 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking time series classification -- Functional data vs machine learning approaches
Nov 18, 2019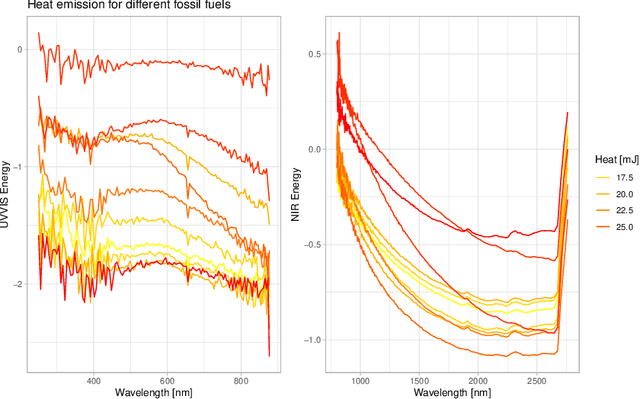
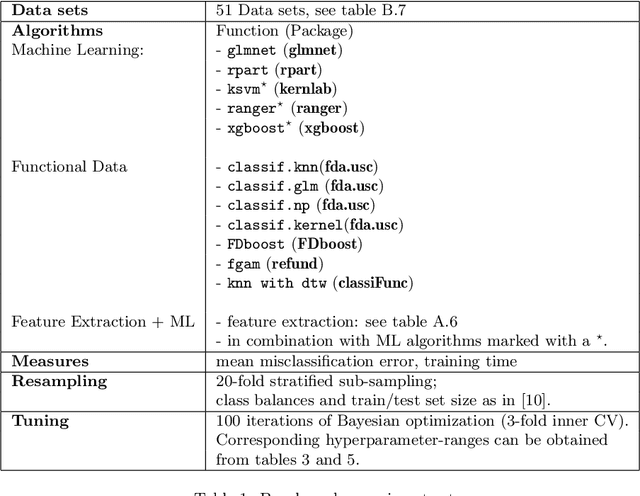
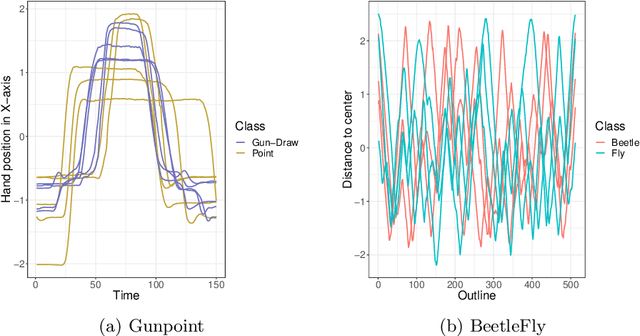
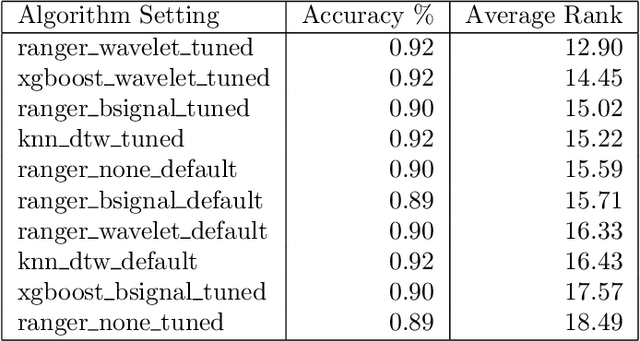
Time series classification problems have drawn increasing attention in the machine learning and statistical community. Closely related is the field of functional data analysis (FDA): it refers to the range of problems that deal with the analysis of data that is continuously indexed over some domain. While often employing different methods, both fields strive to answer similar questions, a common example being classification or regression problems with functional covariates. We study methods from functional data analysis, such as functional generalized additive models, as well as functionality to concatenate (functional-) feature extraction or basis representations with traditional machine learning algorithms like support vector machines or classification trees. In order to assess the methods and implementations, we run a benchmark on a wide variety of representative (time series) data sets, with in-depth analysis of empirical results, and strive to provide a reference ranking for which method(s) to use for non-expert practitioners. Additionally, we provide a software framework in R for functional data analysis for supervised learning, including machine learning and more linear approaches from statistics. This allows convenient access, and in connection with the machine-learning toolbox mlr, those methods can now also be tuned and benchmarked.
Tutorial and Survey on Probabilistic Graphical Model and Variational Inference in Deep Reinforcement Learning
Oct 04, 2019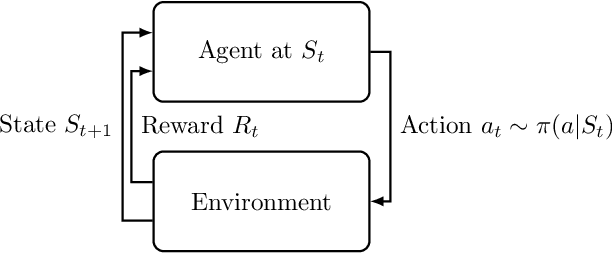
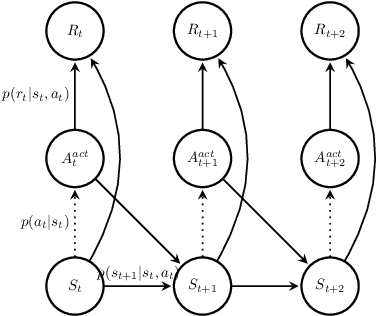
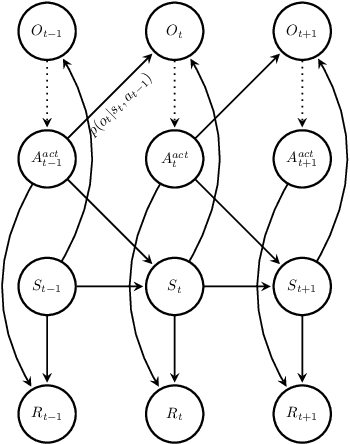
Probabilistic Graphical Modeling and Variational Inference play an important role in recent advances in Deep Reinforcement Learning. Aiming at a self-consistent tutorial survey, this article illustrates basic concepts of reinforcement learning with Probabilistic Graphical Models, as well as derivation of some basic formula as a recap. Reviews and comparisons on recent advances in deep reinforcement learning with different research directions are made from various aspects. We offer Probabilistic Graphical Models, detailed explanation and derivation to several use cases of Variational Inference, which serve as a complementary material on top of the original contributions.
Resampling-based Assessment of Robustness to Distribution Shift for Deep Neural Networks
Jun 07, 2019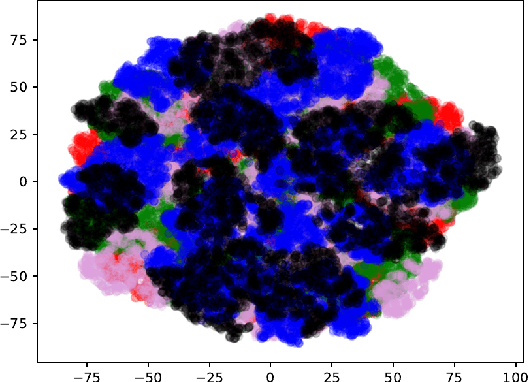
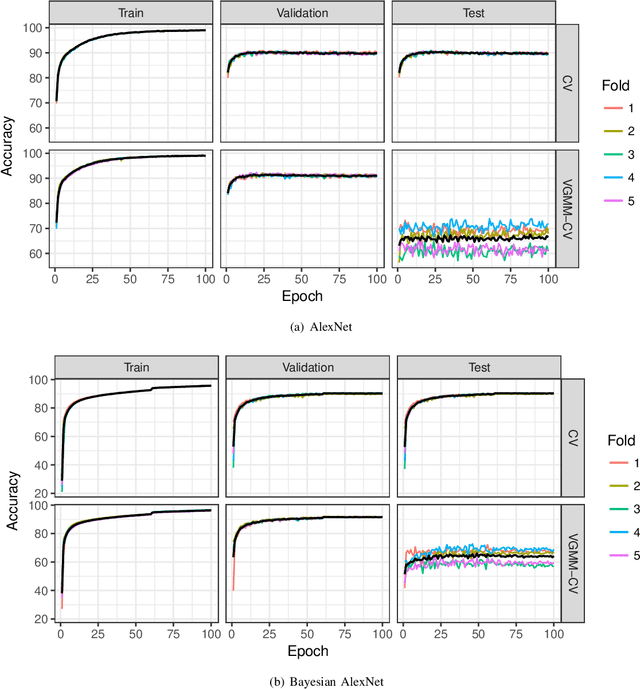
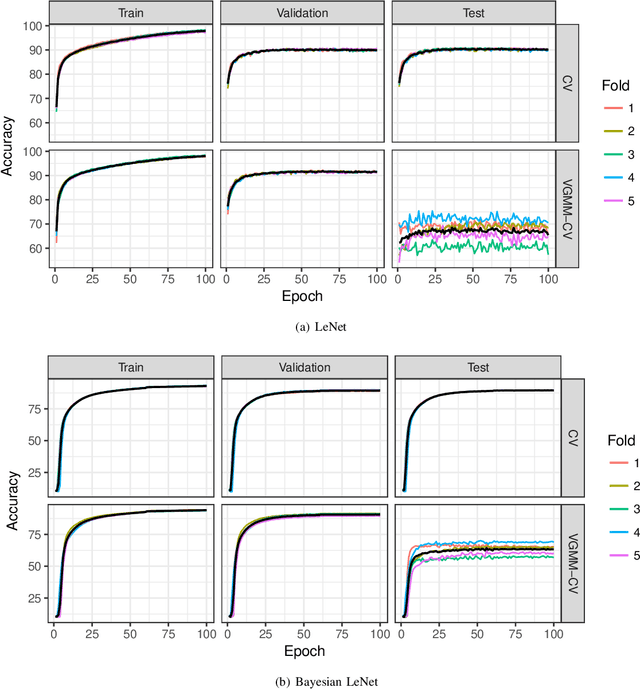
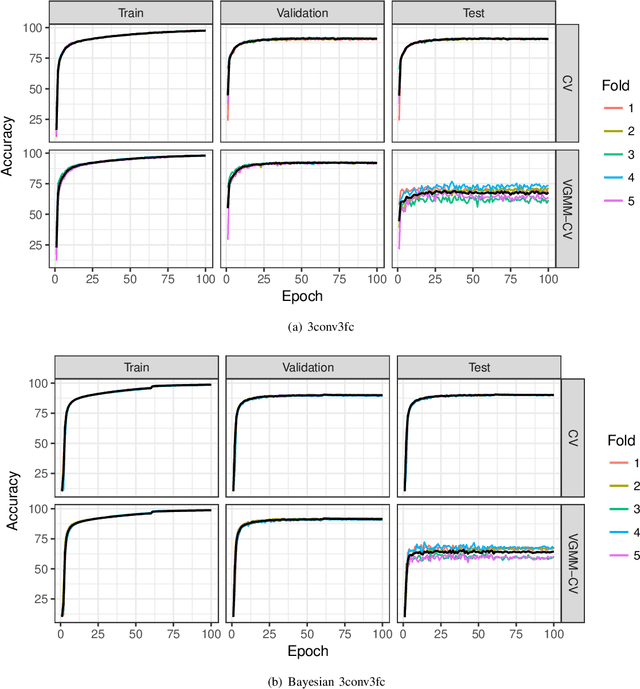
A novel resampling framework is proposed to evaluate the robustness and generalization capability of deep learning models with respect to distribution shift. We use Auto Encoder Variational Bayes to find a latent representation of the data, on which a Variational Gaussian Mixture Model is applied to deliberately create distribution shift by dividing the dataset into different clusters. Wasserstein distance is used to characterize the extent of distribution shift between the training and the testing data splits. We compare several conventional Convolutional Neural Network (CNN) architectures as well as Bayesian CNN models for image classification on the Fashion-MNIST dataset to assess their robustness under the deliberately created distribution shift.
Maximum Entropy-Regularized Multi-Goal Reinforcement Learning
May 28, 2019
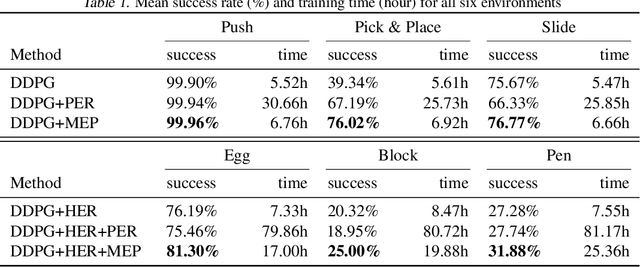
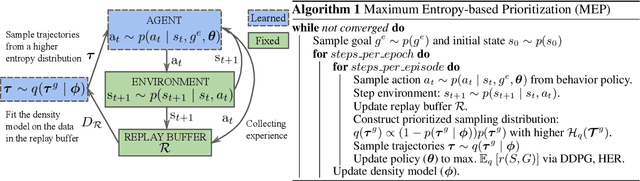
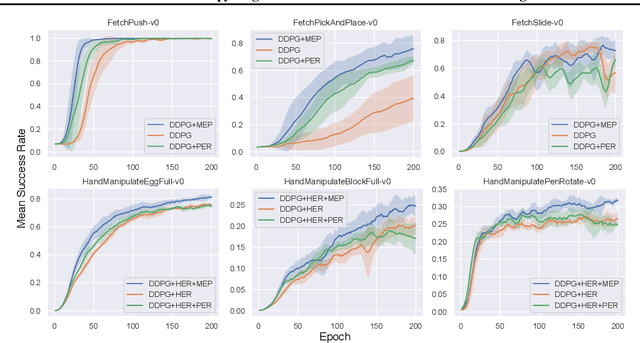
In Multi-Goal Reinforcement Learning, an agent learns to achieve multiple goals with a goal-conditioned policy. During learning, the agent first collects the trajectories into a replay buffer, and later these trajectories are selected randomly for replay. However, the achieved goals in the replay buffer are often biased towards the behavior policies. From a Bayesian perspective, when there is no prior knowledge about the target goal distribution, the agent should learn uniformly from diverse achieved goals. Therefore, we first propose a novel multi-goal RL objective based on weighted entropy. This objective encourages the agent to maximize the expected return, as well as to achieve more diverse goals. Secondly, we developed a maximum entropy-based prioritization framework to optimize the proposed objective. For evaluation of this framework, we combine it with Deep Deterministic Policy Gradient, both with or without Hindsight Experience Replay. On a set of multi-goal robotic tasks of OpenAI Gym, we compare our method with other baselines and show promising improvements in both performance and sample-efficiency.
* Published in International Conference on Machine Learning (ICML 2019), Long Beach, USA. arXiv admin note: text overlap with arXiv:1902.08039
ReinBo: Machine Learning pipeline search and configuration with Bayesian Optimization embedded Reinforcement Learning
Apr 10, 2019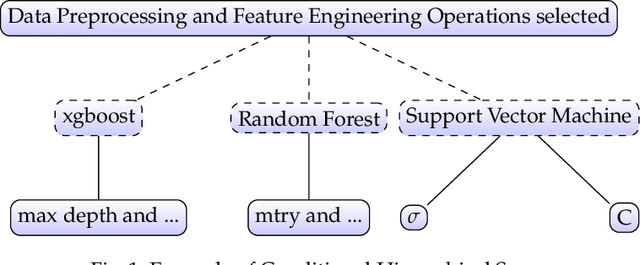

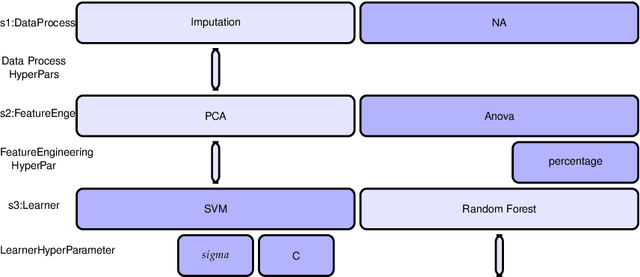
Machine learning pipeline potentially consists of several stages of operations like data preprocessing, feature engineering and machine learning model training. Each operation has a set of hyper-parameters, which can become irrelevant for the pipeline when the operation is not selected. This gives rise to a hierarchical conditional hyper-parameter space. To optimize this mixed continuous and discrete conditional hierarchical hyper-parameter space, we propose an efficient pipeline search and configuration algorithm which combines the power of Reinforcement Learning and Bayesian Optimization. Empirical results show that our method performs favorably compared to state of the art methods like Auto-sklearn , TPOT, Tree Parzen Window, and Random Search.
High Dimensional Restrictive Federated Model Selection with multi-objective Bayesian Optimization over shifted distributions
Feb 24, 2019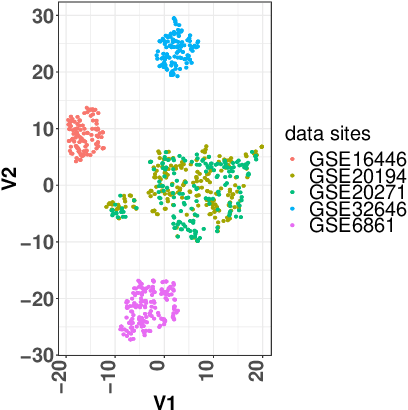
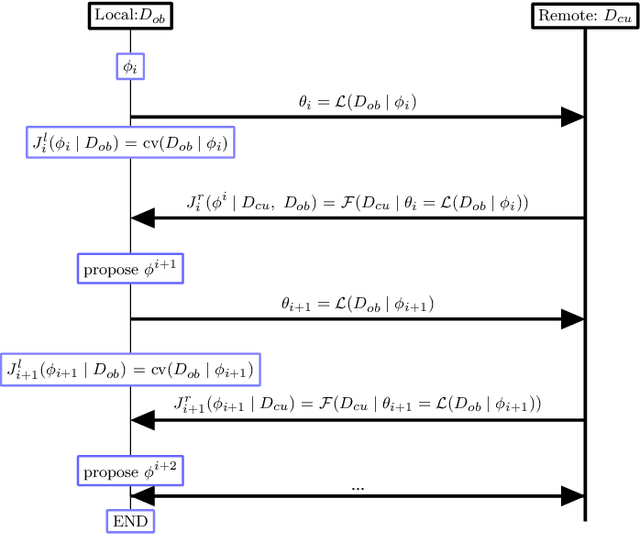
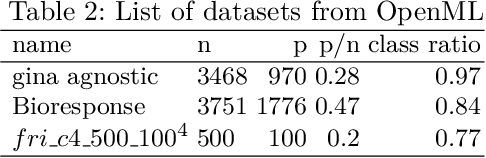

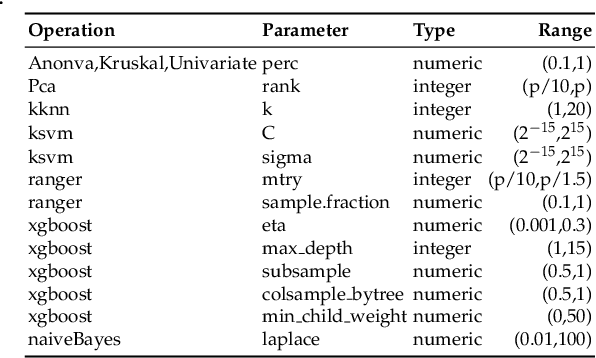
A novel machine learning optimization process coined Restrictive Federated Model Selection (RFMS) is proposed under the scenario, for example, when data from healthcare units can not leave the site it is situated on and it is forbidden to carry out training algorithms on remote data sites due to either technical or privacy and trust concerns. To carry out a clinical research under this scenario, an analyst could train a machine learning model only on local data site, but it is still possible to execute a statistical query at a certain cost in the form of sending a machine learning model to some of the remote data sites and get the performance measures as feedback, maybe due to prediction being usually much cheaper. Compared to federated learning, which is optimizing the model parameters directly by carrying out training across all data sites, RFMS trains model parameters only on one local data site but optimizes hyper-parameters across other data sites jointly since hyper-parameters play an important role in machine learning performance. The aim is to get a Pareto optimal model with respective to both local and remote unseen prediction losses, which could generalize well across data sites. In this work, we specifically consider high dimensional data with shifted distributions over data sites. As an initial investigation, Bayesian Optimization especially multi-objective Bayesian Optimization is used to guide an adaptive hyper-parameter optimization process to select models under the RFMS scenario. Empirical results show that solely using the local data site to tune hyper-parameters generalizes poorly across data sites, compared to methods that utilize the local and remote performances. Furthermore, in terms of dominated hypervolumes, multi-objective Bayesian Optimization algorithms show increased performance across multiple data sites among other candidates.
Face Detection using Deep Learning: An Improved Faster RCNN Approach
Jan 28, 2017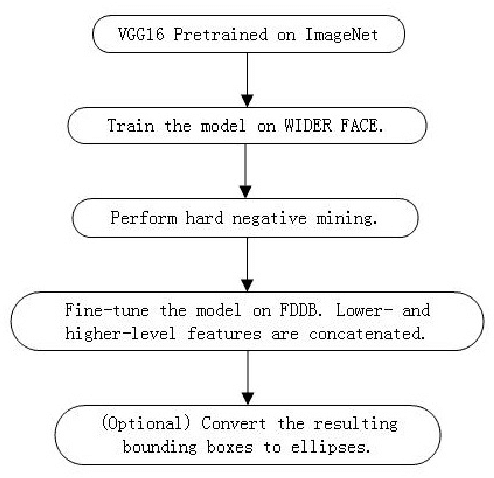

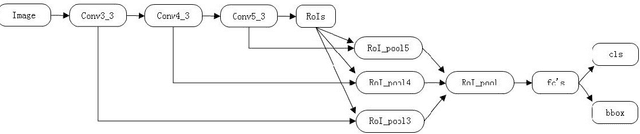

In this report, we present a new face detection scheme using deep learning and achieve the state-of-the-art detection performance on the well-known FDDB face detetion benchmark evaluation. In particular, we improve the state-of-the-art faster RCNN framework by combining a number of strategies, including feature concatenation, hard negative mining, multi-scale training, model pretraining, and proper calibration of key parameters. As a consequence, the proposed scheme obtained the state-of-the-art face detection performance, making it the best model in terms of ROC curves among all the published methods on the FDDB benchmark.