 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural-based Pinyin-to-Character Conversion with Adaptive Vocabulary
Nov 11, 2018
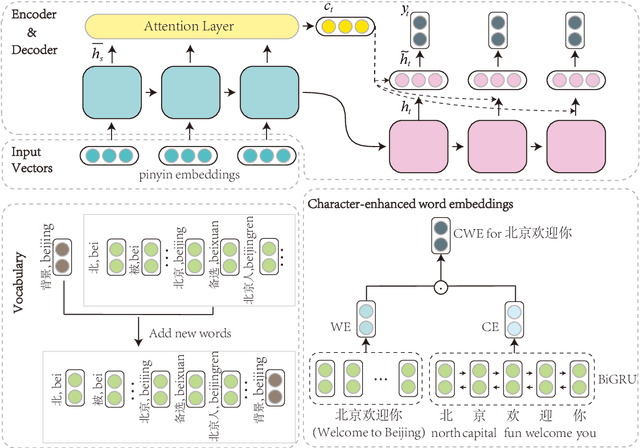
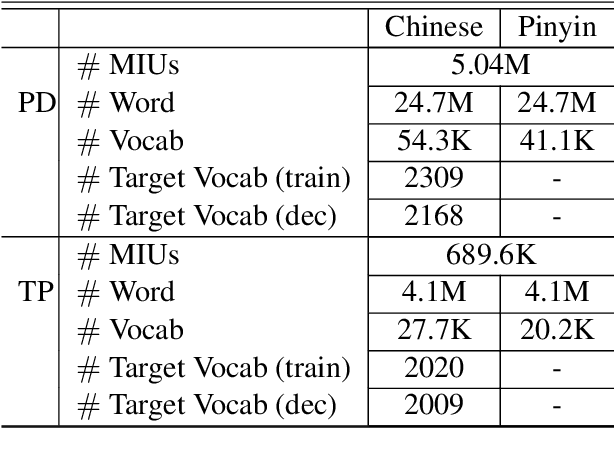
Pinyin-to-character (P2C) conversion is the core component of pinyin-based Chinese input method engine (IME). However, the conversion is seriously compromised by the ambiguities of Chinese characters corresponding to pinyin as well as the predefined fixed vocabularies. To alleviate such inconveniences, we propose a neural P2C conversion model augmented by a large online updating vocabulary with a target vocabulary sampling mechanism. Our experiments show that the proposed approach reduces the decoding time on CPUs up to 50$\%$ on P2C tasks at the same or only negligible change in conversion accuracy, and the online updated vocabulary indeed helps our IME effectively follows user inputting behavior.
Chinese Pinyin Aided IME, Input What You Have Not Keystroked Yet
Sep 02, 2018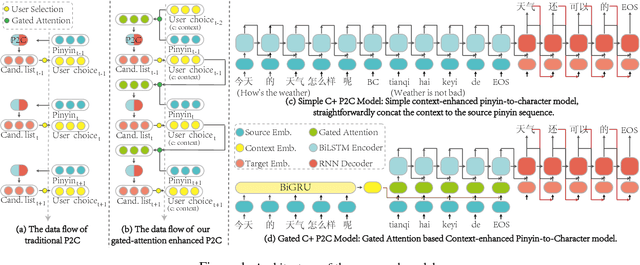
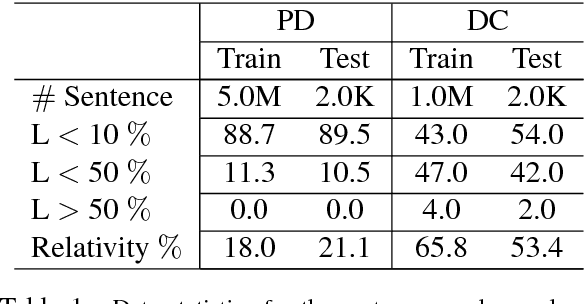
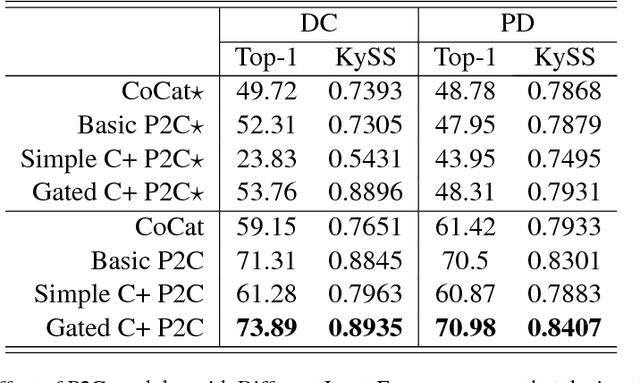

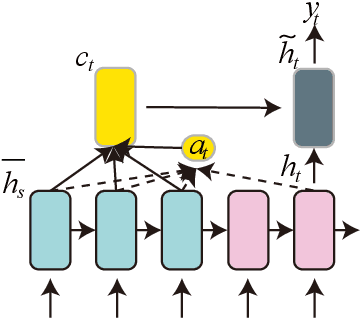
Chinese pinyin input method engine (IME) converts pinyin into character so that Chinese characters can be conveniently inputted into computer through common keyboard. IMEs work relying on its core component, pinyin-to-character conversion (P2C). Usually Chinese IMEs simply predict a list of character sequences for user choice only according to user pinyin input at each turn. However, Chinese inputting is a multi-turn online procedure, which can be supposed to be exploited for further user experience promoting. This paper thus for the first time introduces a sequence-to-sequence model with gated-attention mechanism for the core task in IMEs. The proposed neural P2C model is learned by encoding previous input utterance as extra context to enable our IME capable of predicting character sequence with incomplete pinyin input. Our model is evaluated in different benchmark datasets showing great user experience improvement compared to traditional models, which demonstrates the first engineering practice of building Chinese aided IME.
Lingke: A Fine-grained Multi-turn Chatbot for Customer Service
Aug 10, 2018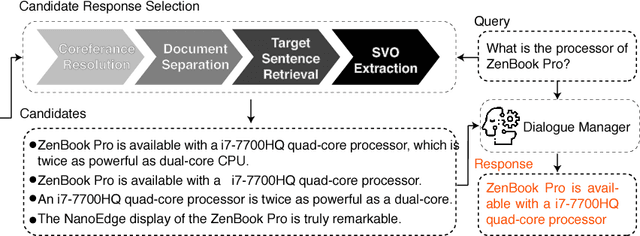

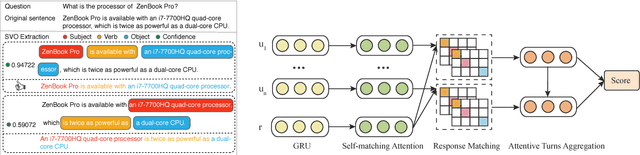
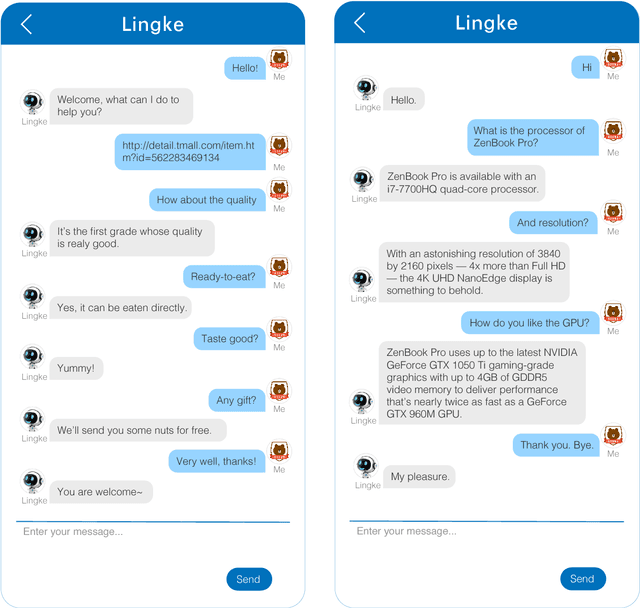
Traditional chatbots usually need a mass of human dialogue data, especially when using supervised machine learning method. Though they can easily deal with single-turn question answering, for multi-turn the performance is usually unsatisfactory. In this paper, we present Lingke, an information retrieval augmented chatbot which is able to answer questions based on given product introduction document and deal with multi-turn conversations. We will introduce a fine-grained pipeline processing to distill responses based on unstructured documents, and attentive sequential context-response matching for multi-turn conversations.
Effective Character-augmented Word Embedding for Machine Reading Comprehension
Aug 07, 2018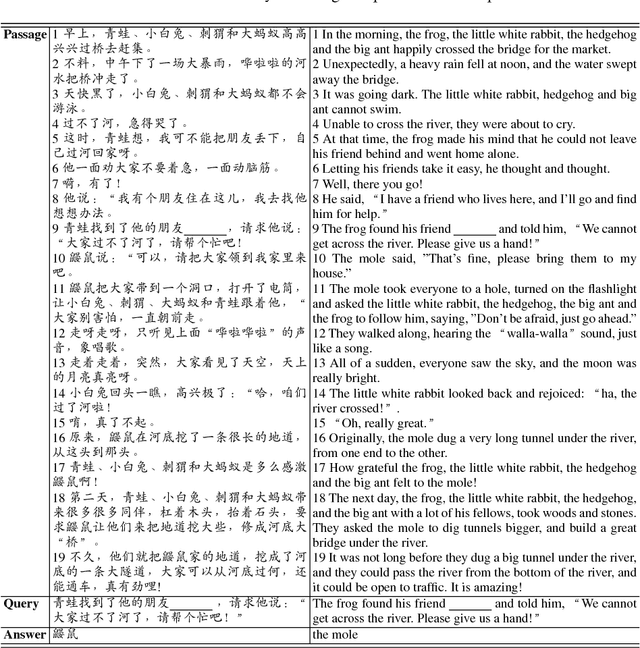
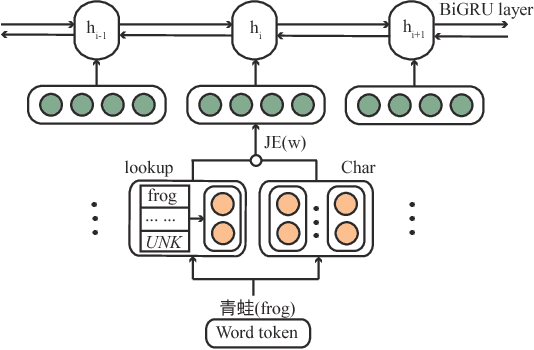
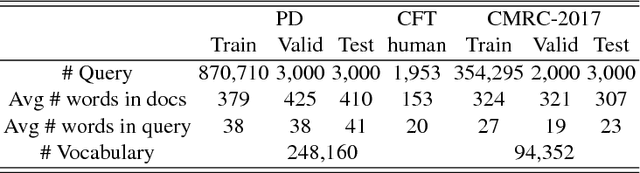
Machine reading comprehension is a task to model relationship between passage and query. In terms of deep learning framework, most of state-of-the-art models simply concatenate word and character level representations, which has been shown suboptimal for the concerned task. In this paper, we empirically explore different integration strategies of word and character embeddings and propose a character-augmented reader which attends character-level representation to augment word embedding with a short list to improve word representations, especially for rare words. Experimental results show that the proposed approach helps the baseline model significantly outperform state-of-the-art baselines on various public benchmarks.
Subword-augmented Embedding for Cloze Reading Comprehension
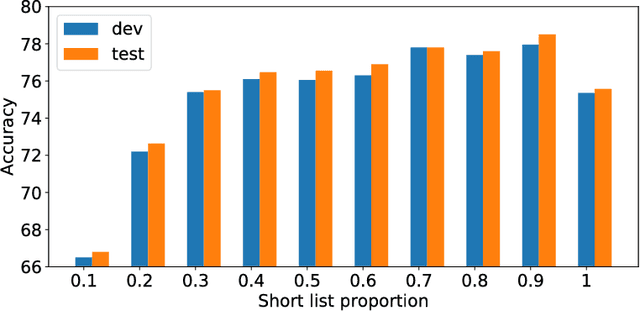
Jun 24, 2018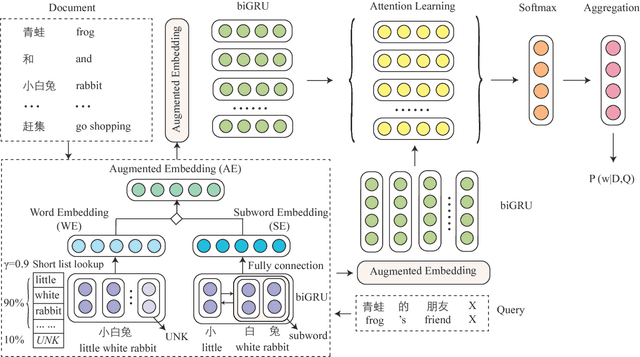
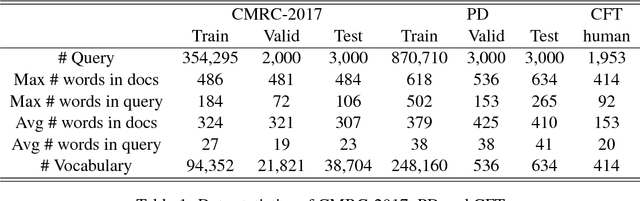
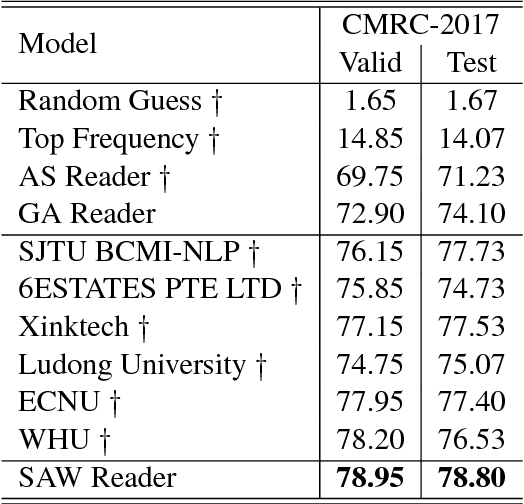
Representation learning is the foundation of machine reading comprehension. In state-of-the-art models, deep learning methods broadly use word and character level representations. However, character is not naturally the minimal linguistic unit. In addition, with a simple concatenation of character and word embedding, previous models actually give suboptimal solution. In this paper, we propose to use subword rather than character for word embedding enhancement. We also empirically explore different augmentation strategies on subword-augmented embedding to enhance the cloze-style reading comprehension model reader. In detail, we present a reader that uses subword-level representation to augment word embedding with a short list to handle rare words effectively. A thorough examination is conducted to evaluate the comprehensive performance and generalization ability of the proposed reader. Experimental results show that the proposed approach helps the reader significantly outperform the state-of-the-art baselines on various public datasets.