 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake-A-Video: Text-to-Video Generation without Text-Video Data
Sep 29, 2022

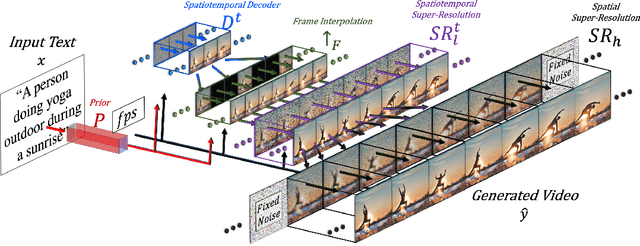
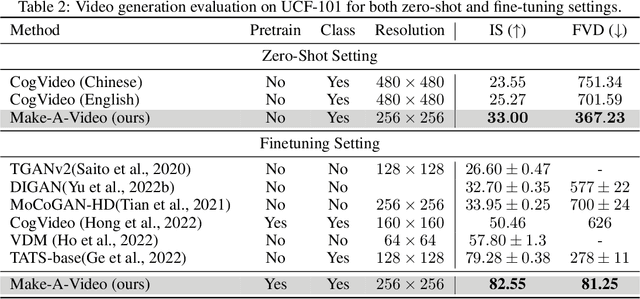
We propose Make-A-Video -- an approach for directly translating the tremendous recent progress in Text-to-Image (T2I) generation to Text-to-Video (T2V). Our intuition is simple: learn what the world looks like and how it is described from paired text-image data, and learn how the world moves from unsupervised video footage. Make-A-Video has three advantages: (1) it accelerates training of the T2V model (it does not need to learn visual and multimodal representations from scratch), (2) it does not require paired text-video data, and (3) the generated videos inherit the vastness (diversity in aesthetic, fantastical depictions, etc.) of today's image generation models. We design a simple yet effective way to build on T2I models with novel and effective spatial-temporal modules. First, we decompose the full temporal U-Net and attention tensors and approximate them in space and time. Second, we design a spatial temporal pipeline to generate high resolution and frame rate videos with a video decoder, interpolation model and two super resolution models that can enable various applications besides T2V. In all aspects, spatial and temporal resolution, faithfulness to text, and quality, Make-A-Video sets the new state-of-the-art in text-to-video generation, as determined by both qualitative and quantitative measures.
KNN-Diffusion: Image Generation via Large-Scale Retrieval
Apr 06, 2022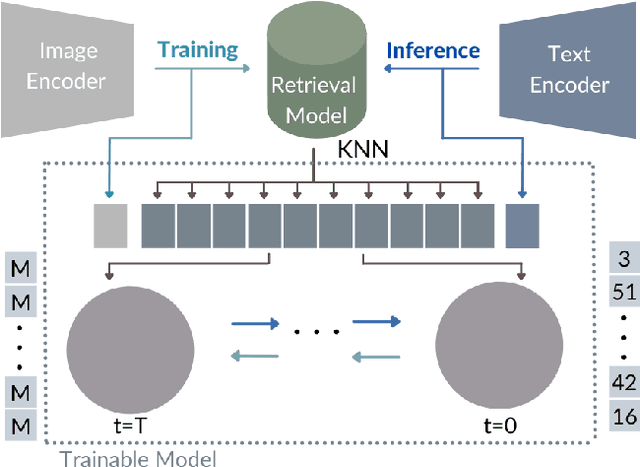
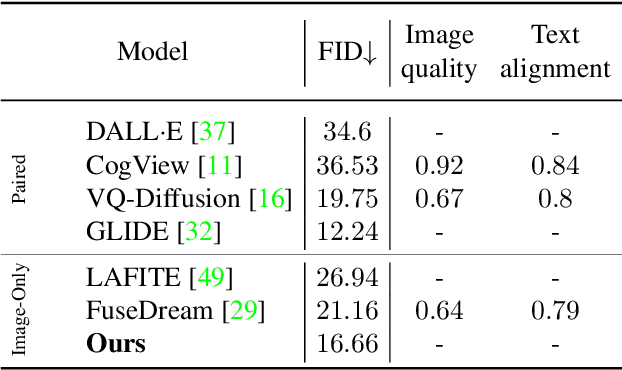
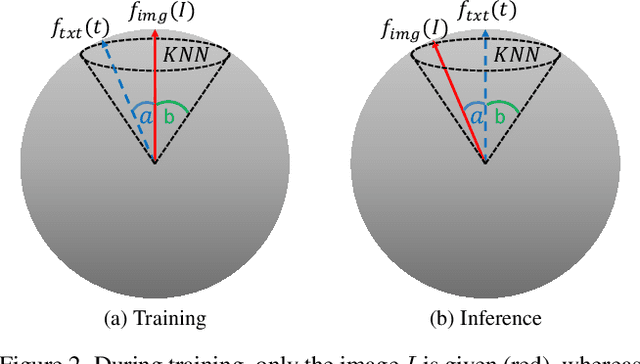

While the availability of massive Text-Image datasets is shown to be extremely useful in training large-scale generative models (e.g. DDPMs, Transformers), their output typically depends on the quality of both the input text, as well as the training dataset. In this work, we show how large-scale retrieval methods, in particular efficient K-Nearest-Neighbors (KNN) search, can be used in order to train a model to adapt to new samples. Learning to adapt enables several new capabilities. Sifting through billions of records at inference time is extremely efficient and can alleviate the need to train or memorize an adequately large generative model. Additionally, fine-tuning trained models to new samples can be achieved by simply adding them to the table. Rare concepts, even without any presence in the training set, can be then leveraged during test time without any modification to the generative model. Our diffusion-based model trains on images only, by leveraging a joint Text-Image multi-modal metric. Compared to baseline methods, our generations achieve state of the art results both in human evaluations as well as with perceptual scores when tested on a public multimodal dataset of natural images, as well as on a collected dataset of 400 million Stickers.
Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
Mar 24, 2022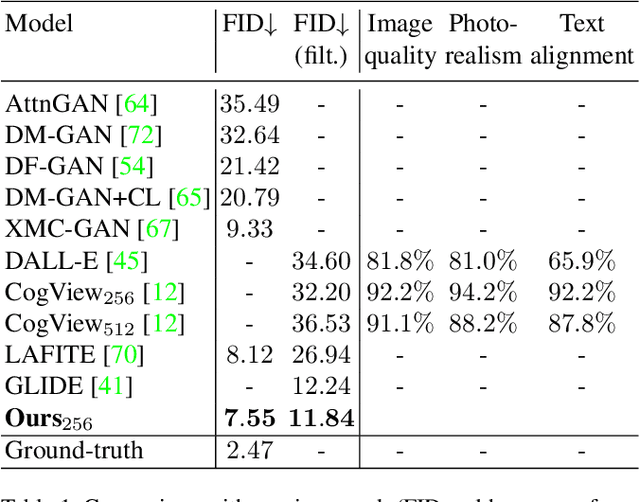

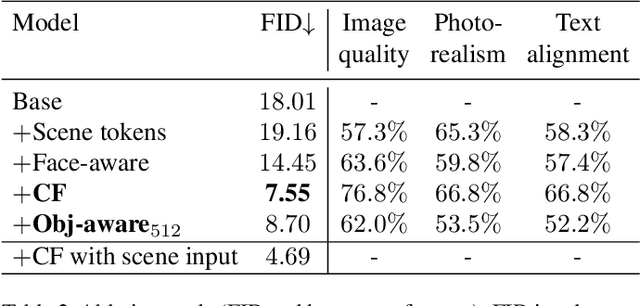

Recent text-to-image generation methods provide a simple yet exciting conversion capability between text and image domains. While these methods have incrementally improved the generated image fidelity and text relevancy, several pivotal gaps remain unanswered, limiting applicability and quality. We propose a novel text-to-image method that addresses these gaps by (i) enabling a simple control mechanism complementary to text in the form of a scene, (ii) introducing elements that substantially improve the tokenization process by employing domain-specific knowledge over key image regions (faces and salient objects), and (iii) adapting classifier-free guidance for the transformer use case. Our model achieves state-of-the-art FID and human evaluation results, unlocking the ability to generate high fidelity images in a resolution of 512x512 pixels, significantly improving visual quality. Through scene controllability, we introduce several new capabilities: (i) Scene editing, (ii) text editing with anchor scenes, (iii) overcoming out-of-distribution text prompts, and (iv) story illustration generation, as demonstrated in the story we wrote.
High Fidelity Speech Regeneration with Application to Speech Enhancement
Jan 31, 2021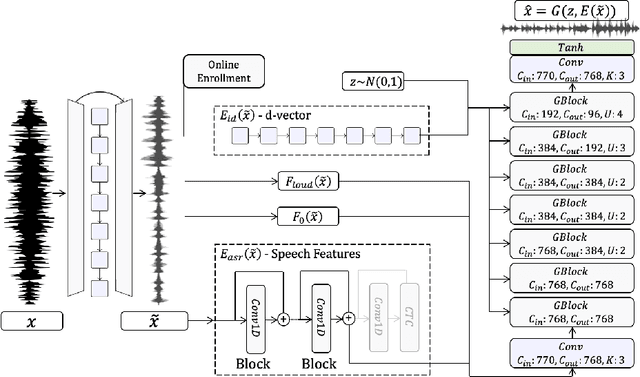
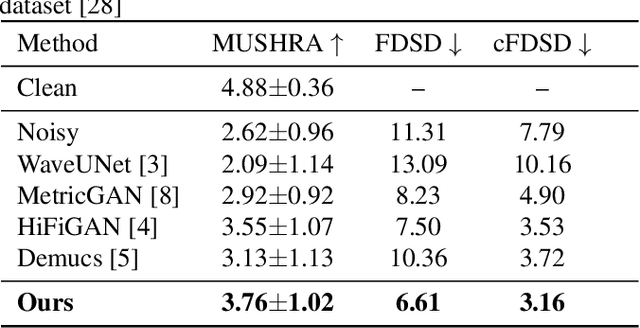
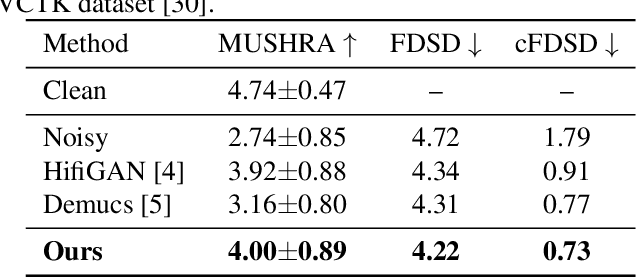
Speech enhancement has seen great improvement in recent years mainly through contributions in denoising, speaker separation, and dereverberation methods that mostly deal with environmental effects on vocal audio. To enhance speech beyond the limitations of the original signal, we take a regeneration approach, in which we recreate the speech from its essence, including the semi-recognized speech, prosody features, and identity. We propose a wav-to-wav generative model for speech that can generate 24khz speech in a real-time manner and which utilizes a compact speech representation, composed of ASR and identity features, to achieve a higher level of intelligibility. Inspired by voice conversion methods, we train to augment the speech characteristics while preserving the identity of the source using an auxiliary identity network. Perceptual acoustic metrics and subjective tests show that the method obtains valuable improvements over recent baselines.
Unsupervised Cross-Domain Singing Voice Conversion
Aug 06, 2020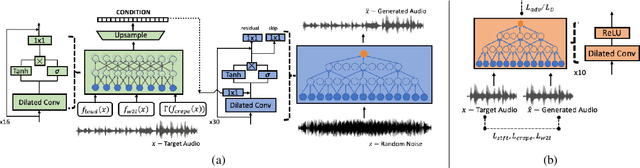
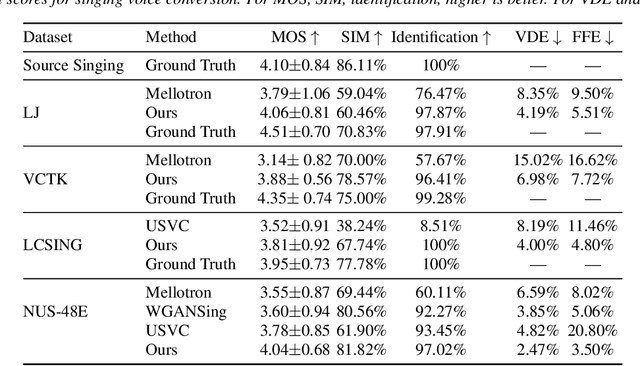
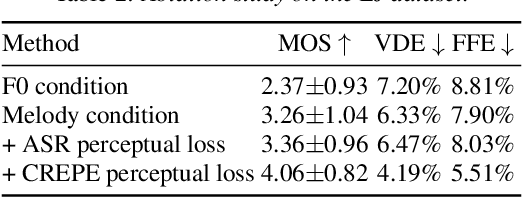
We present a wav-to-wav generative model for the task of singing voice conversion from any identity. Our method utilizes both an acoustic model, trained for the task of automatic speech recognition, together with melody extracted features to drive a waveform-based generator. The proposed generative architecture is invariant to the speaker's identity and can be trained to generate target singers from unlabeled training data, using either speech or singing sources. The model is optimized in an end-to-end fashion without any manual supervision, such as lyrics, musical notes or parallel samples. The proposed approach is fully-convolutional and can generate audio in real-time. Experiments show that our method significantly outperforms the baseline methods while generating convincingly better audio samples than alternative attempts.
Live Face De-Identification in Video
Nov 19, 2019

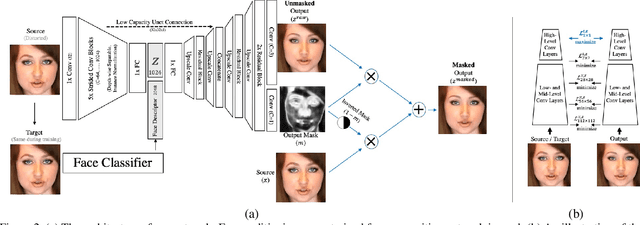
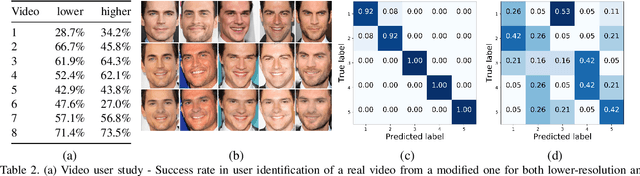
We propose a method for face de-identification that enables fully automatic video modification at high frame rates. The goal is to maximally decorrelate the identity, while having the perception (pose, illumination and expression) fixed. We achieve this by a novel feed-forward encoder-decoder network architecture that is conditioned on the high-level representation of a person's facial image. The network is global, in the sense that it does not need to be retrained for a given video or for a given identity, and it creates natural looking image sequences with little distortion in time.
* ICCV 2019
TTS Skins: Speaker Conversion via ASR
Apr 18, 2019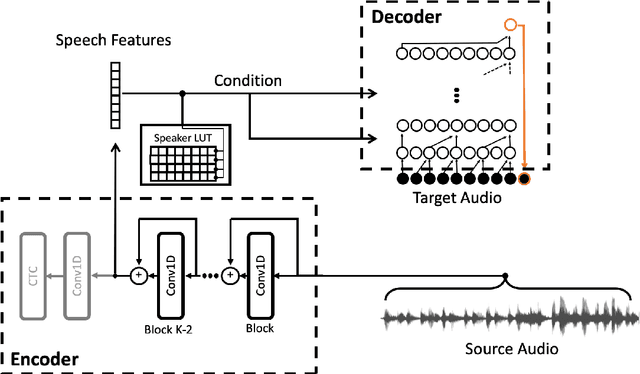

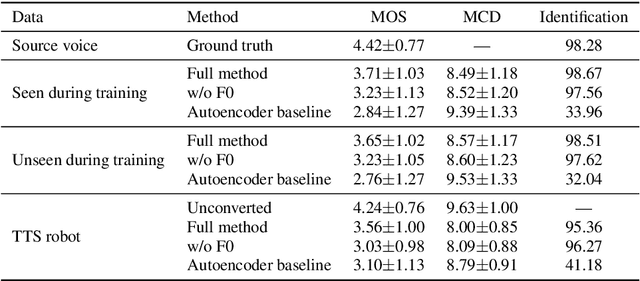
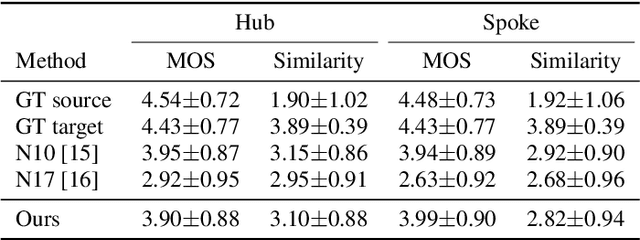
We present a fully convolutional wav-to-wav network for converting between speakers' voices, without relying on text. Our network is based on an encoder-decoder architecture, where the encoder is pre-trained for the task of Automatic Speech Recognition (ASR), and a multi-speaker waveform decoder is trained to reconstruct the original signal in an autoregressive manner. We train the network on narrated audiobooks, and demonstrate the ability to perform multi-voice TTS in those voices, by converting the voice of a TTS robot. We observe no degradation in the quality of the generated voices, in comparison to the reference TTS voice. The modularity of our approach, which separates the target voice generation from the TTS module, enables client-side personalized TTS in a privacy-aware manner.
Vid2Game: Controllable Characters Extracted from Real-World Videos
Apr 17, 2019
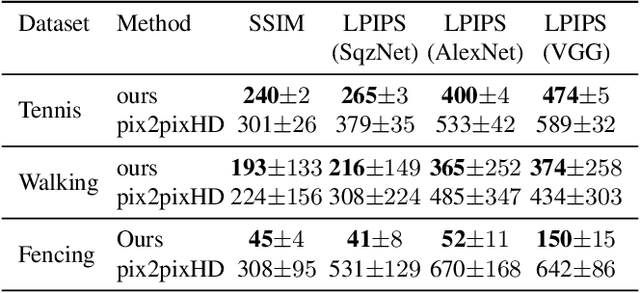

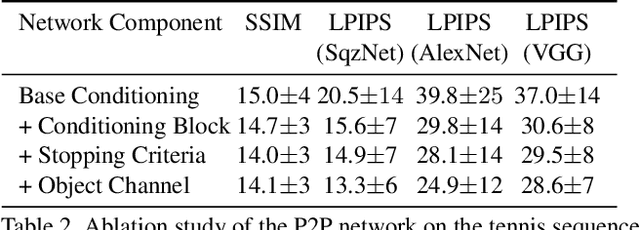
We are given a video of a person performing a certain activity, from which we extract a controllable model. The model generates novel image sequences of that person, according to arbitrary user-defined control signals, typically marking the displacement of the moving body. The generated video can have an arbitrary background, and effectively capture both the dynamics and appearance of the person. The method is based on two networks. The first network maps a current pose, and a single-instance control signal to the next pose. The second network maps the current pose, the new pose, and a given background, to an output frame. Both networks include multiple novelties that enable high-quality performance. This is demonstrated on multiple characters extracted from various videos of dancers and athletes.
Visual Analogies between Atari Games for Studying Transfer Learning in RL
Jul 29, 2018
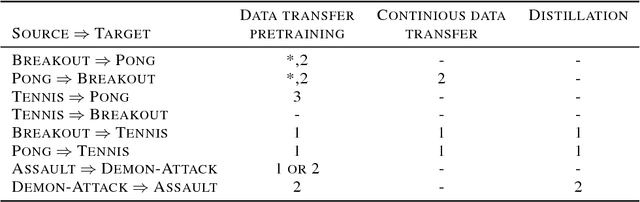

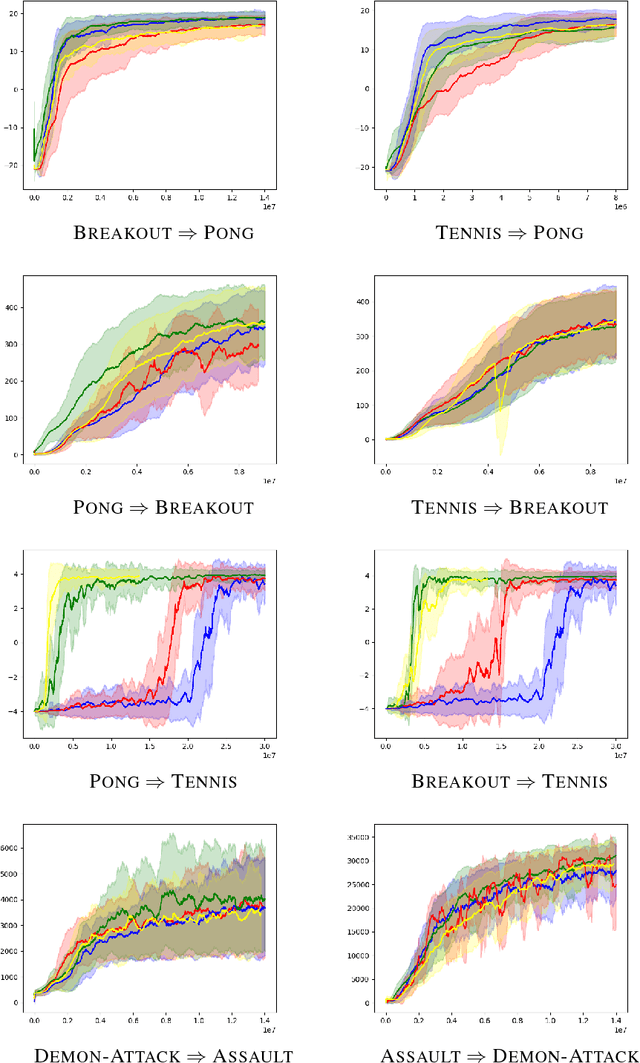
In this work, we ask the following question: Can visual analogies, learned in an unsupervised way, be used in order to transfer knowledge between pairs of games and even play one game using an agent trained for another game? We attempt to answer this research question by creating visual analogies between a pair of games: a source game and a target game. For example, given a video frame in the target game, we map it to an analogous state in the source game and then attempt to play using a trained policy learned for the source game. We demonstrate convincing visual mapping between four pairs of games (eight mappings), which are used to evaluate three transfer learning approaches.
A Universal Music Translation Network
May 23, 2018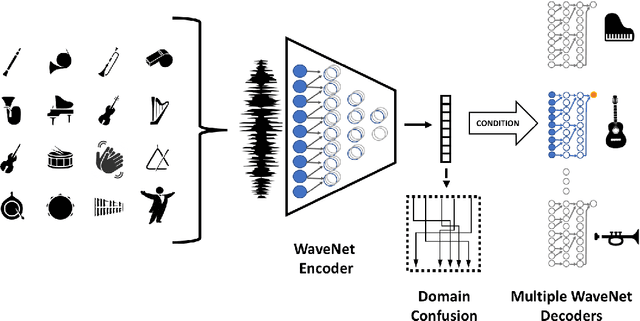
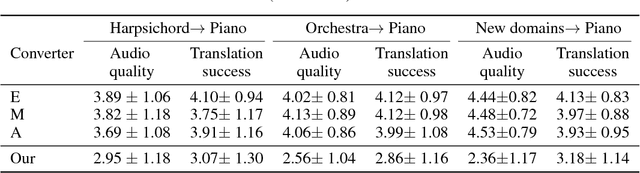
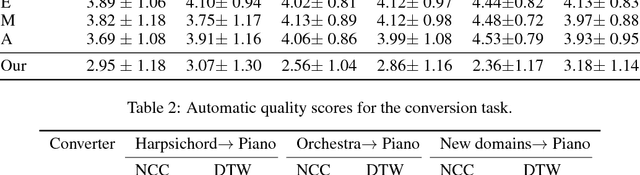
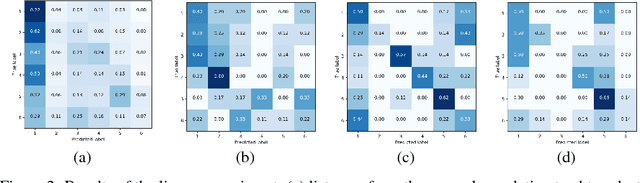
We present a method for translating music across musical instruments, genres, and styles. This method is based on a multi-domain wavenet autoencoder, with a shared encoder and a disentangled latent space that is trained end-to-end on waveforms. Employing a diverse training dataset and large net capacity, the domain-independent encoder allows us to translate even from musical domains that were not seen during training. The method is unsupervised and does not rely on supervision in the form of matched samples between domains or musical transcriptions. We evaluate our method on NSynth, as well as on a dataset collected from professional musicians, and achieve convincing translations, even when translating from whistling, potentially enabling the creation of instrumental music by untrained humans.