 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormation Maneuver Control Based on the Augmented Laplacian Method
May 09, 2025This paper proposes a novel formation maneuver control method for both 2-D and 3-D space, which enables the formation to translate, scale, and rotate with arbitrary orientation. The core innovation is the novel design of weights in the proposed augmented Laplacian matrix. Instead of using scalars, we represent weights as matrices, which are designed based on a specified rotation axis and allow the formation to perform rotation in 3-D space. To further improve the flexibility and scalability of the formation, the rotational axis adjustment approach and dynamic agent reconfiguration method are developed, allowing formations to rotate around arbitrary axes in 3-D space and new agents to join the formation. Theoretical analysis is provided to show that the proposed approach preserves the original configuration of the formation. The proposed method maintains the advantages of the complex Laplacian-based method, including reduced neighbor requirements and no reliance on generic or convex nominal configurations, while achieving arbitrary orientation rotations via a more simplified implementation. Simulations in both 2-D and 3-D space validate the effectiveness of the proposed method.
Rethinking the Spatial Route Prior in Vision-and-Language Navigation
Oct 12, 2021
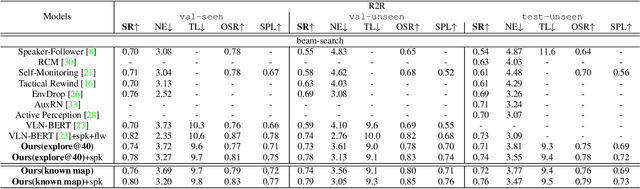
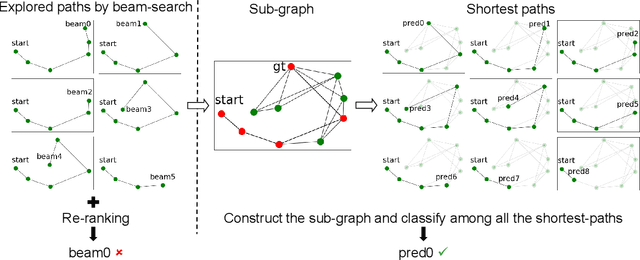
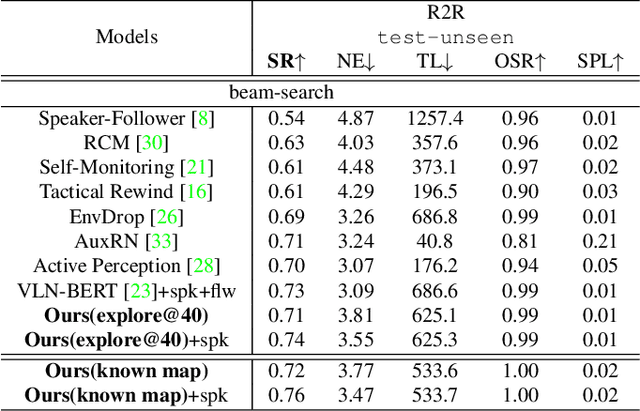
Vision-and-language navigation (VLN) is a trending topic which aims to navigate an intelligent agent to an expected position through natural language instructions. This work addresses the task of VLN from a previously-ignored aspect, namely the spatial route prior of the navigation scenes. A critically enabling innovation of this work is explicitly considering the spatial route prior under several different VLN settings. In a most information-rich case of knowing environment maps and admitting shortest-path prior, we observe that given an origin-destination node pair, the internal route can be uniquely determined. Thus, VLN can be effectively formulated as an ordinary classification problem over all possible destination nodes in the scenes. Furthermore, we relax it to other more general VLN settings, proposing a sequential-decision variant (by abandoning the shortest-path route prior) and an explore-and-exploit scheme (for addressing the case of not knowing the environment maps) that curates a compact and informative sub-graph to exploit. As reported by [34], the performance of VLN methods has been stuck at a plateau in past two years. Even with increased model complexity, the state-of-the-art success rate on R2R validation-unseen set has stayed around 62% for single-run and 73% for beam-search with model-ensemble. We have conducted comprehensive evaluations on both R2R and R4R, and surprisingly found that utilizing the spatial route priors may be the key of breaking above-mentioned performance ceiling. For example, on R2R validation-unseen set, when the number of discrete nodes explored is about 40, our single-model success rate reaches 73%, and increases to 78% if a Speaker model is ensembled, which significantly outstrips previous state-of-the-art VLN-BERT with 3 models ensembled.