 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEARL: Towards a Unified Analysis-Guided Reinforcement Learning Framework for Egocentric Interaction Reasoning and Pixel Grounding
May 14, 2026Understanding human--environment interactions from egocentric vision is essential for assistive robotics and embodied intelligent agents, yet existing multimodal large language models (MLLMs) still struggle with accurate interaction reasoning and fine-grained pixel grounding. To this end, this paper introduces EARL, an Egocentric Analysis-guided Reinforcement Learning framework that explicitly transfers coarse interaction semantics to query-oriented answering and grounding. Specifically, EARL adopts a two-stage parsing framework including coarse-grained interpretation and fine-grained response. The first stage holistically interprets egocentric interactions and generates a structured textual description. The second stage produces the textual answer and pixel-level mask in response to the user query. To bridge the two stages, we extract a global interaction descriptor as a semantic prior, which is integrated via a novel Analysis-guided Feature Synthesizer (AFS) for query-oriented reasoning. To optimize heterogeneous outputs, including textual answers, bounding boxes, and grounding masks, we design a multi-faceted reward function and train the response stage with GRPO. Experiments on Ego-IRGBench show that EARL achieves 65.48% cIoU for pixel grounding, outperforming previous RL-based methods by 8.37%, while OOD grounding results on EgoHOS indicate strong transferability to unseen egocentric grounding scenarios.
Towards Omnidirectional Reasoning with 360-R1: A Dataset, Benchmark, and GRPO-based Method
May 20, 2025Omnidirectional images (ODIs), with their 360{\deg} field of view, provide unparalleled spatial awareness for immersive applications like augmented reality and embodied AI. However, the capability of existing multi-modal large language models (MLLMs) to comprehend and reason about such panoramic scenes remains underexplored. This paper addresses this gap by introducing OmniVQA, the first dataset and conducting the first benchmark for omnidirectional visual question answering. Our evaluation of state-of-the-art MLLMs reveals significant limitations in handling omnidirectional visual question answering, highlighting persistent challenges in object localization, feature extraction, and hallucination suppression within panoramic contexts. These results underscore the disconnect between current MLLM capabilities and the demands of omnidirectional visual understanding, which calls for dedicated architectural or training innovations tailored to 360{\deg} imagery. Building on the OmniVQA dataset and benchmark, we further introduce a rule-based reinforcement learning method, 360-R1, based on Qwen2.5-VL-Instruct. Concretely, we modify the group relative policy optimization (GRPO) by proposing three novel reward functions: (1) reasoning process similarity reward, (2) answer semantic accuracy reward, and (3) structured format compliance reward. Extensive experiments on our OmniVQA demonstrate the superiority of our proposed method in omnidirectional space (+6% improvement).
Audio-FLAN: A Preliminary Release
Feb 23, 2025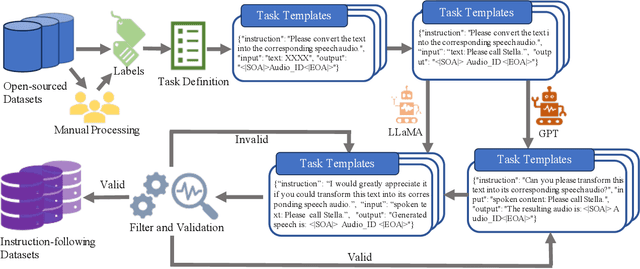

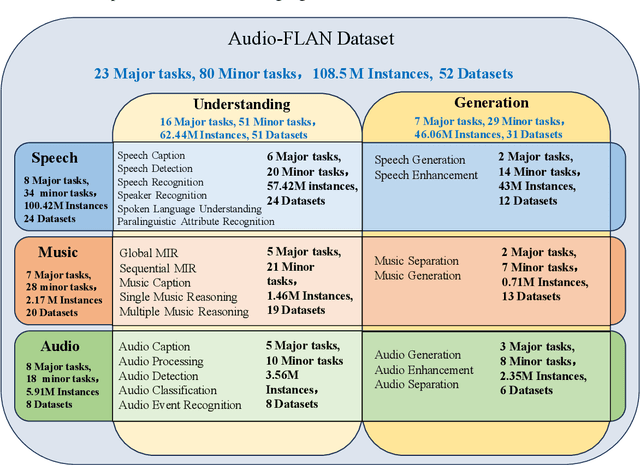

Recent advancements in audio tokenization have significantly enhanced the integration of audio capabilities into large language models (LLMs). However, audio understanding and generation are often treated as distinct tasks, hindering the development of truly unified audio-language models. While instruction tuning has demonstrated remarkable success in improving generalization and zero-shot learning across text and vision, its application to audio remains largely unexplored. A major obstacle is the lack of comprehensive datasets that unify audio understanding and generation. To address this, we introduce Audio-FLAN, a large-scale instruction-tuning dataset covering 80 diverse tasks across speech, music, and sound domains, with over 100 million instances. Audio-FLAN lays the foundation for unified audio-language models that can seamlessly handle both understanding (e.g., transcription, comprehension) and generation (e.g., speech, music, sound) tasks across a wide range of audio domains in a zero-shot manner. The Audio-FLAN dataset is available on HuggingFace and GitHub and will be continuously updated.