 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Variance: Prompt-Efficient RLVR via Rare-Event Amplification and Bidirectional Pairing
Feb 03, 2026Reinforcement learning with verifiable rewards (RLVR) is effective for training large language models on deterministic outcome reasoning tasks. Prior work shows RLVR works with few prompts, but prompt selection is often based only on training-accuracy variance, leading to unstable optimization directions and weaker transfer. We revisit prompt selection from a mechanism-level view and argue that an effective minibatch should provide both (i) a reliable positive anchor and (ii) explicit negative learning signals from rare failures. Based on this principle, we propose \emph{positive--negative pairing}: at each update, we sample a hard-but-solvable $q^{+}$ and an easy-but-brittle prompt $q^{-}$(high success rate but not perfect), characterized by low and high empirical success rates under multiple rollouts. We further introduce Weighted GRPO, which reweights binary outcomes at the pair level and uses group-normalized advantages to amplify rare successes on $q^{+}$ into sharp positive guidance while turning rare failures on $q^{-}$ into strong negative penalties. This bidirectional signal provides informative learning feedback for both successes and failures, improving sample efficiency without suppressing exploration. On Qwen2.5-Math-7B, a single paired minibatch per update consistently outperforms a GRPO baseline that selects two prompts via commonly used variance-based selection heuristics: AIME~2025 Pass@8 improves from 16.8 to 22.2, and AMC23 Pass@64 from 94.0 to 97.0, while remaining competitive with large-scale RLVR trained from a pool of 1209 training prompts. Similar gains are observed on Qwen2.5-Math-7B-Instruct.
Sequence-to-Action: Grammatical Error Correction with Action Guided Sequence Generation
May 22, 2022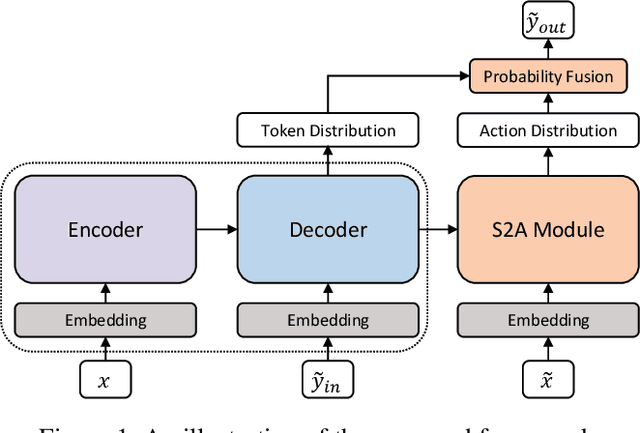

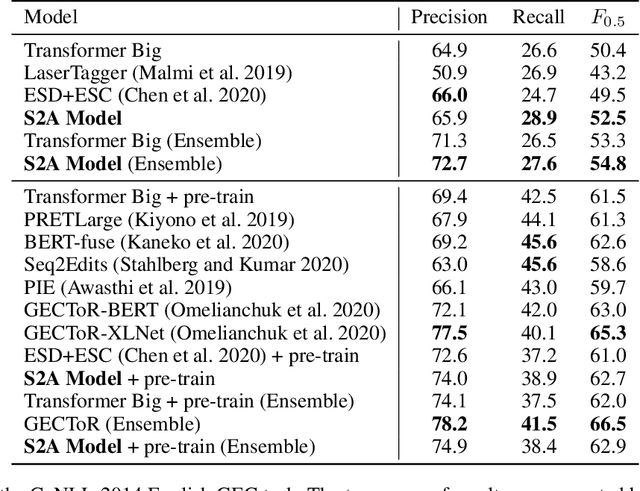

The task of Grammatical Error Correction (GEC) has received remarkable attention with wide applications in Natural Language Processing (NLP) in recent years. While one of the key principles of GEC is to keep the correct parts unchanged and avoid over-correction, previous sequence-to-sequence (seq2seq) models generate results from scratch, which are not guaranteed to follow the original sentence structure and may suffer from the over-correction problem. In the meantime, the recently proposed sequence tagging models can overcome the over-correction problem by only generating edit operations, but are conditioned on human designed language-specific tagging labels. In this paper, we combine the pros and alleviate the cons of both models by proposing a novel Sequence-to-Action~(S2A) module. The S2A module jointly takes the source and target sentences as input, and is able to automatically generate a token-level action sequence before predicting each token, where each action is generated from three choices named SKIP, COPY and GENerate. Then the actions are fused with the basic seq2seq framework to provide final predictions. We conduct experiments on the benchmark datasets of both English and Chinese GEC tasks. Our model consistently outperforms the seq2seq baselines, while being able to significantly alleviate the over-correction problem as well as holding better generality and diversity in the generation results compared to the sequence tagging models.