 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinate Descent for MCP/SCAD Penalized Least Squares Converges Linearly
Sep 18, 2021
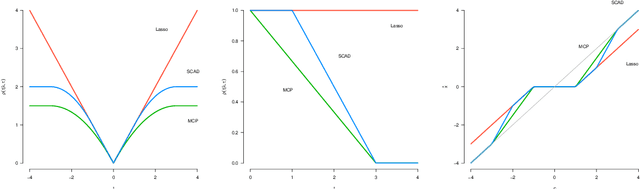
Recovering sparse signals from observed data is an important topic in signal/imaging processing, statistics and machine learning. Nonconvex penalized least squares have been attracted a lot of attentions since they enjoy nice statistical properties. Computationally, coordinate descent (CD) is a workhorse for minimizing the nonconvex penalized least squares criterion due to its simplicity and scalability. In this work, we prove the linear convergence rate to CD for solving MCP/SCAD penalized least squares problems.
Deep Neural Networks with ReLU-Sine-Exponential Activations Break Curse of Dimensionality on Hölder Class
Mar 07, 2021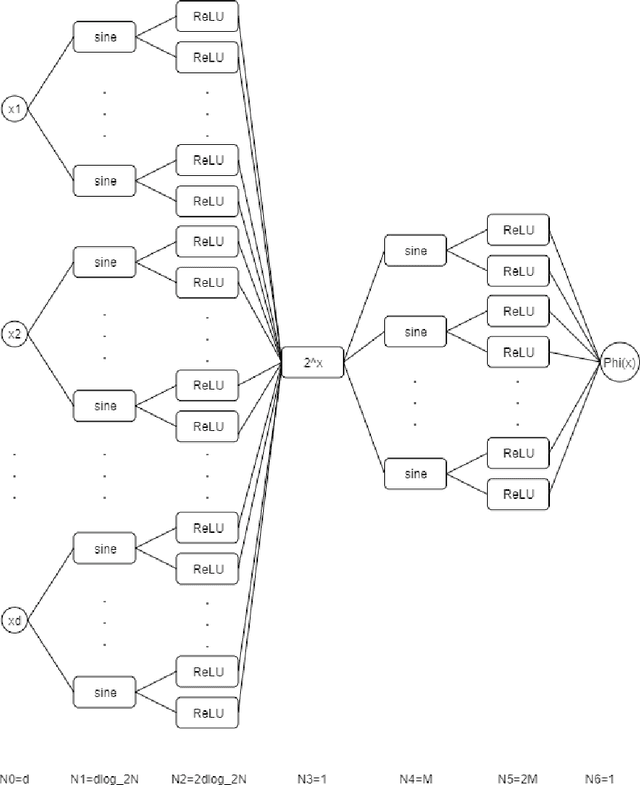

In this paper, we construct neural networks with ReLU, sine and $2^x$ as activation functions. For general continuous $f$ defined on $[0,1]^d$ with continuity modulus $\omega_f(\cdot)$, we construct ReLU-sine-$2^x$ networks that enjoy an approximation rate $\mathcal{O}(\omega_f(\sqrt{d})\cdot2^{-M}+\omega_{f}\left(\frac{\sqrt{d}}{N}\right))$, where $M,N\in \mathbb{N}^{+}$ denote the hyperparameters related to widths of the networks. As a consequence, we can construct ReLU-sine-$2^x$ network with the depth $5$ and width $\max\left\{\left\lceil2d^{3/2}\left(\frac{3\mu}{\epsilon}\right)^{1/{\alpha}}\right\rceil,2\left\lceil\log_2\frac{3\mu d^{\alpha/2}}{2\epsilon}\right\rceil+2\right\}$ that approximates $f\in \mathcal{H}_{\mu}^{\alpha}([0,1]^d)$ within a given tolerance $\epsilon >0$ measured in $L^p$ norm $p\in[1,\infty)$, where $\mathcal{H}_{\mu}^{\alpha}([0,1]^d)$ denotes the H\"older continuous function class defined on $[0,1]^d$ with order $\alpha \in (0,1]$ and constant $\mu > 0$. Therefore, the ReLU-sine-$2^x$ networks overcome the curse of dimensionality on $\mathcal{H}_{\mu}^{\alpha}([0,1]^d)$. In addition to its supper expressive power, functions implemented by ReLU-sine-$2^x$ networks are (generalized) differentiable, enabling us to apply SGD to train.
Generative Learning With Euler Particle Transport
Dec 11, 2020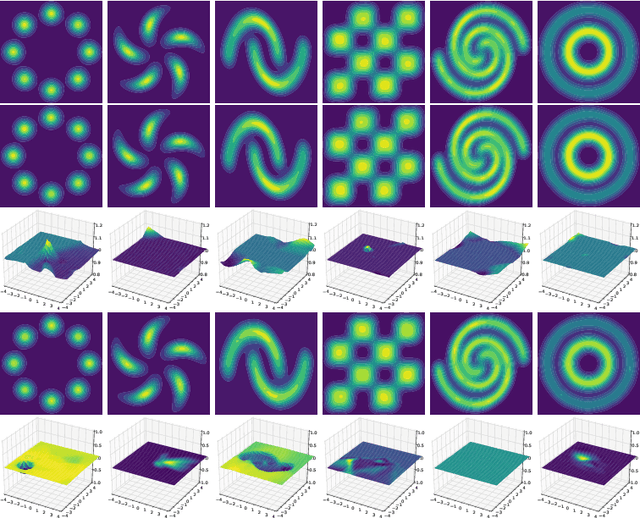
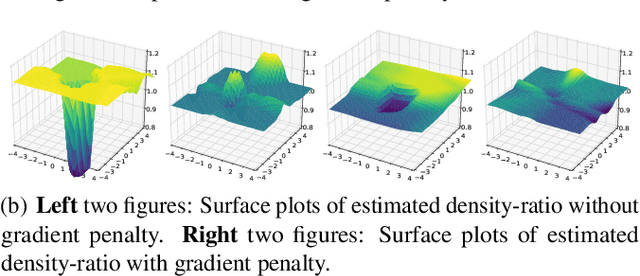
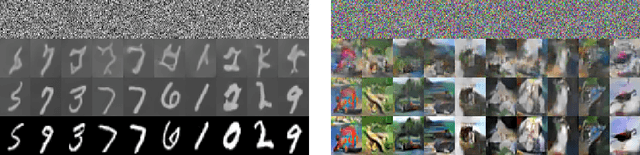

We propose an Euler particle transport (EPT) approach for generative learning. The proposed approach is motivated by the problem of finding an optimal transport map from a reference distribution to a target distribution characterized by the Monge-Ampere equation. Interpreting the infinitesimal linearization of the Monge-Ampere equation from the perspective of gradient flows in measure spaces leads to a stochastic McKean-Vlasov equation. We use the forward Euler method to solve this equation. The resulting forward Euler map pushes forward a reference distribution to the target. This map is the composition of a sequence of simple residual maps, which are computationally stable and easy to train. The key task in training is the estimation of the density ratios or differences that determine the residual maps. We estimate the density ratios (differences) based on the Bregman divergence with a gradient penalty using deep density-ratio (difference) fitting. We show that the proposed density-ratio (difference) estimators do not suffer from the "curse of dimensionality" if data is supported on a lower-dimensional manifold. Numerical experiments with multi-mode synthetic datasets and comparisons with the existing methods on real benchmark datasets support our theoretical results and demonstrate the effectiveness of the proposed method.
On Newton Screening
Feb 07, 2020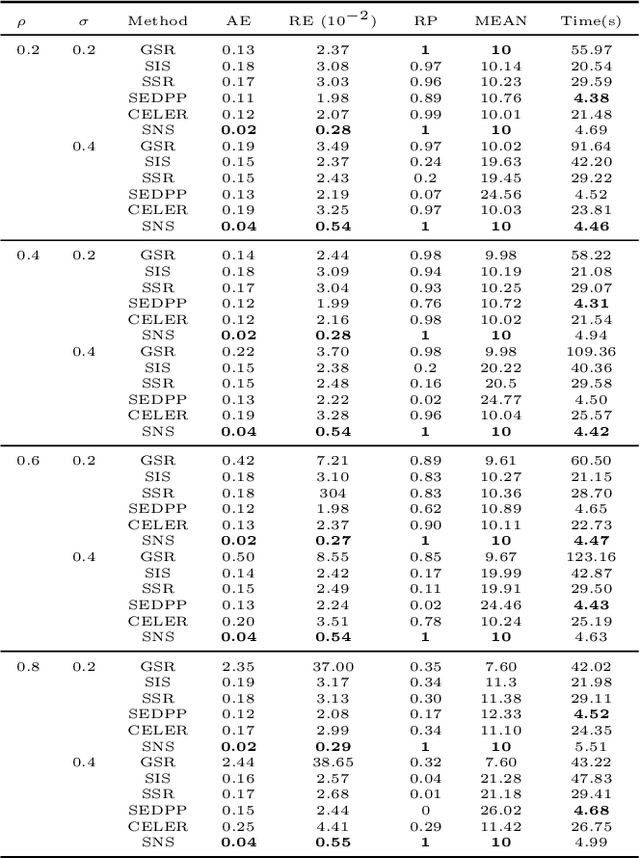
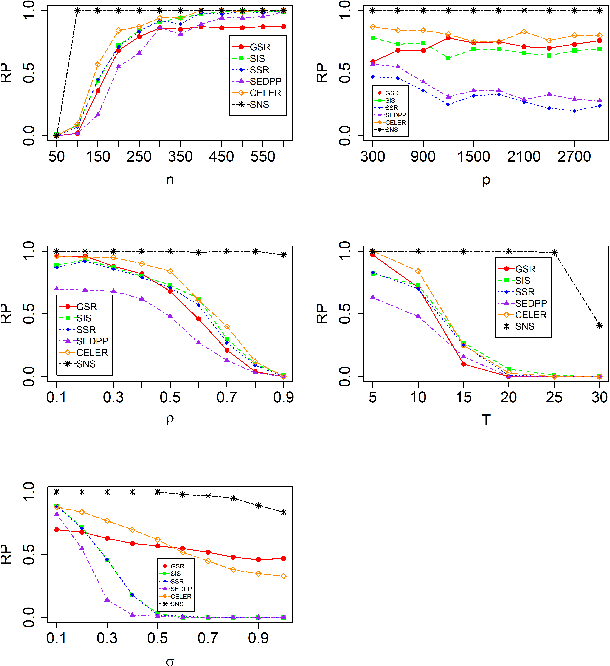
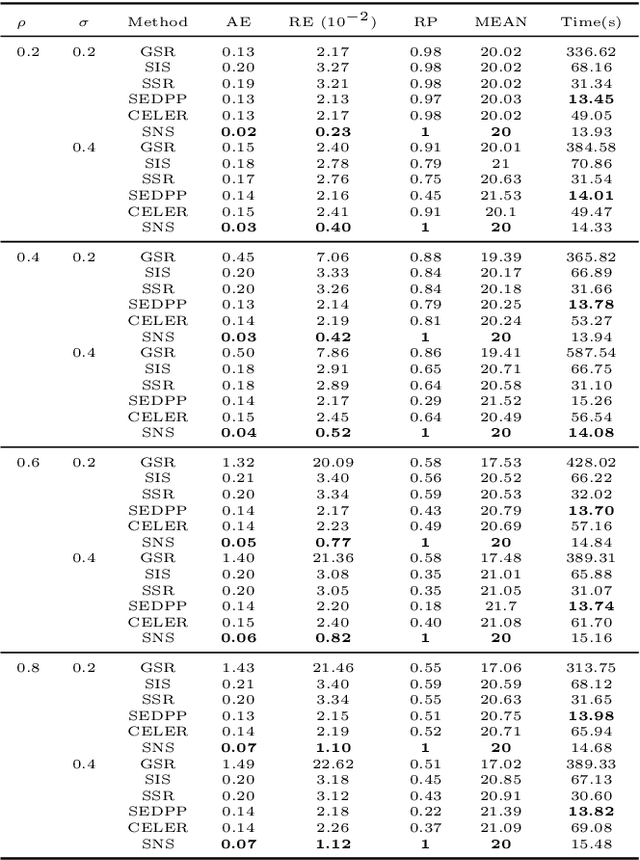
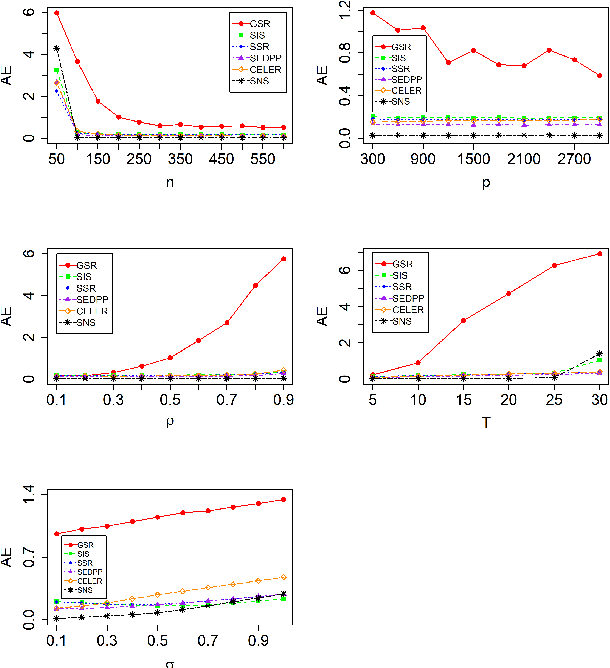
Screening and working set techniques are important approaches to reducing the size of an optimization problem. They have been widely used in accelerating first-order methods for solving large-scale sparse learning problems. In this paper, we develop a new screening method called Newton screening (NS) which is a generalized Newton method with a built-in screening mechanism. We derive an equivalent KKT system for the Lasso and utilize a generalized Newton method to solve the KKT equations. Based on this KKT system, a built-in working set with a relatively small size is first determined using the sum of primal and dual variables generated from the previous iteration, then the primal variable is updated by solving a least-squares problem on the working set and the dual variable updated based on a closed-form expression. Moreover, we consider a sequential version of Newton screening (SNS) with a warm-start strategy. We show that NS possesses an optimal convergence property in the sense that it achieves one-step local convergence. Under certain regularity conditions on the feature matrix, we show that SNS hits a solution with the same signs as the underlying true target and achieves a sharp estimation error bound with high probability. Simulation studies and real data analysis support our theoretical results and demonstrate that SNS is faster and more accurate than several state-of-the-art methods in our comparative studies.
A Support Detection and Root Finding Approach for Learning High-dimensional Generalized Linear Models
Jan 16, 2020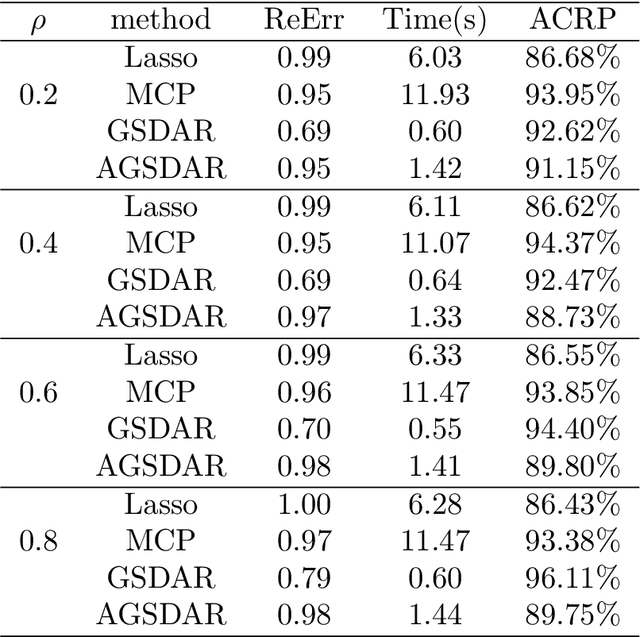
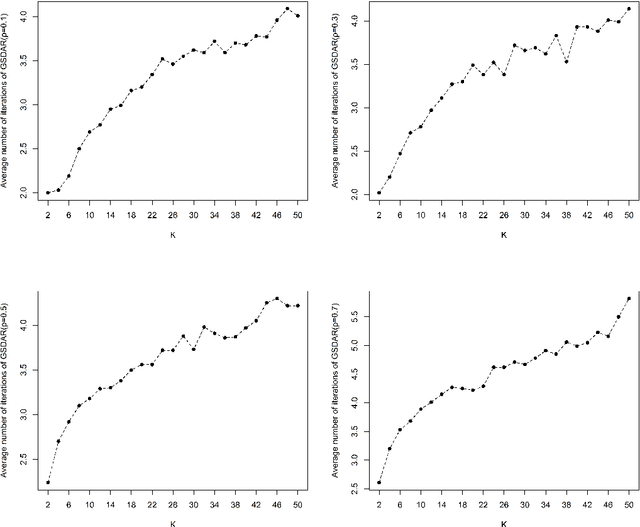
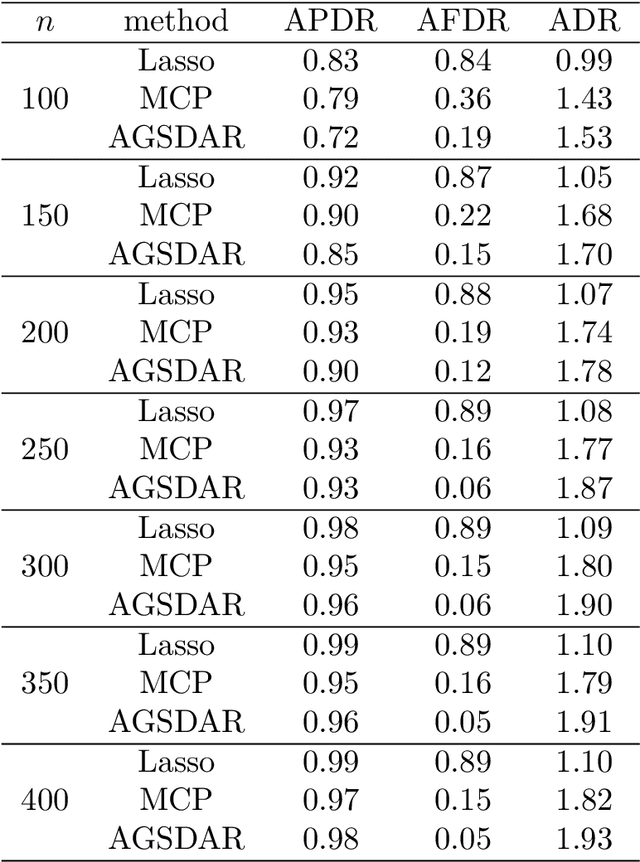
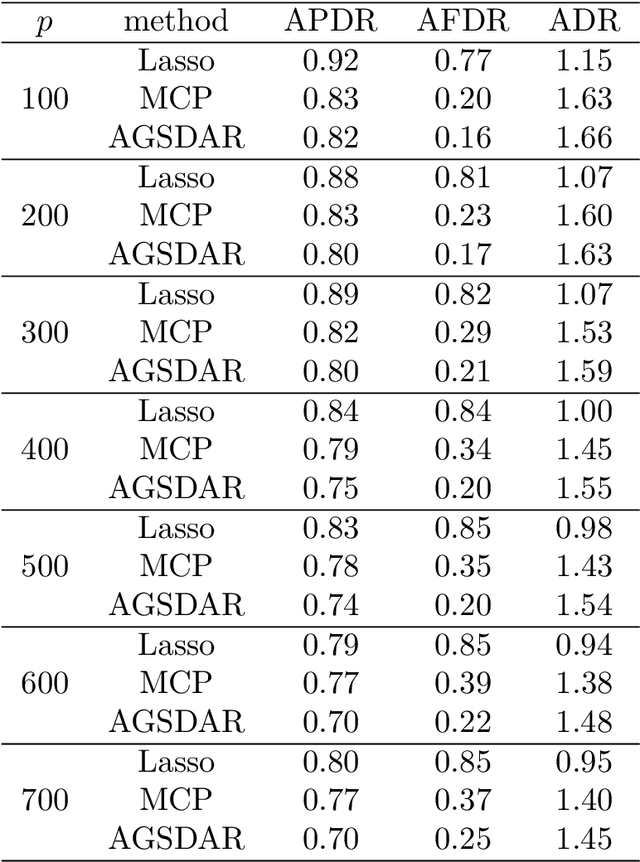
Feature selection is important for modeling high-dimensional data, where the number of variables can be much larger than the sample size. In this paper, we develop a support detection and root finding procedure to learn the high dimensional sparse generalized linear models and denote this method by GSDAR. Based on the KKT condition for $\ell_0$-penalized maximum likelihood estimations, GSDAR generates a sequence of estimators iteratively. Under some restricted invertibility conditions on the maximum likelihood function and sparsity assumption on the target coefficients, the errors of the proposed estimate decays exponentially to the optimal order. Moreover, the oracle estimator can be recovered if the target signal is stronger than the detectable level. We conduct simulations and real data analysis to illustrate the advantages of our proposed method over several existing methods, including Lasso and MCP.
A stochastic alternating minimizing method for sparse phase retrieval
Jun 14, 2019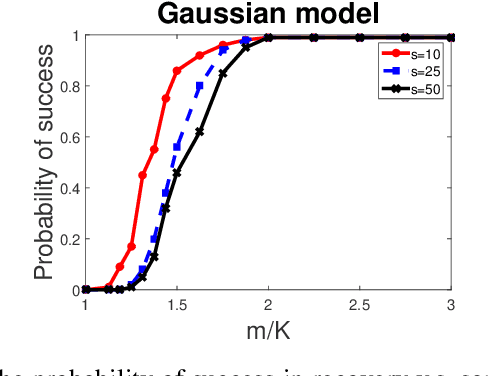
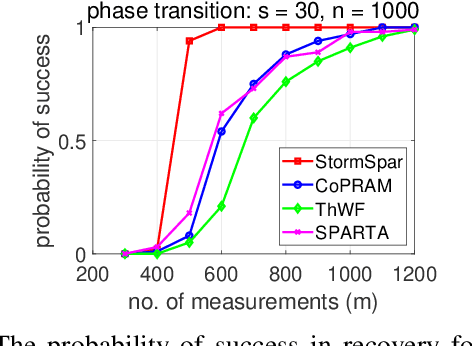
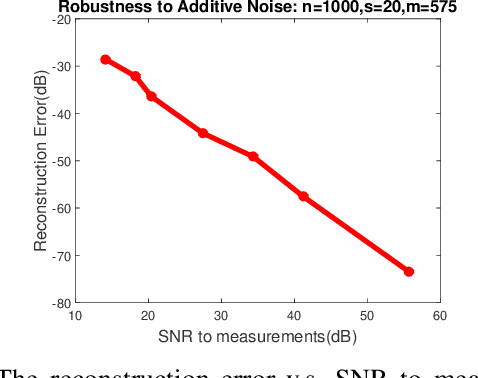
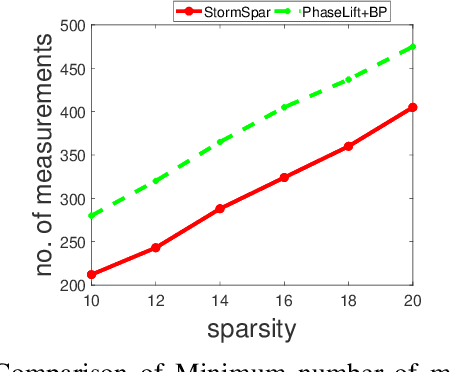
Sparse phase retrieval plays an important role in many fields of applied science and thus attracts lots of attention. In this paper, we propose a \underline{sto}chastic alte\underline{r}nating \underline{m}inimizing method for \underline{sp}arse ph\underline{a}se \underline{r}etrieval (\textit{StormSpar}) algorithm which {emprically} is able to recover $n$-dimensional $s$-sparse signals from only $O(s\,\mathrm{log}\, n)$ number of measurements without a desired initial value required by many existing methods. In \textit{StormSpar}, the hard-thresholding pursuit (HTP) algorithm is employed to solve the sparse constraint least square sub-problems. The main competitive feature of \textit{StormSpar} is that it converges globally requiring optimal order of number of samples with random initialization. Extensive numerical experiments are given to validate the proposed algorithm.
SNAP: A semismooth Newton algorithm for pathwise optimization with optimal local convergence rate and oracle properties
Oct 09, 2018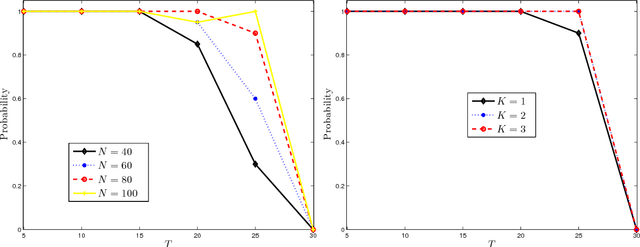
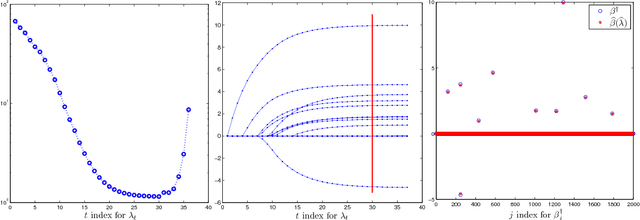
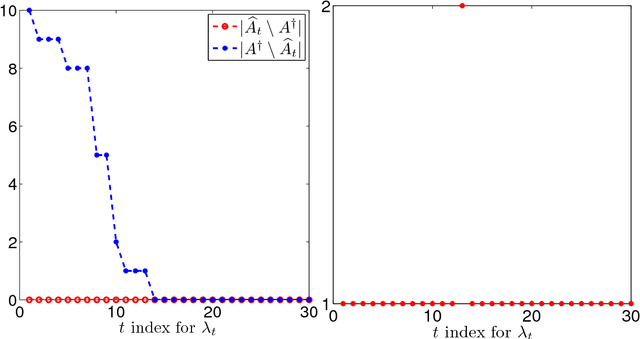
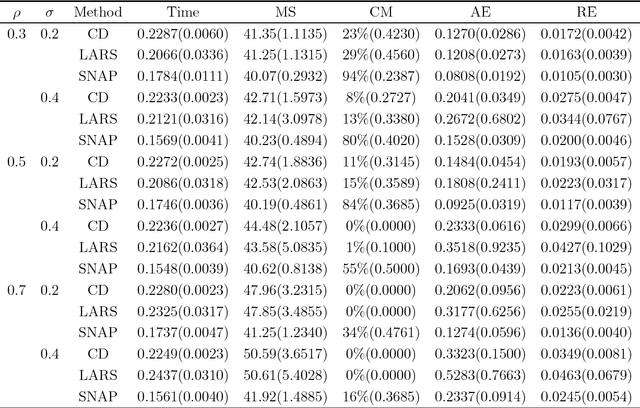
We propose a semismooth Newton algorithm for pathwise optimization (SNAP) for the LASSO and Enet in sparse, high-dimensional linear regression. SNAP is derived from a suitable formulation of the KKT conditions based on Newton derivatives. It solves the semismooth KKT equations efficiently by actively and continuously seeking the support of the regression coefficients along the solution path with warm start. At each knot in the path, SNAP converges locally superlinearly for the Enet criterion and achieves an optimal local convergence rate for the LASSO criterion, i.e., SNAP converges in one step at the cost of two matrix-vector multiplication per iteration. Under certain regularity conditions on the design matrix and the minimum magnitude of the nonzero elements of the target regression coefficients, we show that SNAP hits a solution with the same signs as the regression coefficients and achieves a sharp estimation error bound in finite steps with high probability. The computational complexity of SNAP is shown to be the same as that of LARS and coordinate descent algorithms per iteration. Simulation studies and real data analysis support our theoretical results and demonstrate that SNAP is faster and accurate than LARS and coordinate descent algorithms.
Oblique Stripe Removal in Remote Sensing Images via Oriented Variation
Sep 06, 2018
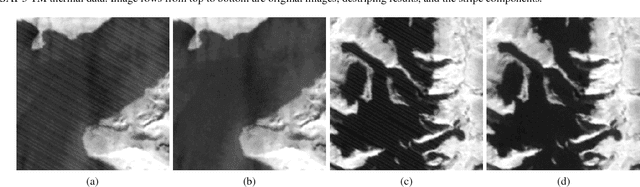


Destriping is a classical problem in remote sensing image processing. Although considerable effort has been made to remove stripes, few of the existing methods can eliminate stripe noise with arbitrary orientations. This situation makes the removal of oblique stripes in the higher-level remote sensing products become an unfinished and urgent issue. To overcome the challenging problem, we propose a novel destriping model which is self-adjusted to different orientations of stripe noise. First of all, the oriented variation model is designed to accomplish the stripe orientation approximation. In this model, the stripe direction is automatically estimated and then imbedded into the constraint term to depict the along-stripe smoothness of the stripe component. Mainly based on the oriented variation model, a whole destriping framework is proposed by jointly employing an L1-norm constraint and a TV regularization to separately capture the global distribution property of stripe component and the piecewise smoothness of the clean image. The qualitative and quantitative experimental results of both orientation and destriping aspects confirm the effectiveness and stability of the proposed method.
A Unified Primal Dual Active Set Algorithm for Nonconvex Sparse Recovery
Jan 06, 2018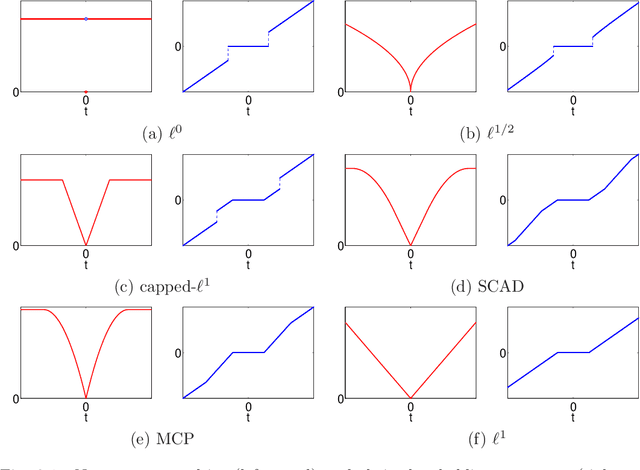


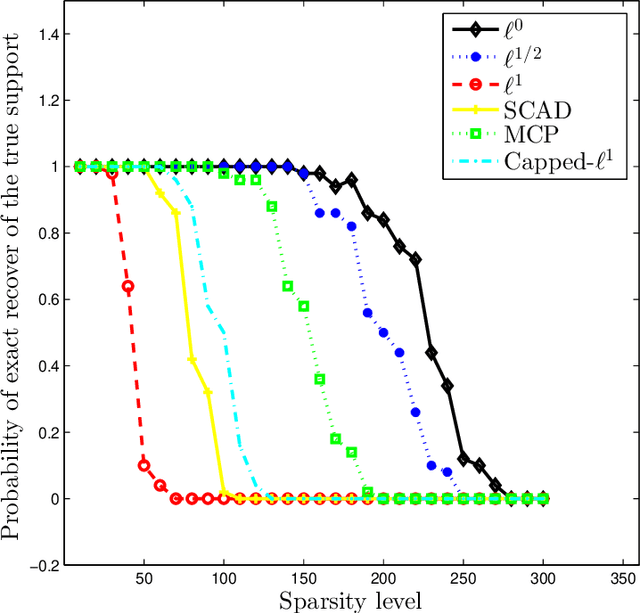
In this paper, we consider the problem of recovering a sparse signal based on penalized least squares. We develop an algorithm of primal-dual active set type for a class of nonconvex sparsity-promoting penalties, which includes $\ell^0$, bridge, smoothly clipped absolute deviation, capped $\ell^1$ and minimax concavity penalty. First we establish the existence of a global minimizer for the class of optimization problems. Then we derive a novel necessary optimality condition for the global minimizer using the associated thresholding operator. The solutions to the optimality system are coordinate-wise minimizers, and under minor conditions, they are also local minimizers. Upon introducing the dual variable, the active set can be determined from the primal and dual variables. This relation lends itself to an iterative algorithm of active set type which at each step involves updating the primal variable only on the active set and then updating the dual variable explicitly. When combined with a continuation strategy on the regularization parameter, the primal dual active set method converges globally to the underlying regression target under some regularity conditions. Extensive numerical experiments demonstrate its superior performance in efficiency and accuracy compared with the existing methods.
A Primal Dual Active Set with Continuation Algorithm for the \ell^0-Regularized Optimization Problem
Mar 03, 2014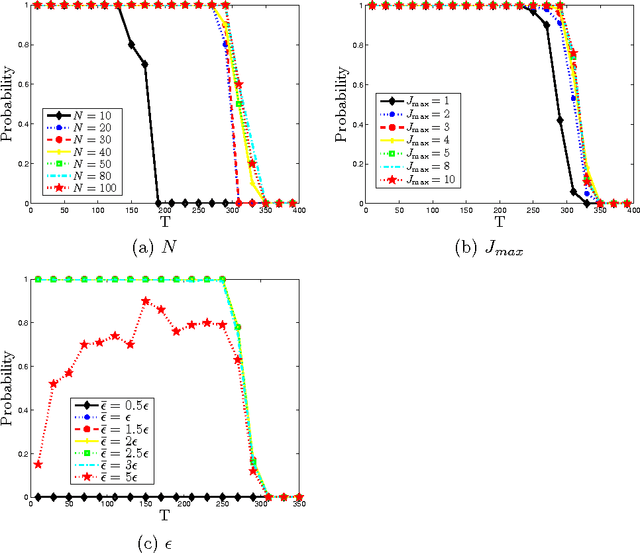
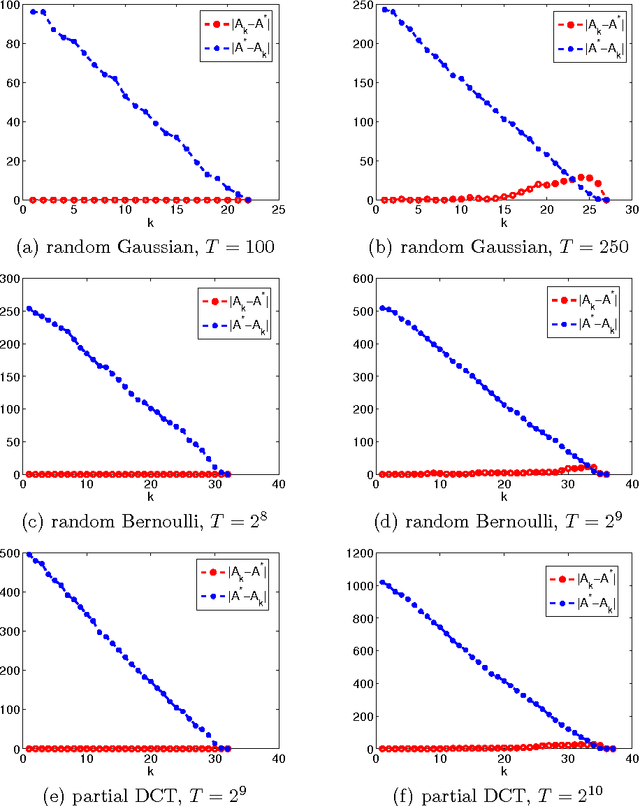
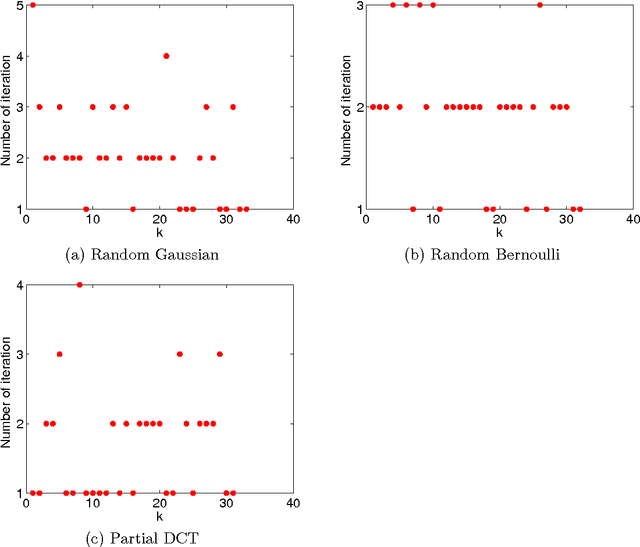
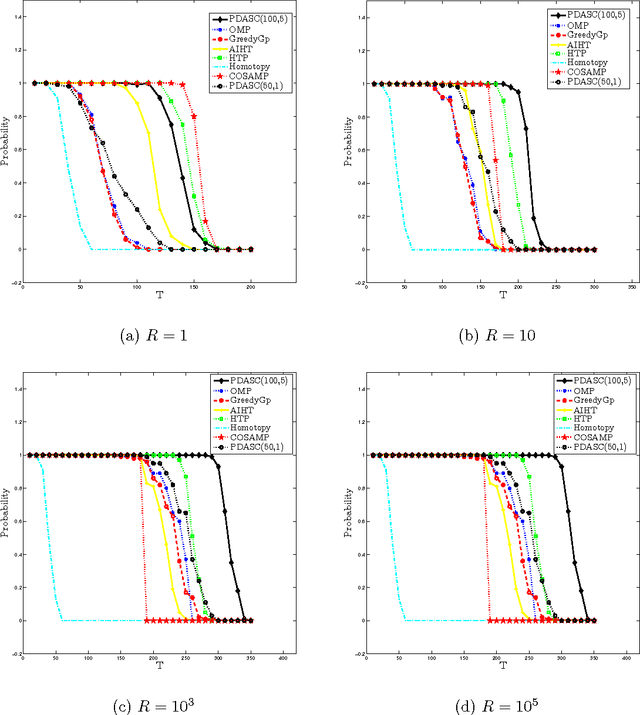
We develop a primal dual active set with continuation algorithm for solving the \ell^0-regularized least-squares problem that frequently arises in compressed sensing. The algorithm couples the the primal dual active set method with a continuation strategy on the regularization parameter. At each inner iteration, it first identifies the active set from both primal and dual variables, and then updates the primal variable by solving a (typically small) least-squares problem defined on the active set, from which the dual variable can be updated explicitly. Under certain conditions on the sensing matrix, i.e., mutual incoherence property or restricted isometry property, and the noise level, the finite step global convergence of the algorithm is established. Extensive numerical examples are presented to illustrate the efficiency and accuracy of the algorithm and the convergence analysis.