 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinor DPO reject penalty to increase training robustness
Aug 22, 2024



Learning from human preference is a paradigm used in large-scale language model (LLM) fine-tuning step to better align pretrained LLM to human preference for downstream task. In the past it uses reinforcement learning from human feedback (RLHF) algorithm to optimize the LLM policy to align with these preferences and not to draft too far from the original model. Recently, Direct Preference Optimization (DPO) has been proposed to solve the alignment problem with a simplified RL-free method. Using preference pairs of chosen and reject data, DPO models the relative log probability as implicit reward function and optimize LLM policy using a simple binary cross entropy objective directly. DPO is quite straight forward and easy to be understood. It perform efficiently and well in most cases. In this article, we analyze the working mechanism of $\beta$ in DPO, disclose its syntax difference between RL algorithm and DPO, and understand the potential shortage brought by the DPO simplification. With these insights, we propose MinorDPO, which is better aligned to the original RL algorithm, and increase the stability of preference optimization process.
Minor SFT loss for LLM fine-tune to increase performance and reduce model deviation
Aug 20, 2024

Instruct LLM provide a paradigm used in large scale language model to align LLM to human preference. The paradigm contains supervised fine tuning and reinforce learning from human feedback. This paradigm is also used in downstream scenarios to adapt LLM to specific corpora and applications. Comparing to SFT, there are many efforts focused on RLHF and several algorithms being proposed, such as PPO, DPO, IPO, KTO, MinorDPO and etc. Meanwhile most efforts for SFT are focused on how to collect, filter and mix high quality data. In this article with insight from DPO and MinorDPO, we propose a training metric for SFT to measure the discrepancy between the optimized model and the original model, and a loss function MinorSFT that can increase the training effectiveness, and reduce the discrepancy between the optimized LLM and original LLM.
Are Pre-trained Language Models Useful for Model Ensemble in Chinese Grammatical Error Correction?
May 24, 2023



Model ensemble has been in widespread use for Grammatical Error Correction (GEC), boosting model performance. We hypothesize that model ensemble based on the perplexity (PPL) computed by pre-trained language models (PLMs) should benefit the GEC system. To this end, we explore several ensemble strategies based on strong PLMs with four sophisticated single models. However, the performance does not improve but even gets worse after the PLM-based ensemble. This surprising result sets us doing a detailed analysis on the data and coming up with some insights on GEC. The human references of correct sentences is far from sufficient in the test data, and the gap between a correct sentence and an idiomatic one is worth our attention. Moreover, the PLM-based ensemble strategies provide an effective way to extend and improve GEC benchmark data. Our source code is available at https://github.com/JamyDon/PLM-based-CGEC-Model-Ensemble.
An Error-Guided Correction Model for Chinese Spelling Error Correction
Jan 16, 2023Although existing neural network approaches have achieved great success on Chinese spelling correction, there is still room to improve. The model is required to avoid over-correction and to distinguish a correct token from its phonological and visually similar ones. In this paper, we propose an error-guided correction model (EGCM) to improve Chinese spelling correction. By borrowing the powerful ability of BERT, we propose a novel zero-shot error detection method to do a preliminary detection, which guides our model to attend more on the probably wrong tokens in encoding and to avoid modifying the correct tokens in generating. Furthermore, we introduce a new loss function to integrate the error confusion set, which enables our model to distinguish easily misused tokens. Moreover, our model supports highly parallel decoding to meet real application requirements. Experiments are conducted on widely used benchmarks. Our model achieves superior performance against state-of-the-art approaches by a remarkable margin, on both the correction quality and computation speed.
From Spelling to Grammar: A New Framework for Chinese Grammatical Error Correction
Nov 03, 2022



Chinese Grammatical Error Correction (CGEC) aims to generate a correct sentence from an erroneous sequence, where different kinds of errors are mixed. This paper divides the CGEC task into two steps, namely spelling error correction and grammatical error correction. Specifically, we propose a novel zero-shot approach for spelling error correction, which is simple but effective, obtaining a high precision to avoid error accumulation of the pipeline structure. To handle grammatical error correction, we design part-of-speech (POS) features and semantic class features to enhance the neural network model, and propose an auxiliary task to predict the POS sequence of the target sentence. Our proposed framework achieves a 42.11 F0.5 score on CGEC dataset without using any synthetic data or data augmentation methods, which outperforms the previous state-of-the-art by a wide margin of 1.30 points. Moreover, our model produces meaningful POS representations that capture different POS words and convey reasonable POS transition rules.
A Question Type Driven and Copy Loss Enhanced Frameworkfor Answer-Agnostic Neural Question Generation
May 24, 2020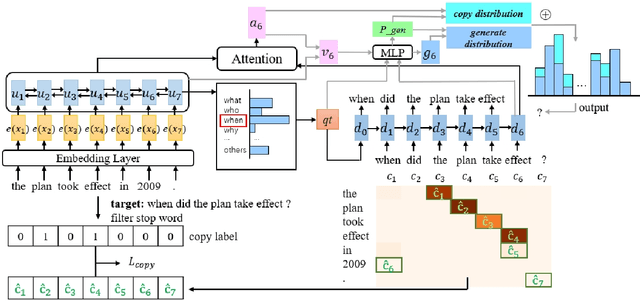

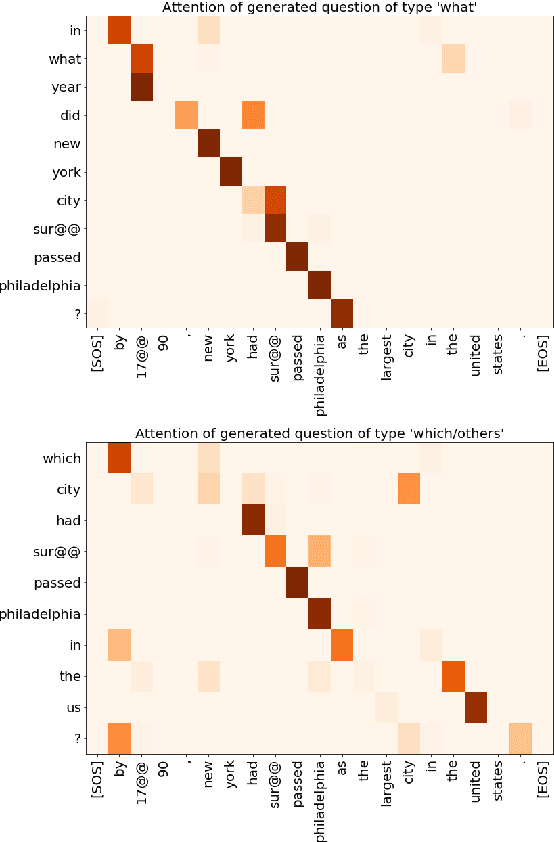

The answer-agnostic question generation is a significant and challenging task, which aims to automatically generate questions for a given sentence but without an answer. In this paper, we propose two new strategies to deal with this task: question type prediction and copy loss mechanism. The question type module is to predict the types of questions that should be asked, which allows our model to generate multiple types of questions for the same source sentence. The new copy loss enhances the original copy mechanism to make sure that every important word in the source sentence has been copied when generating questions. Our integrated model outperforms the state-of-the-art approach in answer-agnostic question generation, achieving a BLEU-4 score of 13.9 on SQuAD. Human evaluation further validates the high quality of our generated questions. We will make our code public available for further research.
A Simple Dual-decoder Model for Generating Response with Sentiment
May 16, 2019

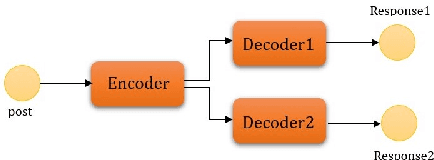
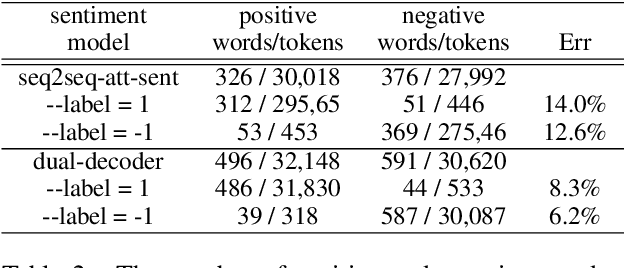
How to generate human like response is one of the most challenging tasks for artificial intelligence. In a real application, after reading the same post different people might write responses with positive or negative sentiment according to their own experiences and attitudes. To simulate this procedure, we propose a simple but effective dual-decoder model to generate response with a particular sentiment, by connecting two sentiment decoders to one encoder. To support this model training, we construct a new conversation dataset with the form of (post, resp1, resp2) where two responses contain opposite sentiment. Experiment results show that our dual-decoder model can generate diverse responses with target sentiment, which obtains significant performance gain in sentiment accuracy and word diversity over the traditional single-decoder model. We will make our data and code publicly available for further study.