 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Out-Of-Domain Utterance Detection with Data Augmentation Based on Word Embeddings
Nov 24, 2019
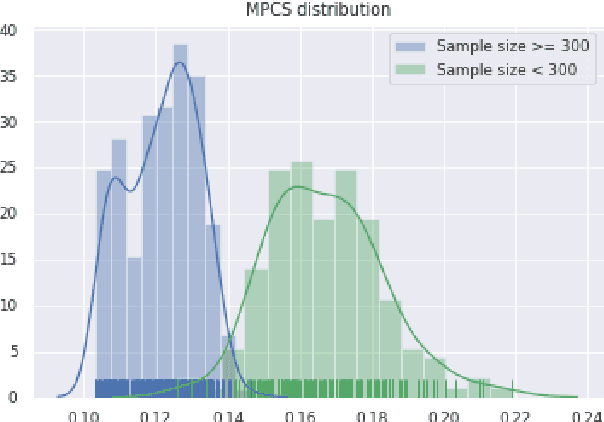

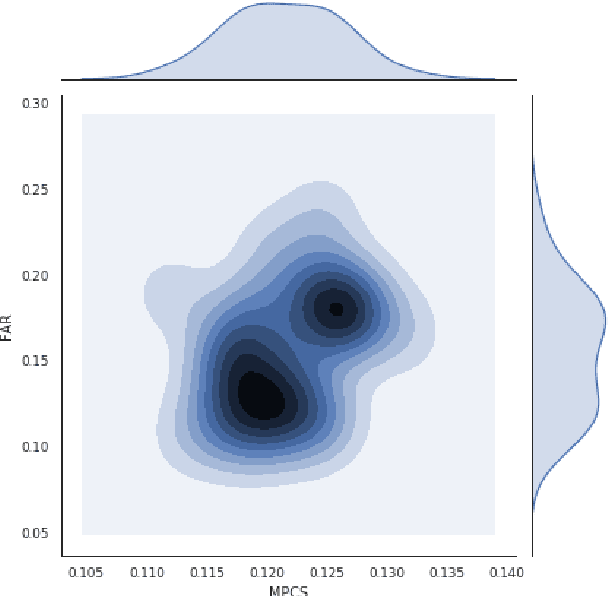
For most intelligent assistant systems, it is essential to have a mechanism that detects out-of-domain (OOD) utterances automatically to handle noisy input properly. One typical approach would be introducing a separate class that contains OOD utterance examples combined with in-domain text samples into the classifier. However, since OOD utterances are usually unseen to the training datasets, the detection performance largely depends on the quality of the attached OOD text data with restricted sizes of samples due to computing limits. In this paper, we study how augmented OOD data based on sampling impact OOD utterance detection with a small sample size. We hypothesize that OOD utterance samples chosen randomly can increase the coverage of unknown OOD utterance space and enhance detection accuracy if they are more dispersed. Experiments show that given the same dataset with the same OOD sample size, the OOD utterance detection performance improves when OOD samples are more spread-out.
ReinBo: Machine Learning pipeline search and configuration with Bayesian Optimization embedded Reinforcement Learning
Apr 10, 2019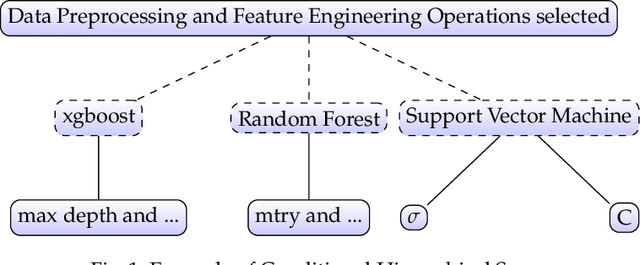

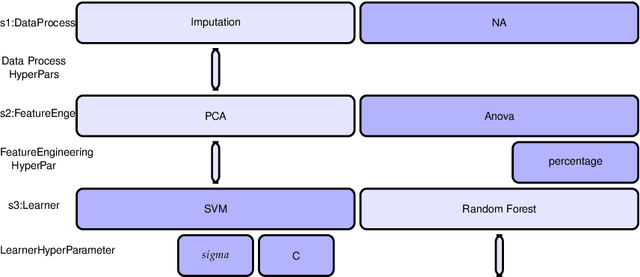
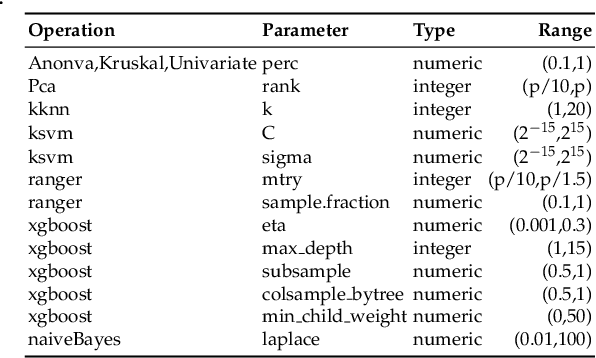
Machine learning pipeline potentially consists of several stages of operations like data preprocessing, feature engineering and machine learning model training. Each operation has a set of hyper-parameters, which can become irrelevant for the pipeline when the operation is not selected. This gives rise to a hierarchical conditional hyper-parameter space. To optimize this mixed continuous and discrete conditional hierarchical hyper-parameter space, we propose an efficient pipeline search and configuration algorithm which combines the power of Reinforcement Learning and Bayesian Optimization. Empirical results show that our method performs favorably compared to state of the art methods like Auto-sklearn , TPOT, Tree Parzen Window, and Random Search.