 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCDA: Thread-Constrained Discourse-Aware Modeling for Conversational Sentiment Quadruple Analysis
May 03, 2026Conversational Aspect-based Sentiment Quadruple Analysis (DiaASQ) needs to capture the complex interrelationships in multiple rounds of dialogues. Existing methods usually employ simple Graph Convolutional Networks (GCN), which introduce structural noise and fail to consider the temporal sequence of the dialogues, or use standard RoPE, which implicitly captures relative distances in a flat sequence but cannot clearly separate the token-level syntactic order from the utterance-level progression, and may suffer from the Distance Dilution problem. To address these issues, we propose a new framework that combines Thread-Constrained Directed Acyclic Graph (TC-DAG) and Discourse-Aware Rotary Position Embedding (D-RoPE). Specifically, TC-DAG filters out cross-thread noise based on thread constraints, maintains global connectivity through root anchoring, and incorporates the temporal sequence of the dialogues. D-RoPE aligns multi-layer semantics using dual-stream projection and multi-scale frequency signals, captures thread dependencies using tree-like distances, and alleviates the token-level Distance Dilution problem by incorporating utterance-level progressions. Experimental results on two benchmark datasets demonstrate that our framework achieves state-of-the-art performance.
A Unified Framework for Emotion Recognition and Sentiment Analysis via Expert-Guided Multimodal Fusion with Large Language Models
Jan 12, 2026Multimodal emotion understanding requires effective integration of text, audio, and visual modalities for both discrete emotion recognition and continuous sentiment analysis. We present EGMF, a unified framework combining expert-guided multimodal fusion with large language models. Our approach features three specialized expert networks--a fine-grained local expert for subtle emotional nuances, a semantic correlation expert for cross-modal relationships, and a global context expert for long-range dependencies--adaptively integrated through hierarchical dynamic gating for context-aware feature selection. Enhanced multimodal representations are integrated with LLMs via pseudo token injection and prompt-based conditioning, enabling a single generative framework to handle both classification and regression through natural language generation. We employ LoRA fine-tuning for computational efficiency. Experiments on bilingual benchmarks (MELD, CHERMA, MOSEI, SIMS-V2) demonstrate consistent improvements over state-of-the-art methods, with superior cross-lingual robustness revealing universal patterns in multimodal emotional expressions across English and Chinese. We will release the source code publicly.
Do LLMs Feel? Teaching Emotion Recognition with Prompts, Retrieval, and Curriculum Learning
Nov 12, 2025Emotion Recognition in Conversation (ERC) is a crucial task for understanding human emotions and enabling natural human-computer interaction. Although Large Language Models (LLMs) have recently shown great potential in this field, their ability to capture the intrinsic connections between explicit and implicit emotions remains limited. We propose a novel ERC training framework, PRC-Emo, which integrates Prompt engineering, demonstration Retrieval, and Curriculum learning, with the goal of exploring whether LLMs can effectively perceive emotions in conversational contexts. Specifically, we design emotion-sensitive prompt templates based on both explicit and implicit emotional cues to better guide the model in understanding the speaker's psychological states. We construct the first dedicated demonstration retrieval repository for ERC, which includes training samples from widely used datasets, as well as high-quality dialogue examples generated by LLMs and manually verified. Moreover, we introduce a curriculum learning strategy into the LoRA fine-tuning process, incorporating weighted emotional shifts between same-speaker and different-speaker utterances to assign difficulty levels to dialogue samples, which are then organized in an easy-to-hard training sequence. Experimental results on two benchmark datasets -- IEMOCAP and MELD -- show that our method achieves new state-of-the-art (SOTA) performance, demonstrating the effectiveness and generalizability of our approach in improving LLM-based emotional understanding.
CheX-DS: Improving Chest X-ray Image Classification with Ensemble Learning Based on DenseNet and Swin Transformer
May 16, 2025



The automatic diagnosis of chest diseases is a popular and challenging task. Most current methods are based on convolutional neural networks (CNNs), which focus on local features while neglecting global features. Recently, self-attention mechanisms have been introduced into the field of computer vision, demonstrating superior performance. Therefore, this paper proposes an effective model, CheX-DS, for classifying long-tail multi-label data in the medical field of chest X-rays. The model is based on the excellent CNN model DenseNet for medical imaging and the newly popular Swin Transformer model, utilizing ensemble deep learning techniques to combine the two models and leverage the advantages of both CNNs and Transformers. The loss function of CheX-DS combines weighted binary cross-entropy loss with asymmetric loss, effectively addressing the issue of data imbalance. The NIH ChestX-ray14 dataset is selected to evaluate the model's effectiveness. The model outperforms previous studies with an excellent average AUC score of 83.76\%, demonstrating its superior performance.
* BIBM
Dual Encoder: Exploiting the Potential of Syntactic and Semantic for Aspect Sentiment Triplet Extraction
Feb 23, 2024



Aspect Sentiment Triple Extraction (ASTE) is an emerging task in fine-grained sentiment analysis. Recent studies have employed Graph Neural Networks (GNN) to model the syntax-semantic relationships inherent in triplet elements. However, they have yet to fully tap into the vast potential of syntactic and semantic information within the ASTE task. In this work, we propose a \emph{Dual Encoder: Exploiting the potential of Syntactic and Semantic} model (D2E2S), which maximizes the syntactic and semantic relationships among words. Specifically, our model utilizes a dual-channel encoder with a BERT channel to capture semantic information, and an enhanced LSTM channel for comprehensive syntactic information capture. Subsequently, we introduce the heterogeneous feature interaction module to capture intricate interactions between dependency syntax and attention semantics, and to dynamically select vital nodes. We leverage the synergy of these modules to harness the significant potential of syntactic and semantic information in ASTE tasks. Testing on public benchmarks, our D2E2S model surpasses the current state-of-the-art(SOTA), demonstrating its effectiveness.
Extensible Multi-Granularity Fusion Network for Aspect-based Sentiment Analysis
Feb 13, 2024



Aspect-based Sentiment Analysis (ABSA) evaluates sentiment expressions within a text to comprehend sentiment information. Previous studies integrated external knowledge, such as knowledge graphs, to enhance the semantic features in ABSA models. Recent research has examined the use of Graph Neural Networks (GNNs) on dependency and constituent trees for syntactic analysis. With the ongoing development of ABSA, more innovative linguistic and structural features are being incorporated (e.g. latent graph), but this also introduces complexity and confusion. As of now, a scalable framework for integrating diverse linguistic and structural features into ABSA does not exist. This paper presents the Extensible Multi-Granularity Fusion (EMGF) network, which integrates information from dependency and constituent syntactic, attention semantic , and external knowledge graphs. EMGF, equipped with multi-anchor triplet learning and orthogonal projection, efficiently harnesses the combined potential of each granularity feature and their synergistic interactions, resulting in a cumulative effect without additional computational expenses. Experimental findings on SemEval 2014 and Twitter datasets confirm EMGF's superiority over existing ABSA methods.
Knowledge Graph Embedding with Entity Neighbors and Deep Memory Network
Aug 11, 2018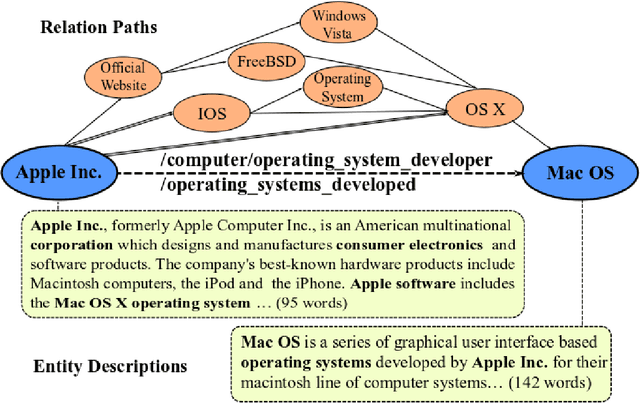
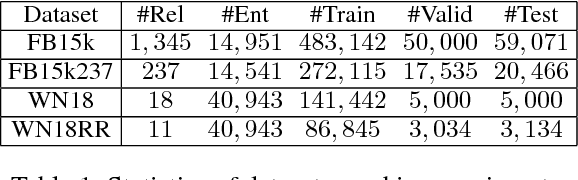
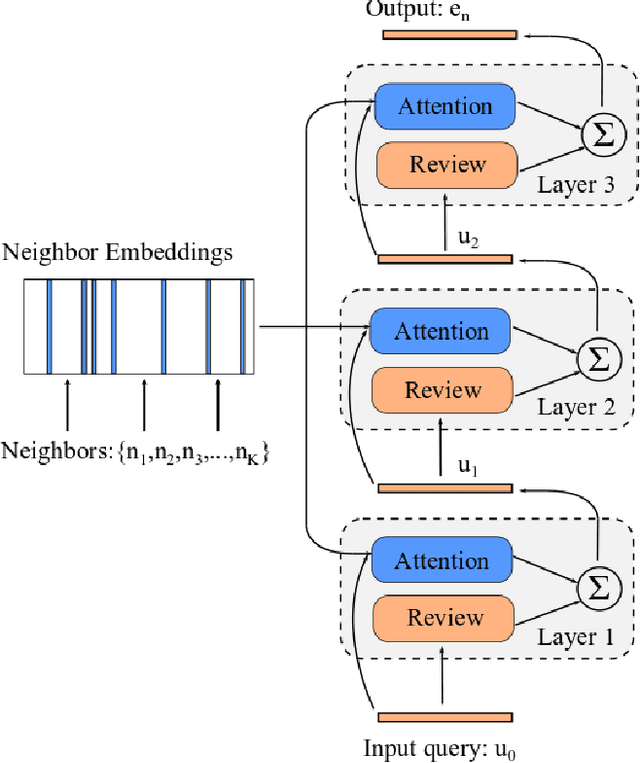
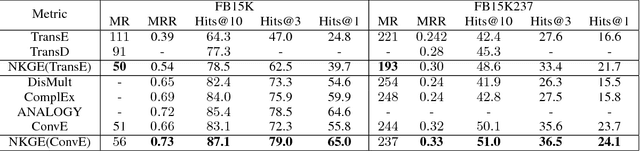
Knowledge Graph Embedding (KGE) aims to represent entities and relations of knowledge graph in a low-dimensional continuous vector space. Recent works focus on incorporating structural knowledge with additional information, such as entity descriptions, relation paths and so on. However, common used additional information usually contains plenty of noise, which makes it hard to learn valuable representation. In this paper, we propose a new kind of additional information, called entity neighbors, which contain both semantic and topological features about given entity. We then develop a deep memory network model to encode information from neighbors. Employing a gating mechanism, representations of structure and neighbors are integrated into a joint representation. The experimental results show that our model outperforms existing KGE methods utilizing entity descriptions and achieves state-of-the-art metrics on 4 datasets.