 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopTrap: Termination Poisoning Attacks on LLM Agents
May 07, 2026Modern LLM agents solve complex tasks by operating in iterative execution loops, where they repeatedly reason, act, and self-evaluate progress to determine when a task is complete. In this work, we show that while this self-directed loop facilitates autonomy, it also introduces a critical risk: by injecting malicious prompts into the agent's context, an adversary can distort the agent's termination judgment, making it believe the task remains incomplete and leading to unbounded computation.To understand this threat, we define and systematically characterize it as Termination Poisoning and design 10 representative attack strategies. Through a empirical study spanning 8 LLM agents and 60 tasks, we demonstrate that different LLM agents exhibit distinct behavioral signatures that determine which strategies succeed. These transferable patterns can serve as principled guidance for crafting effective attacks against previously unseen agents and tasks, enabling scalable red-teaming beyond manually designed templates. Building on these insights, we introduce LoopTrap, an automated red-teaming framework that synthesizes target-specific malicious prompts by exploiting agent behavioral tendencies. LoopTrap first constructs a behavioral profile of the target agent along four vulnerability dimensions via lightweight probing. It then performs adaptive trap synthesis, routing to the most effective strategy and selecting optimal injections via a self-scoring mechanism. Finally, successful traps are abstracted into a reusable skill library, while failed attempts are refined through self-reflection, ensuring continuous improvement. Extensive evaluation shows that LoopTrap achieves an average of 3.57$\times$ step amplification across 8 mainstream agents, with a peak of 25$\times$.
Robust Single-step Adversarial Training with Regularizer
Feb 05, 2021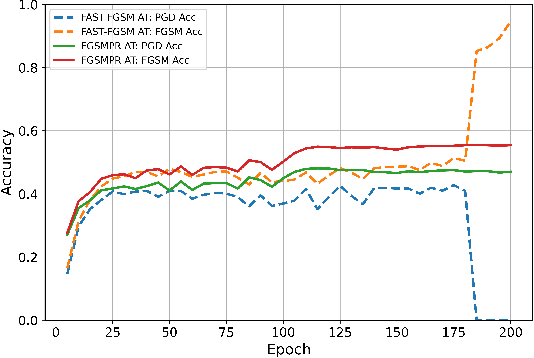

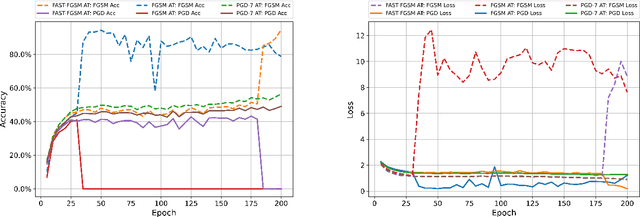

High cost of training time caused by multi-step adversarial example generation is a major challenge in adversarial training. Previous methods try to reduce the computational burden of adversarial training using single-step adversarial example generation schemes, which can effectively improve the efficiency but also introduce the problem of catastrophic overfitting, where the robust accuracy against Fast Gradient Sign Method (FGSM) can achieve nearby 100\% whereas the robust accuracy against Projected Gradient Descent (PGD) suddenly drops to 0\% over a single epoch. To address this problem, we propose a novel Fast Gradient Sign Method with PGD Regularization (FGSMPR) to boost the efficiency of adversarial training without catastrophic overfitting. Our core idea is that single-step adversarial training can not learn robust internal representations of FGSM and PGD adversarial examples. Therefore, we design a PGD regularization term to encourage similar embeddings of FGSM and PGD adversarial examples. The experiments demonstrate that our proposed method can train a robust deep network for L$_\infty$-perturbations with FGSM adversarial training and reduce the gap to multi-step adversarial training.