 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Topological Improvement of the Overall Performance of Sparse Evolutionary Training: Motif-Based Structural Optimization of Sparse MLPs Project
Paper and Code
Jun 10, 2025

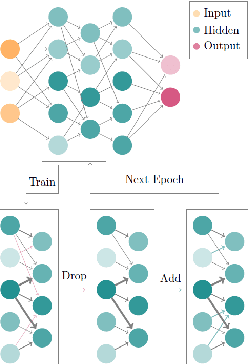
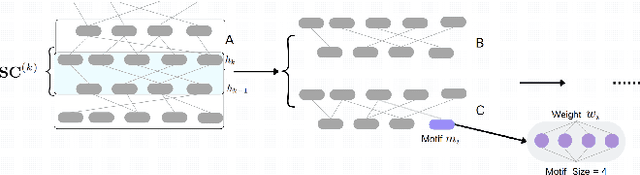
Deep Neural Networks (DNNs) have been proven to be exceptionally effective and have been applied across diverse domains within deep learning. However, as DNN models increase in complexity, the demand for reduced computational costs and memory overheads has become increasingly urgent. Sparsity has emerged as a leading approach in this area. The robustness of sparse Multi-layer Perceptrons (MLPs) for supervised feature selection, along with the application of Sparse Evolutionary Training (SET), illustrates the feasibility of reducing computational costs without compromising accuracy. Moreover, it is believed that the SET algorithm can still be improved through a structural optimization method called motif-based optimization, with potential efficiency gains exceeding 40% and a performance decline of under 4%. This research investigates whether the structural optimization of Sparse Evolutionary Training applied to Multi-layer Perceptrons (SET-MLP) can enhance performance and to what extent this improvement can be achieved.