 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Head Residual-Gated DeepONet for Coherent Nonlinear Wave Dynamics
Apr 13, 2026Coherent nonlinear wave dynamics are often strongly shaped by a compact set of physically meaningful descriptors of the initial state. Traditional neural operators typically treat the input-output mapping as a largely black-box high-dimensional regression problem, without explicitly exploiting this structured physical context. Common feature-integration strategies usually rely on direct concatenation or FiLM-style affine modulation in hidden latent spaces. Here we introduce a different paradigm, loosely inspired by the complementary roles of state evolution and physically meaningful observables in quantum mechanics: the wave field is learned through a standard DeepONet state pathway, while compact physical descriptors follow a parallel conditioning pathway and act as residual modulation factors on the state prediction. Based on this idea, we develop a Multi-Head Residual-Gated DeepONet (MH-RG), which combines a pre-branch residual modulator, a branch residual gate, and a trunk residual gate with a low-rank multi-head mechanism to capture multiple complementary conditioned response patterns without prohibitive parameter growth. We evaluate the framework on representative benchmarks including highly nonlinear conservative wave dynamics and dissipative trapped dynamics and further perform detailed mechanistic analyses of the learned multi-head gating behavior. Compared with feature-augmented baselines, MH-RG DeepONet achieves consistently lower error while better preserving phase coherence and the fidelity of physically relevant dynamical quantities.
Certifiable Robustness for Naive Bayes Classifiers
Mar 08, 2023Data cleaning is crucial but often laborious in most machine learning (ML) applications. However, task-agnostic data cleaning is sometimes unnecessary if certain inconsistencies in the dirty data will not affect the prediction of ML models to the test points. A test point is certifiably robust for an ML classifier if the prediction remains the same regardless of which (among exponentially many) cleaned dataset it is trained on. In this paper, we study certifiable robustness for the Naive Bayes classifier (NBC) on dirty datasets with missing values. We present (i) a linear time algorithm in the number of entries in the dataset that decides whether a test point is certifiably robust for NBC, (ii) an algorithm that counts for each label, the number of cleaned datasets on which the NBC can be trained to predict that label, and (iii) an efficient optimal algorithm that poisons a clean dataset by inserting the minimum number of missing values such that a test point is not certifiably robust for NBC. We prove that (iv) poisoning a clean dataset such that multiple test points become certifiably non-robust is NP-hard for any dataset with at least three features. Our experiments demonstrate that our algorithms for the decision and data poisoning problems achieve up to $19.5\times$ and $3.06\times$ speed-up over the baseline algorithms across different real-world datasets.
Streaming dynamic and distributed inference of latent geometric structures
Sep 24, 2018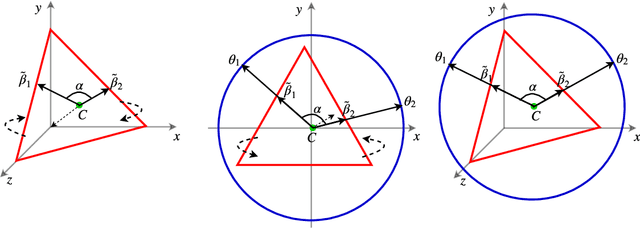
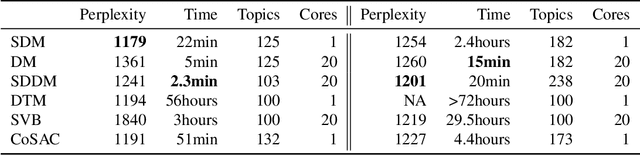
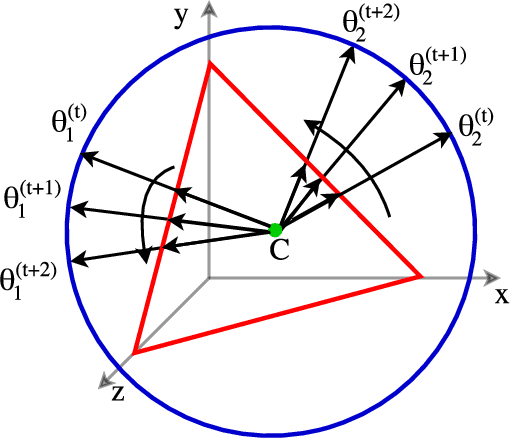
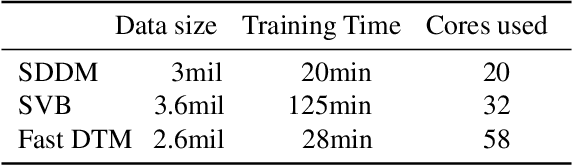
We develop new models and algorithms for learning the temporal dynamics of the topic polytopes and related geometric objects that arise in topic model based inference. Our model is nonparametric Bayesian and the corresponding inference algorithm is able to discover new topics as the time progresses. By exploiting the connection between the modeling of topic polytope evolution, Beta-Bernoulli process and the Hungarian matching algorithm, our method is shown to be several orders of magnitude faster than existing topic modeling approaches, as demonstrated by experiments working with several million documents in a dozen minutes.