 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoute-Constrained Robust Fusion Estimation for MEMS/GNSS Integrated Navigation of Unmanned Ground Vehicles in GNSS Degraded Environments
Jun 18, 2026To address cumulative localization drift of unmanned ground vehicles in structured road environments under severe Global Navigation Satellite System signal occlusion, this paper proposes a robust route-constrained state estimation method. During periods without satellite signals, the proposed method establishes the correspondence between the historical dead reckoning trajectory and local segments of the mission route extracted from a high-definition map, and estimates a route-referenced position via a two-dimensional rigid transformation. The estimated position is then formulated as a pseudo-position observation and incorporated into an Extended Kalman Filter update. In this way, route constraints at the road level can be continuously injected into a unified state estimation framework, thereby suppressing position deviation relative to the mission route while indirectly improving azimuth estimation. To enhance practical applicability, engineering strategies, such as trigger control, matching quality validation, route offset compensation, and single update correction limiting, are further introduced. Experiments in three representative scenarios, including a long tunnel, a multi-segment tunnel, and a curved tunnel, show that the proposed method effectively suppresses error accumulation during satellite outages, reduces the risk of large maximum deviation, and improves localization continuity and road-level usability.
* Accepted workshop paper, 1st Workshop on Robot Meets GNSS and Ranging for Seamless Autonomy, IEEE ICRA 2026
IDOL: Inverse-Dynamics-Guided Future Prediction for End-to-End Autonomous Driving
May 29, 2026End-to-end autonomous driving has emerged as a compelling paradigm for learning planning directly from sensor observations, while recent world-model-based approaches further enrich this paradigm by enabling explicit reasoning about how the scene may evolve in the future. Yet future prediction alone does not guarantee better planning unless the predicted evolution can be converted into planning-relevant trajectory updates. Many current methods still forecast future scene states without explicitly decoding the motion implications hidden in state transitions. As a result, future reasoning often remains descriptively useful but only weakly coupled to executable motion generation. To address this limitation, we propose \mathbf{IDOL}, an inverse-dynamics-guided future prediction framework for world-model-based end-to-end planning in latent BEV space, where inverse dynamics serves as the key bridge between future prediction and trajectory optimization. IDOL first predicts multiple future latent scene states with a BEV world model, then applies an inverse dynamics model to adjacent latent futures to decode transition-aware trajectory features and recover planning-relevant motion deltas that explain how the latent world evolves over time. These inverse-dynamics-derived signals are used to optimize the planned trajectory, turning future forecasting from passive scene anticipation into actionable planning guidance. A lightweight closed-loop refinement module further improves long-horizon consistency by reusing the optimized trajectory for another round of future-aware reasoning. By introducing inverse dynamics into latent future reasoning, IDOL tightens the coupling between world modeling and planning. Extensive experiments on the NAVSIM v1 and NAVSIM v2 benchmarks show that IDOL achieves state-of-the-art performance among comparable methods.
TFCN: Temporal-Frequential Convolutional Network for Single-Channel Speech Enhancement
Jan 03, 2022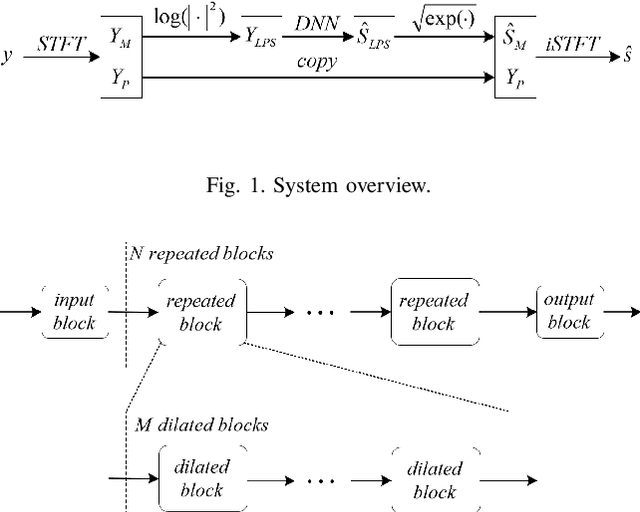
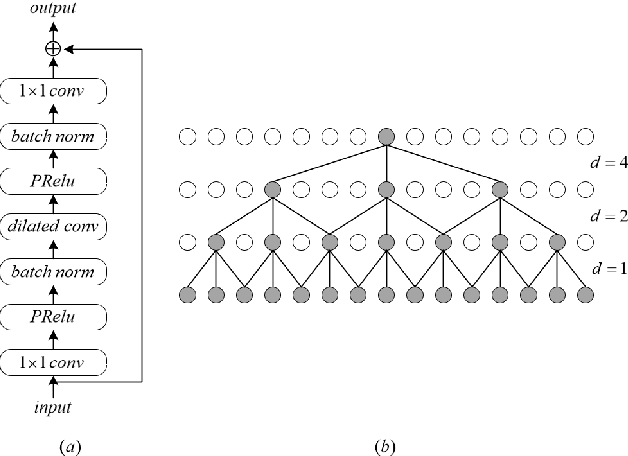
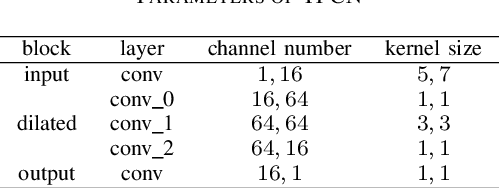
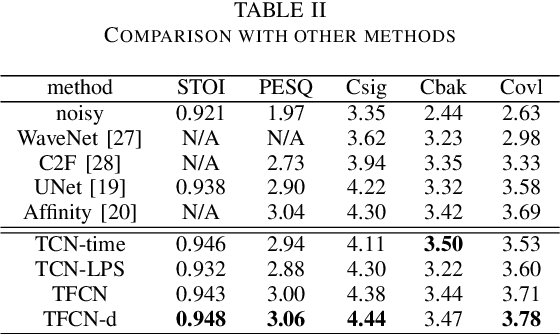
Deep learning based single-channel speech enhancement tries to train a neural network model for the prediction of clean speech signal. There are a variety of popular network structures for single-channel speech enhancement, such as TCNN, UNet, WaveNet, etc. However, these structures usually contain millions of parameters, which is an obstacle for mobile applications. In this work, we proposed a light weight neural network for speech enhancement named TFCN. It is a temporal-frequential convolutional network constructed of dilated convolutions and depth-separable convolutions. We evaluate the performance of TFCN in terms of Short-Time Objective Intelligibility (STOI), perceptual evaluation of speech quality (PESQ) and a series of composite metrics named Csig, Cbak and Covl. Experimental results show that compared with TCN and several other state-of-the-art algorithms, the proposed structure achieves a comparable performance with only 93,000 parameters. Further improvement can be achieved at the cost of more parameters, by introducing dense connections and depth-separable convolutions with normal ones. Experiments also show that the proposed structure can work well both in causal and non-causal situations.