of past data. This restricted $\chi^2$-divergence is both instance-dependent and function-class-dependent. It characterizes the statistical limit of off-policy evaluation. Further, we provide an easily computable confidence bound for the policy evaluator, which may be useful for optimistic planning and safe policy improvement.
Learning low-dimensional state embeddings and metastable clusters from time series data
Jun 01, 2019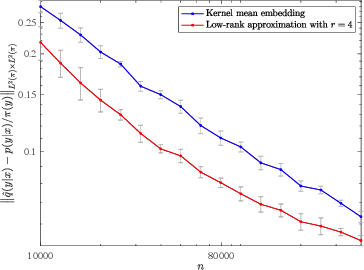
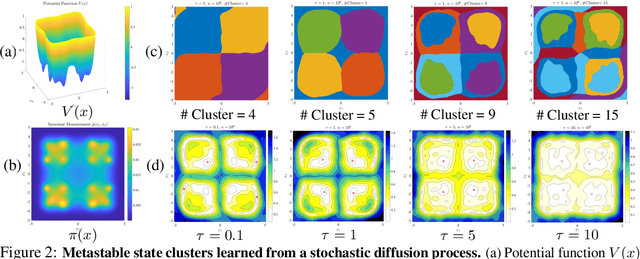
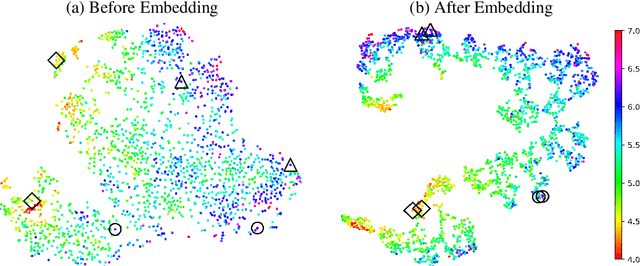
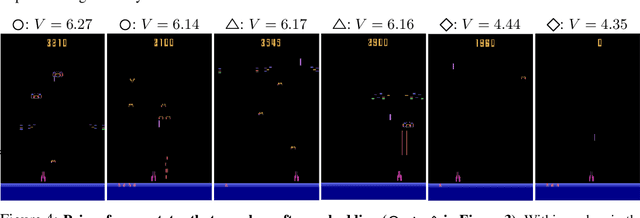
This paper studies how to find compact state embeddings from high-dimensional Markov state trajectories, where the transition kernel has a small intrinsic rank. In the spirit of diffusion map, we propose an efficient method for learning a low-dimensional state embedding and capturing the process's dynamics. This idea also leads to a kernel reshaping method for more accurate nonparametric estimation of the transition function. State embedding can be used to cluster states into metastable sets, thereby identifying the slow dynamics. Sharp statistical error bounds and misclassification rate are proved. Experiment on a simulated dynamical system shows that the state clustering method indeed reveals metastable structures. We also experiment with time series generated by layers of a Deep-Q-Network when playing an Atari game. The embedding method identifies game states to be similar if they share similar future events, even though their raw data are far different.
State Aggregation Learning from Markov Transition Data
Nov 06, 2018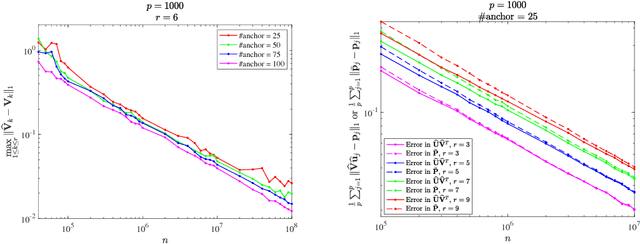
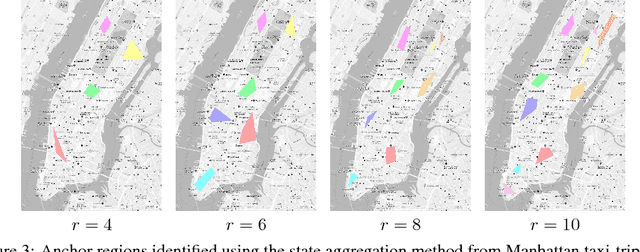
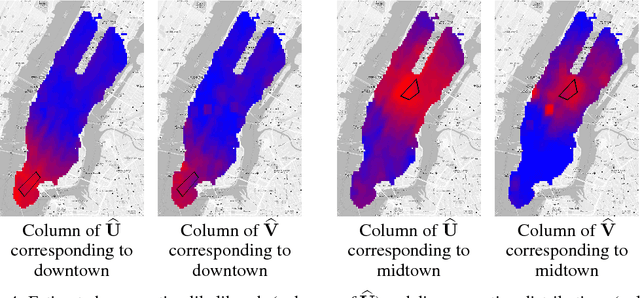
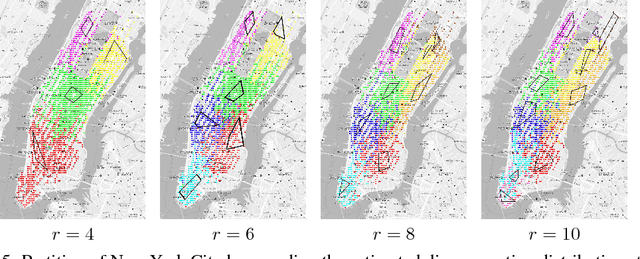
State aggregation is a model reduction method rooted in control theory and reinforcement learning. It reduces the complexity of engineering systems by mapping the system's states into a small number of meta-states. In this paper, we study the unsupervised estimation of unknown state aggregation structures based on Markov trajectories. We formulate the state aggregation of Markov processes into a nonnegative factorization model, where left and right factor matrices correspond to aggregation and disaggregation distributions respectively. By leveraging techniques developed in the context of topic modeling, we propose an efficient polynomial-time algorithm for computing the estimated state aggregation model. Under some "anchor state" assumption, we show that one can reliably recover the state aggregation structure from sample transitions with high probability. Sharp divergence error bounds are proved for the estimated aggregation and disaggregation distributions, and experiments with Manhattan traffic data are provided.
Adaptive Low-Nonnegative-Rank Approximation for State Aggregation of Markov Chains
Oct 14, 2018
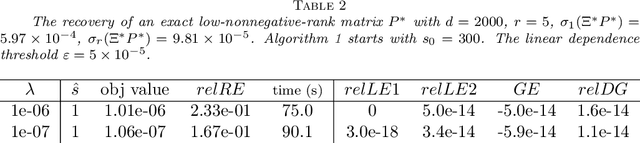
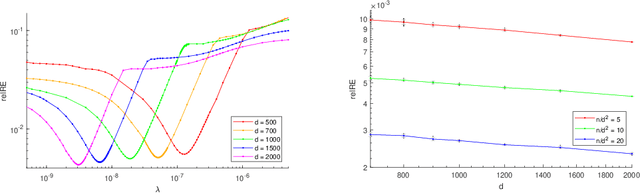
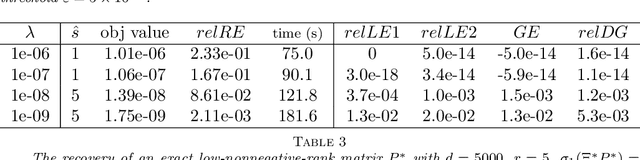
This paper develops a low-nonnegative-rank approximation method to identify the state aggregation structure of a finite-state Markov chain under an assumption that the state space can be mapped into a handful of meta-states. The number of meta-states is characterized by the nonnegative rank of the Markov transition matrix. Motivated by the success of the nuclear norm relaxation in low rank minimization problems, we propose an atomic regularizer as a convex surrogate for the nonnegative rank and formulate a convex optimization problem. Because the atomic regularizer itself is not computationally tractable, we instead solve a sequence of problems involving a nonnegative factorization of the Markov transition matrices by using the proximal alternating linearized minimization method. Two methods for adjusting the rank of factorization are developed so that local minima are escaped. One is to append an additional column to the factorized matrices, which can be interpreted as an approximation of a negative subgradient step. The other is to reduce redundant dimensions by means of linear combinations. Overall, the proposed algorithm very likely converges to the global solution. The efficiency and statistical properties of our approach are illustrated on synthetic data. We also apply our state aggregation algorithm on a Manhattan transportation data set and make extensive comparisons with an existing method.