 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptive Robotic Gesture Recognition with Unsupervised Kinematic-Visual Data Alignment
Mar 06, 2021
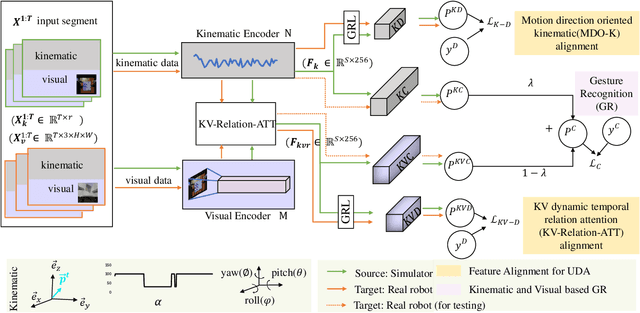
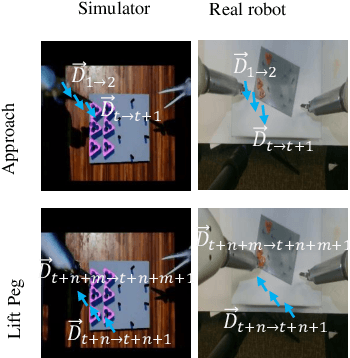
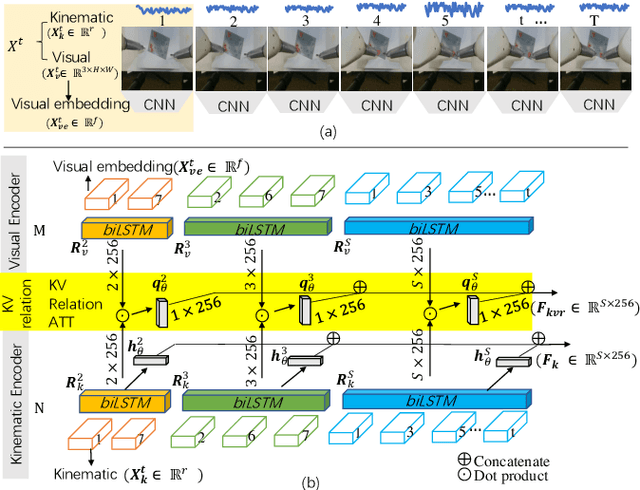
Automated surgical gesture recognition is of great importance in robot-assisted minimally invasive surgery. However, existing methods assume that training and testing data are from the same domain, which suffers from severe performance degradation when a domain gap exists, such as the simulator and real robot. In this paper, we propose a novel unsupervised domain adaptation framework which can simultaneously transfer multi-modality knowledge, i.e., both kinematic and visual data, from simulator to real robot. It remedies the domain gap with enhanced transferable features by using temporal cues in videos, and inherent correlations in multi-modal towards recognizing gesture. Specifically, we first propose an MDO-K to align kinematics, which exploits temporal continuity to transfer motion directions with smaller gap rather than position values, relieving the adaptation burden. Moreover, we propose a KV-Relation-ATT to transfer the co-occurrence signals of kinematics and vision. Such features attended by correlation similarity are more informative for enhancing domain-invariance of the model. Two feature alignment strategies benefit the model mutually during the end-to-end learning process. We extensively evaluate our method for gesture recognition using DESK dataset with peg transfer procedure. Results show that our approach recovers the performance with great improvement gains, up to 12.91% in ACC and 20.16% in F1score without using any annotations in real robot.
LRTD: Long-Range Temporal Dependency based Active Learning for Surgical Workflow Recognition
Apr 23, 2020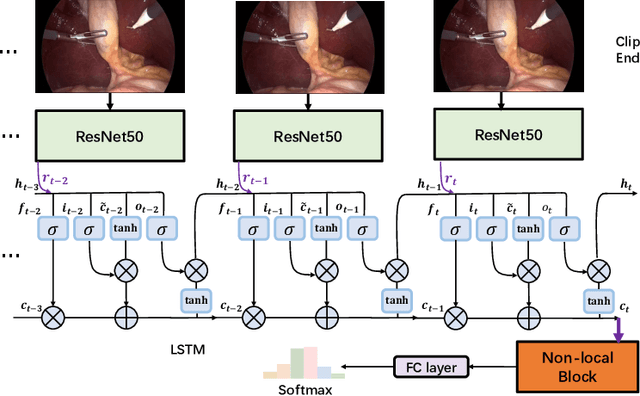
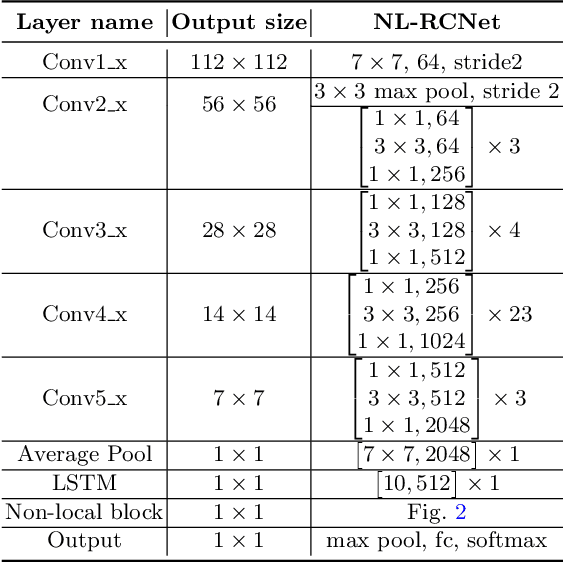
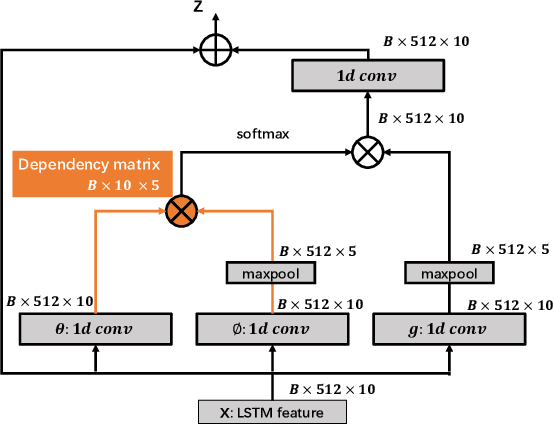
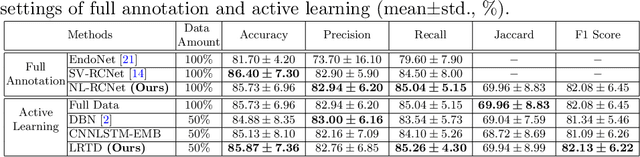
Automatic surgical workflow recognition in video is an essentially fundamental yet challenging problem for developing computer-assisted and robotic-assisted surgery. Existing approaches with deep learning have achieved remarkable performance on analysis of surgical videos, however, heavily relying on large-scale labelled datasets. Unfortunately, the annotation is not often available in abundance, because it requires the domain knowledge of surgeons. In this paper, we propose a novel active learning method for cost-effective surgical video analysis. Specifically, we propose a non-local recurrent convolutional network (NL-RCNet), which introduces non-local block to capture the long-range temporal dependency (LRTD) among continuous frames. We then formulate an intra-clip dependency score to represent the overall dependency within this clip. By ranking scores among clips in unlabelled data pool, we select the clips with weak dependencies to annotate, which indicates the most informative ones to better benefit network training. We validate our approach on a large surgical video dataset (Cholec80) by performing surgical workflow recognition task. By using our LRTD based selection strategy, we can outperform other state-of-the-art active learning methods. Using only up to 50% of samples, our approach can exceed the performance of full-data training.
An Active Learning Approach for Reducing Annotation Cost in Skin Lesion Analysis
Sep 05, 2019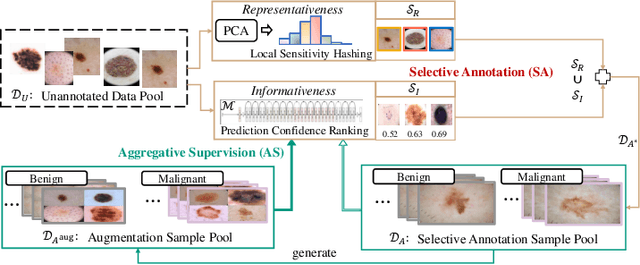
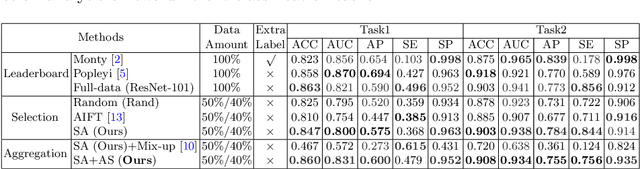

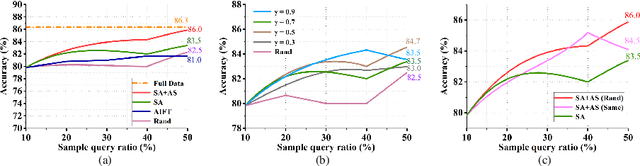
Automated skin lesion analysis is very crucial in clinical practice, as skin cancer is among the most common human malignancy. Existing approaches with deep learning have achieved remarkable performance on this challenging task, however, heavily relying on large-scale labelled datasets. In this paper, we present a novel active learning framework for cost-effective skin lesion analysis. The goal is to effectively select and utilize much fewer labelled samples, while the network can still achieve state-of-the-art performance. Our sample selection criteria complementarily consider both informativeness and representativeness, derived from decoupled aspects of measuring model certainty and covering sample diversity. To make wise use of the selected samples, we further design a simple yet effective strategy to aggregate intra-class images in pixel space, as a new form of data augmentation. We validate our proposed method on data of ISIC 2017 Skin Lesion Classification Challenge for two tasks. Using only up to 50% of samples, our approach can achieve state-of-the-art performances on both tasks, which are comparable or exceeding the accuracies with full-data training, and outperform other well-known active learning methods by a large margin.
Robust Learning at Noisy Labeled Medical Images: Applied to Skin Lesion Classification
Jan 24, 2019
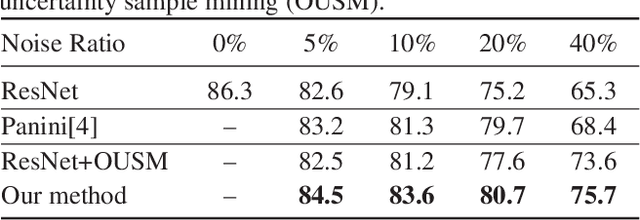
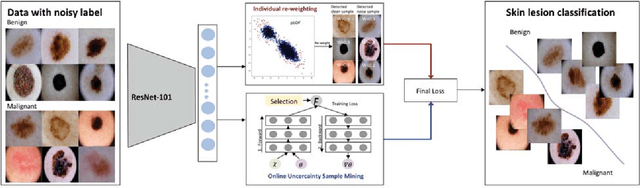
Deep neural networks (DNNs) have achieved great success in a wide variety of medical image analysis tasks. However, these achievements indispensably rely on the accurately-annotated datasets. If with the noisy-labeled images, the training procedure will immediately encounter difficulties, leading to a suboptimal classifier. This problem is even more crucial in the medical field, given that the annotation quality requires great expertise. In this paper, we propose an effective iterative learning framework for noisy-labeled medical image classification, to combat the lacking of high quality annotated medical data. Specifically, an online uncertainty sample mining method is proposed to eliminate the disturbance from noisy-labeled images. Next, we design a sample re-weighting strategy to preserve the usefulness of correctly-labeled hard samples. Our proposed method is validated on skin lesion classification task, and achieved very promising results.
* Accepted for publication at ISBI 2019