 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Functional Aggregate Queries with Additive Inequalities
Dec 22, 2018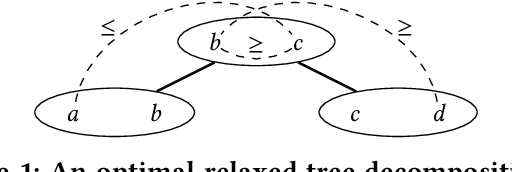
Motivated by fundamental applications in databases and relational machine learning, we formulate and study the problem of answering Functional Aggregate Queries (FAQ) in which some of the input factors are defined by a collection of Additive Inequalities between variables. We refer to these queries as FAQ-AI for short. To answer FAQ-AI in the Boolean semiring, we define "relaxed" tree decompositions and "relaxed" submodular and fractional hypertree width parameters. We show that an extension of the InsideOut algorithm using Chazelle's geometric data structure for solving the semigroup range search problem can answer Boolean FAQ-AI in time given by these new width parameters. This new algorithm achieves lower complexity than known solutions for FAQ-AI. It also recovers some known results in database query answering. Our second contribution is a relaxation of the set of polymatroids that gives rise to the counting version of the submodular width, denoted by "#subw". This new width is sandwiched between the submodular and the fractional hypertree widths. Any FAQ and FAQ-AI over one semiring can be answered in time proportional to #subw and respectively to the relaxed version of #subw. We present three applications of our FAQ-AI framework to relational machine learning: k-means clustering, training linear support vector machines, and training models using non-polynomial loss. These optimization problems can be solved over a database asymptotically faster than computing the join of the database relations.
Streaming dynamic and distributed inference of latent geometric structures
Sep 24, 2018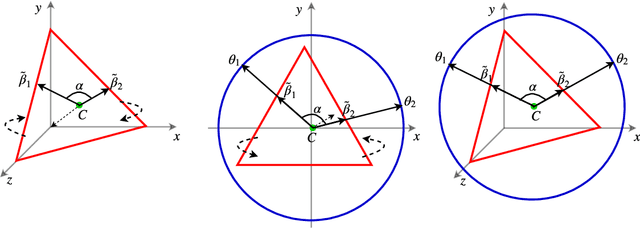
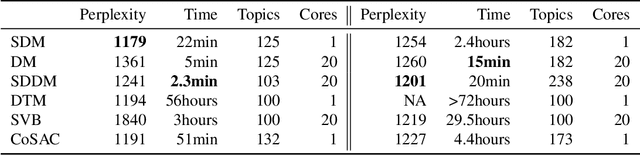
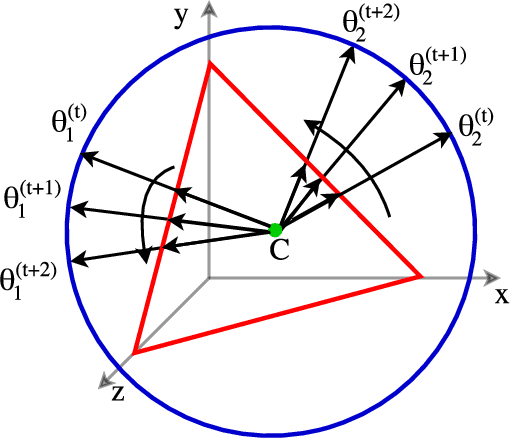
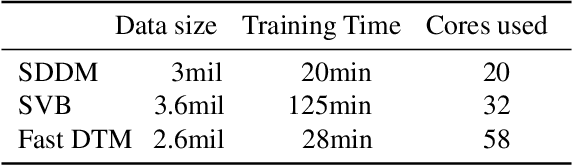
We develop new models and algorithms for learning the temporal dynamics of the topic polytopes and related geometric objects that arise in topic model based inference. Our model is nonparametric Bayesian and the corresponding inference algorithm is able to discover new topics as the time progresses. By exploiting the connection between the modeling of topic polytope evolution, Beta-Bernoulli process and the Hungarian matching algorithm, our method is shown to be several orders of magnitude faster than existing topic modeling approaches, as demonstrated by experiments working with several million documents in a dozen minutes.
Singularity structures and impacts on parameter estimation in finite mixtures of distributions
Sep 01, 2018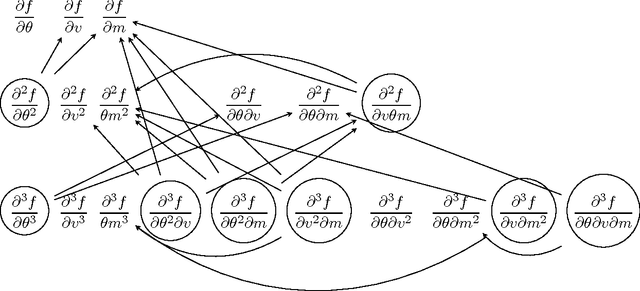
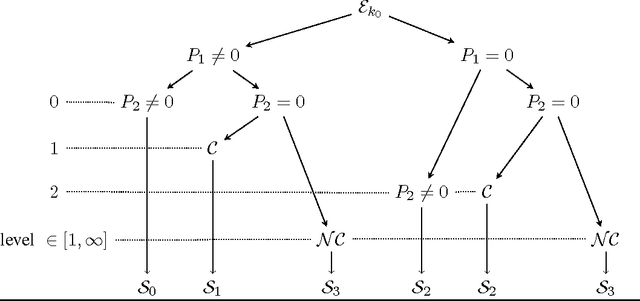
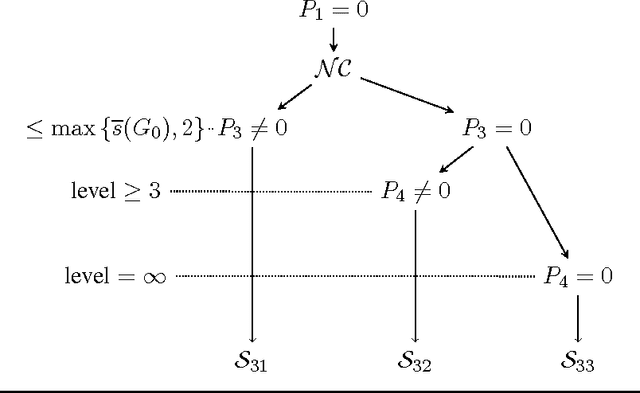
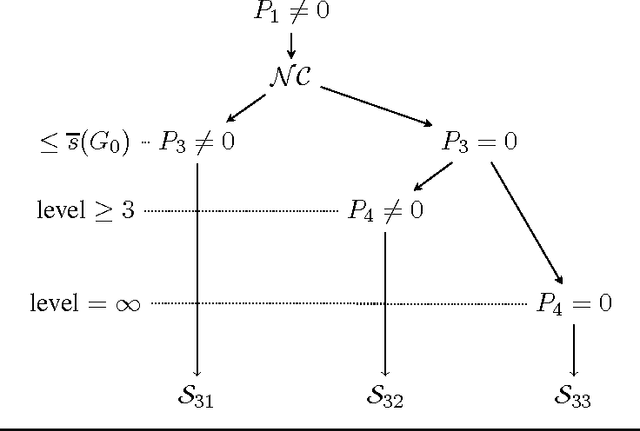
Singularities of a statistical model are the elements of the model's parameter space which make the corresponding Fisher information matrix degenerate. These are the points for which estimation techniques such as the maximum likelihood estimator and standard Bayesian procedures do not admit the root-$n$ parametric rate of convergence. We propose a general framework for the identification of singularity structures of the parameter space of finite mixtures, and study the impacts of the singularity structures on minimax lower bounds and rates of convergence for the maximum likelihood estimator over a compact parameter space. Our study makes explicit the deep links between model singularities, parameter estimation convergence rates and minimax lower bounds, and the algebraic geometry of the parameter space for mixtures of continuous distributions. The theory is applied to establish concrete convergence rates of parameter estimation for finite mixture of skew-normal distributions. This rich and increasingly popular mixture model is shown to exhibit a remarkably complex range of asymptotic behaviors which have not been hitherto reported in the literature.
Conic Scan-and-Cover algorithms for nonparametric topic modeling
Oct 09, 2017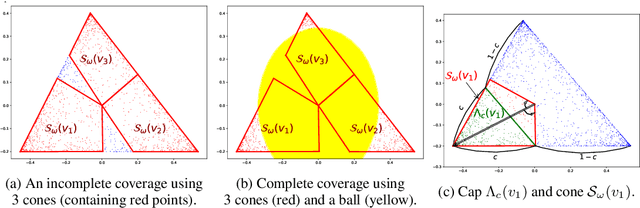
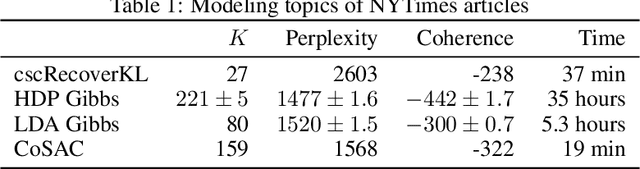
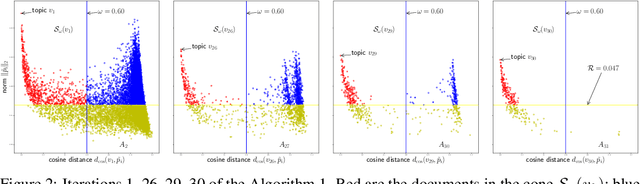
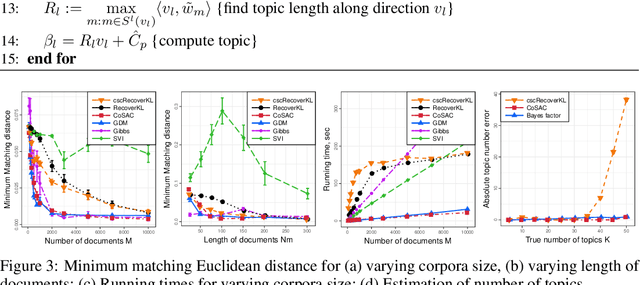
We propose new algorithms for topic modeling when the number of topics is unknown. Our approach relies on an analysis of the concentration of mass and angular geometry of the topic simplex, a convex polytope constructed by taking the convex hull of vertices representing the latent topics. Our algorithms are shown in practice to have accuracy comparable to a Gibbs sampler in terms of topic estimation, which requires the number of topics be given. Moreover, they are one of the fastest among several state of the art parametric techniques. Statistical consistency of our estimator is established under some conditions.
Multi-way Interacting Regression via Factorization Machines
Sep 27, 2017


We propose a Bayesian regression method that accounts for multi-way interactions of arbitrary orders among the predictor variables. Our model makes use of a factorization mechanism for representing the regression coefficients of interactions among the predictors, while the interaction selection is guided by a prior distribution on random hypergraphs, a construction which generalizes the Finite Feature Model. We present a posterior inference algorithm based on Gibbs sampling, and establish posterior consistency of our regression model. Our method is evaluated with extensive experiments on simulated data and demonstrated to be able to identify meaningful interactions in applications in genetics and retail demand forecasting.
Multilevel Clustering via Wasserstein Means
Jun 13, 2017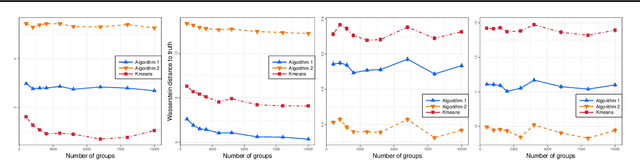
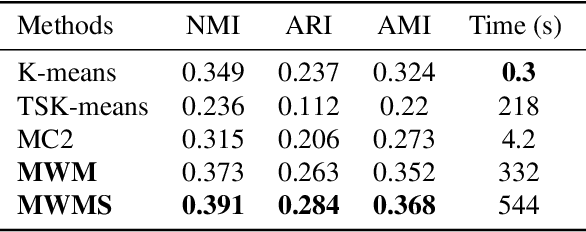
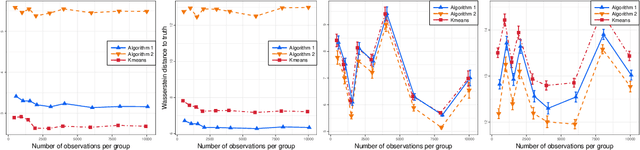
We propose a novel approach to the problem of multilevel clustering, which aims to simultaneously partition data in each group and discover grouping patterns among groups in a potentially large hierarchically structured corpus of data. Our method involves a joint optimization formulation over several spaces of discrete probability measures, which are endowed with Wasserstein distance metrics. We propose a number of variants of this problem, which admit fast optimization algorithms, by exploiting the connection to the problem of finding Wasserstein barycenters. Consistency properties are established for the estimates of both local and global clusters. Finally, experiment results with both synthetic and real data are presented to demonstrate the flexibility and scalability of the proposed approach.
Optimal change point detection in Gaussian processes
Apr 08, 2017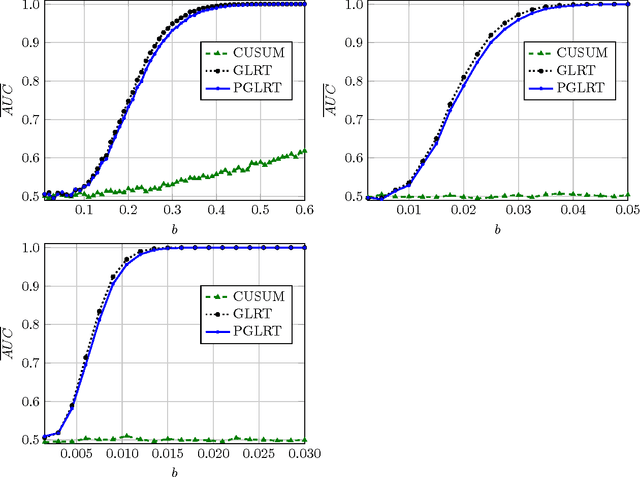
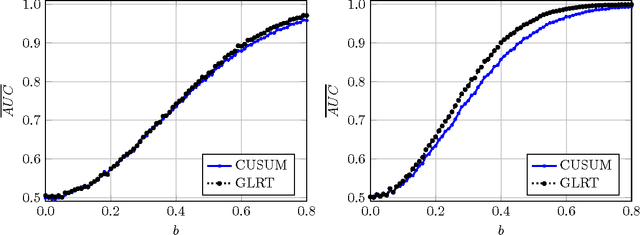
We study the problem of detecting a change in the mean of one-dimensional Gaussian process data. This problem is investigated in the setting of increasing domain (customarily employed in time series analysis) and in the setting of fixed domain (typically arising in spatial data analysis). We propose a detection method based on the generalized likelihood ratio test (GLRT), and show that our method achieves nearly asymptotically optimal rate in the minimax sense, in both settings. The salient feature of the proposed method is that it exploits in an efficient way the data dependence captured by the Gaussian process covariance structure. When the covariance is not known, we propose the plug-in GLRT method and derive conditions under which the method remains asymptotically near optimal. By contrast, the standard CUSUM method, which does not account for the covariance structure, is shown to be asymptotically optimal only in the increasing domain. Our algorithms and accompanying theory are applicable to a wide variety of covariance structures, including the Matern class, the powered exponential class, and others. The plug-in GLRT method is shown to perform well for maximum likelihood estimators with a dense covariance matrix.
Geometric Dirichlet Means algorithm for topic inference
Oct 27, 2016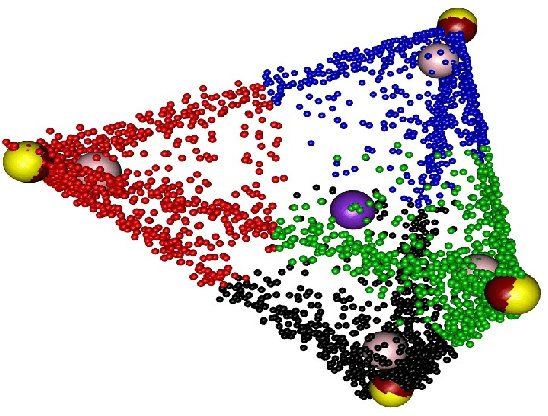

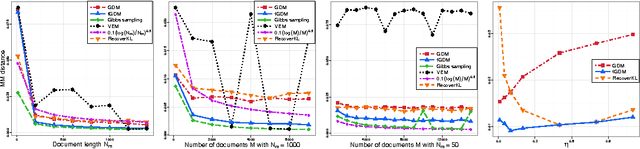
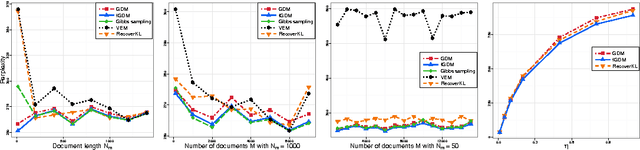
We propose a geometric algorithm for topic learning and inference that is built on the convex geometry of topics arising from the Latent Dirichlet Allocation (LDA) model and its nonparametric extensions. To this end we study the optimization of a geometric loss function, which is a surrogate to the LDA's likelihood. Our method involves a fast optimization based weighted clustering procedure augmented with geometric corrections, which overcomes the computational and statistical inefficiencies encountered by other techniques based on Gibbs sampling and variational inference, while achieving the accuracy comparable to that of a Gibbs sampler. The topic estimates produced by our method are shown to be statistically consistent under some conditions. The algorithm is evaluated with extensive experiments on simulated and real data.
On the consistency of inversion-free parameter estimation for Gaussian random fields
Jun 21, 2016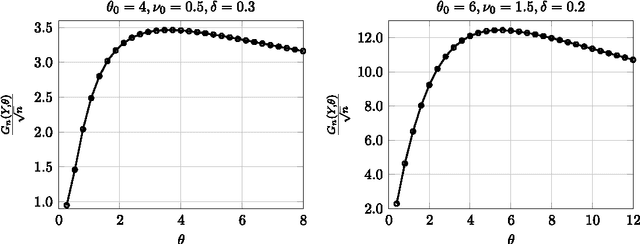

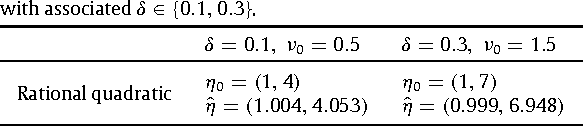
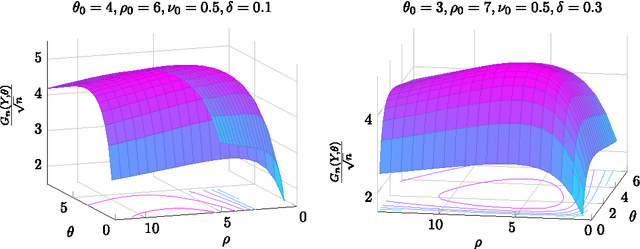
Gaussian random fields are a powerful tool for modeling environmental processes. For high dimensional samples, classical approaches for estimating the covariance parameters require highly challenging and massive computations, such as the evaluation of the Cholesky factorization or solving linear systems. Recently, Anitescu, Chen and Stein \cite{M.Anitescu} proposed a fast and scalable algorithm which does not need such burdensome computations. The main focus of this article is to study the asymptotic behavior of the algorithm of Anitescu et al. (ACS) for regular and irregular grids in the increasing domain setting. Consistency, minimax optimality and asymptotic normality of this algorithm are proved under mild differentiability conditions on the covariance function. Despite the fact that ACS's method entails a non-concave maximization, our results hold for any stationary point of the objective function. A numerical study is presented to evaluate the efficiency of this algorithm for large data sets.
* 41 pages, 2 Figures
Borrowing strengh in hierarchical Bayes: Posterior concentration of the Dirichlet base measure
Mar 24, 2016This paper studies posterior concentration behavior of the base probability measure of a Dirichlet measure, given observations associated with the sampled Dirichlet processes, as the number of observations tends to infinity. The base measure itself is endowed with another Dirichlet prior, a construction known as the hierarchical Dirichlet processes (Teh et al. [J. Amer. Statist. Assoc. 101 (2006) 1566-1581]). Convergence rates are established in transportation distances (i.e., Wasserstein metrics) under various conditions on the geometry of the support of the true base measure. As a consequence of the theory, we demonstrate the benefit of "borrowing strength" in the inference of multiple groups of data - a powerful insight often invoked to motivate hierarchical modeling. In certain settings, the gain in efficiency due to the latent hierarchy can be dramatic, improving from a standard nonparametric rate to a parametric rate of convergence. Tools developed include transportation distances for nonparametric Bayesian hierarchies of random measures, the existence of tests for Dirichlet measures, and geometric properties of the support of Dirichlet measures.
* Published at http://dx.doi.org/10.3150/15-BEJ703 in the Bernoulli (http://isi.cbs.nl/bernoulli/) by the International Statistical Institute/Bernoulli Society (http://isi.cbs.nl/BS/bshome.htm)