 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDANCE: Doubly Adaptive Neighborhood Conformal Estimation
Feb 24, 2026The recent developments of complex deep learning models have led to unprecedented ability to accurately predict across multiple data representation types. Conformal prediction for uncertainty quantification of these models has risen in popularity, providing adaptive, statistically-valid prediction sets. For classification tasks, conformal methods have typically focused on utilizing logit scores. For pre-trained models, however, this can result in inefficient, overly conservative set sizes when not calibrated towards the target task. We propose DANCE, a doubly locally adaptive nearest-neighbor based conformal algorithm combining two novel nonconformity scores directly using the data's embedded representation. DANCE first fits a task-adaptive kernel regression model from the embedding layer before using the learned kernel space to produce the final prediction sets for uncertainty quantification. We test against state-of-the-art local, task-adapted and zero-shot conformal baselines, demonstrating DANCE's superior blend of set size efficiency and robustness across various datasets.
Overlapping Clustering Models, and One SVM to Bind Them All
Nov 05, 2018
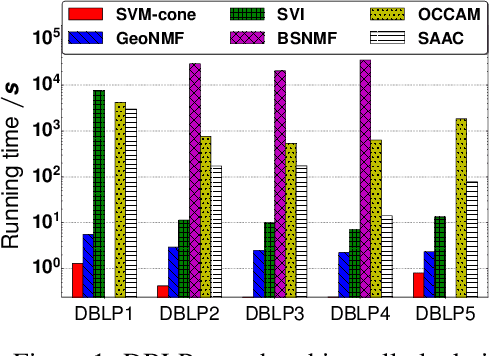
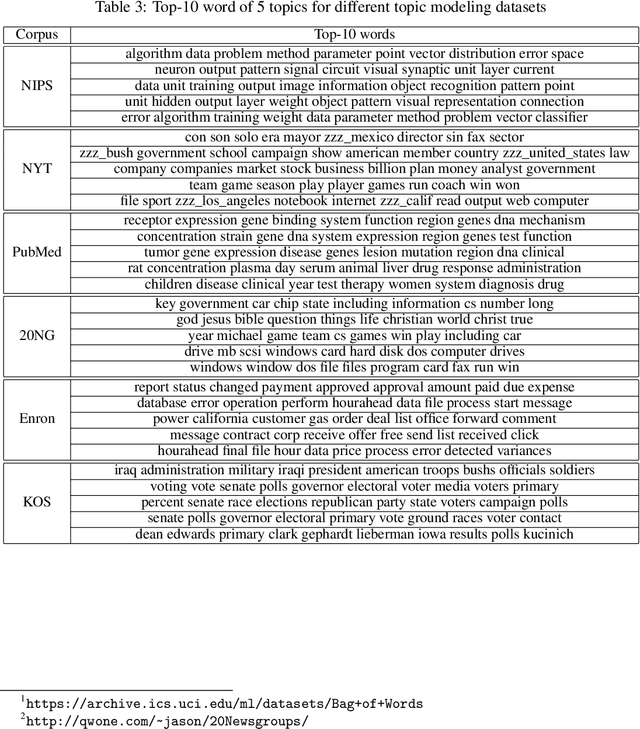
People belong to multiple communities, words belong to multiple topics, and books cover multiple genres; overlapping clusters are commonplace. Many existing overlapping clustering methods model each person (or word, or book) as a non-negative weighted combination of "exemplars" who belong solely to one community, with some small noise. Geometrically, each person is a point on a cone whose corners are these exemplars. This basic form encompasses the widely used Mixed Membership Stochastic Blockmodel of networks (Airoldi et al., 2008) and its degree-corrected variants (Jin et al., 2017), as well as topic models such as LDA (Blei et al., 2003). We show that a simple one-class SVM yields provably consistent parameter inference for all such models, and scales to large datasets. Experimental results on several simulated and real datasets show our algorithm (called SVM-cone) is both accurate and scalable.
On Mixed Memberships and Symmetric Nonnegative Matrix Factorizations
Jun 23, 2017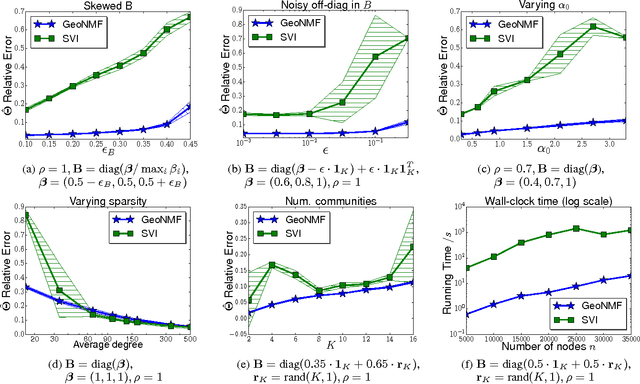
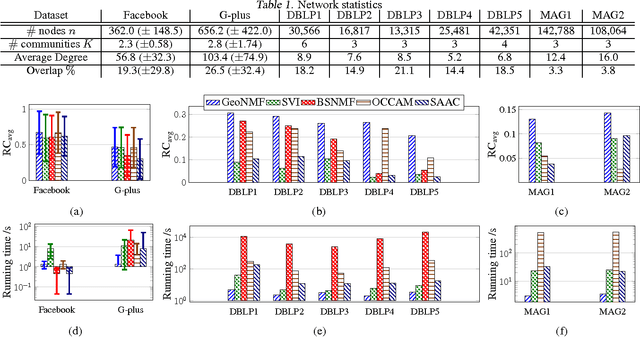
The problem of finding overlapping communities in networks has gained much attention recently. Optimization-based approaches use non-negative matrix factorization (NMF) or variants, but the global optimum cannot be provably attained in general. Model-based approaches, such as the popular mixed-membership stochastic blockmodel or MMSB (Airoldi et al., 2008), use parameters for each node to specify the overlapping communities, but standard inference techniques cannot guarantee consistency. We link the two approaches, by (a) establishing sufficient conditions for the symmetric NMF optimization to have a unique solution under MMSB, and (b) proposing a computationally efficient algorithm called GeoNMF that is provably optimal and hence consistent for a broad parameter regime. We demonstrate its accuracy on both simulated and real-world datasets.