 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTCoP: Accelerating Large Vision-Language Models via Visual and Textual Semantic Collaborative Pruning
Jan 25, 2026Large Vision-Language Models (LVLMs) incur high computational costs due to significant redundancy in their visual tokens. To effectively reduce this cost, researchers have proposed various visual token pruning methods. However, existing methods are generally limited, either losing critical visual information prematurely due to pruning in the vision encoder, or leading to information redundancy among the selected tokens due to pruning in the Large Language Models (LLMs). To address these challenges, we propose a Visual and Textual Semantic Collaborative Pruning framework (ViTCoP) that combines redundancy filtering in the vision encoder with step-wise co-pruning within the LLM based on its hierarchical characteristics, to efficiently preserve critical and informationally diverse visual tokens. Meanwhile, to ensure compatibility with acceleration techniques like FlashAttention, we introduce the L2 norm of K-vectors as the token saliency metric in the LLM. Extensive experiments on various Large Vision-Language Models demonstrate that ViTCoP not only achieves state-of-the-art performance surpassing existing methods on both image and video understanding tasks, but also significantly reduces model inference latency and GPU memory consumption. Notably, its performance advantage over other methods becomes even more pronounced under extreme pruning rates.
EDENet: Echo Direction Encoding Network for Place Recognition Based on Ground Penetrating Radar
Feb 28, 2025



Ground penetrating radar (GPR) based localization has gained significant recognition in robotics due to its ability to detect stable subsurface features, offering advantages in environments where traditional sensors like cameras and LiDAR may struggle. However, existing methods are primarily focused on small-scale place recognition (PR), leaving the challenges of PR in large-scale maps unaddressed. These challenges include the inherent sparsity of underground features and the variability in underground dielectric constants, which complicate robust localization. In this work, we investigate the geometric relationship between GPR echo sequences and underground scenes, leveraging the robustness of directional features to inform our network design. We introduce learnable Gabor filters for the precise extraction of directional responses, coupled with a direction-aware attention mechanism for effective geometric encoding. To further enhance performance, we incorporate a shift-invariant unit and a multi-scale aggregation strategy to better accommodate variations in di-electric constants. Experiments conducted on public datasets demonstrate that our proposed EDENet not only surpasses existing solutions in terms of PR performance but also offers advantages in model size and computational efficiency.
Multilevel Image Thresholding Using a Fully Informed Cuckoo Search Algorithm
May 31, 2020
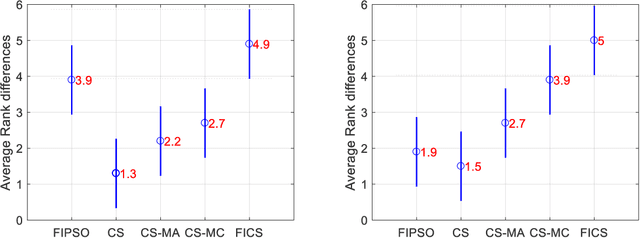
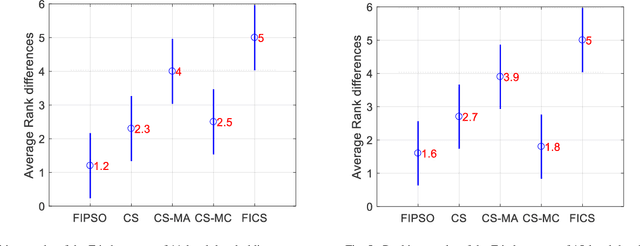
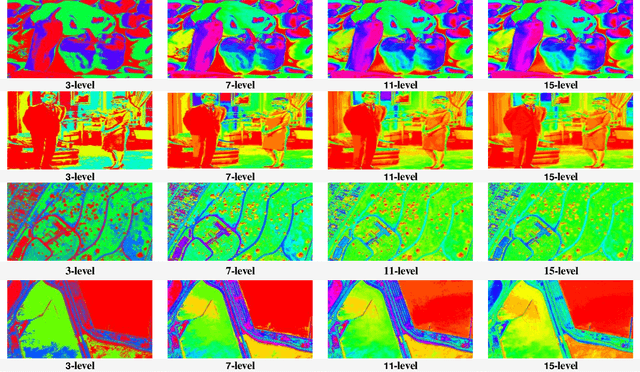
Though effective in the segmentation, conventional multilevel thresholding methods are computationally expensive as exhaustive search are used for optimal thresholds to optimize the objective functions. To overcome this problem, population-based metaheuristic algorithms are widely used to improve the searching capacity. In this paper, we improve a popular metaheuristic called cuckoo search using a ring topology based fully informed strategy. In this strategy, each individual in the population learns from its neighborhoods to improve the cooperation of the population and the learning efficiency. Best solution or best fitness value can be obtained from the initial random threshold values, whose quality is evaluated by the correlation function. Experimental results have been examined on various numbers of thresholds. The results demonstrate that the proposed algorithm is more accurate and efficient than other four popular methods.
Novel Co-variant Feature Point Matching Based on Gaussian Mixture Model
Oct 26, 2019
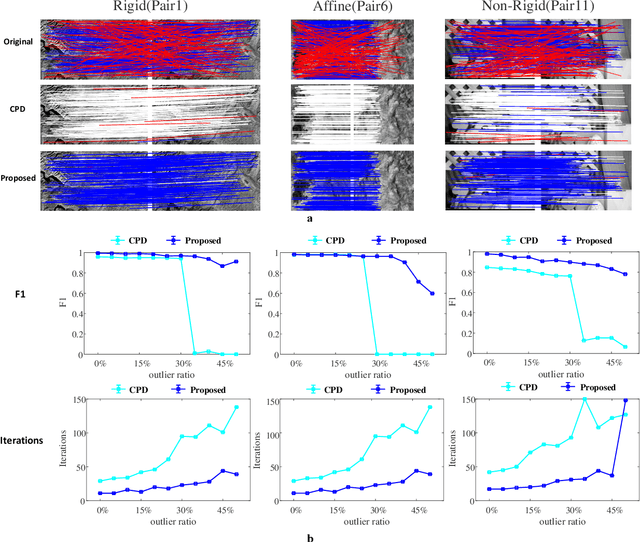
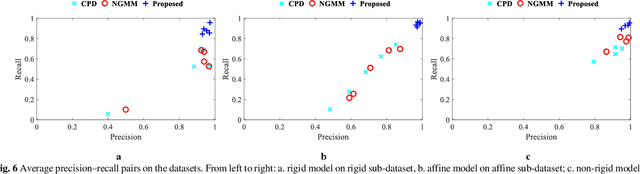
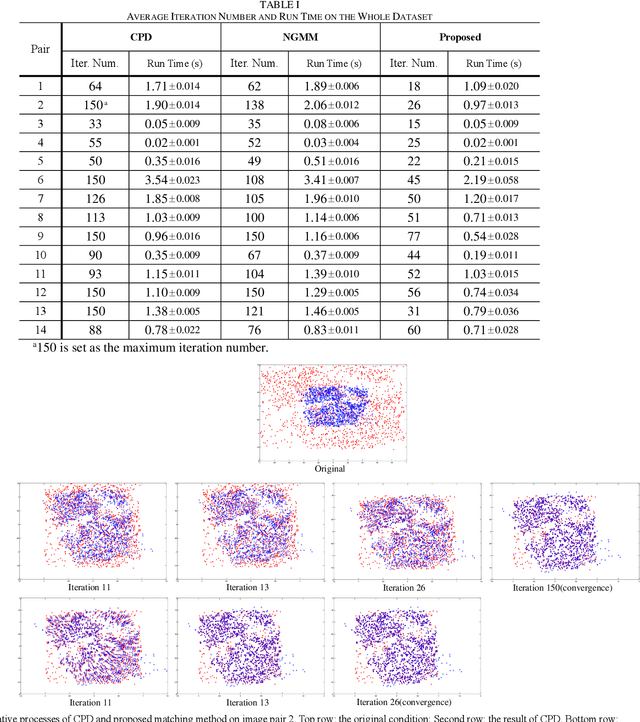
The feature frame is a key idea of feature matching problem between two images. However, most of the traditional matching methods only simply employ the spatial location information (the coordinates), which ignores the shape and orientation information of the local feature. Such additional information can be obtained along with coordinates using general co-variant detectors such as DOG, Hessian, Harris-Affine and MSER. In this paper, we develop a novel method considering all the feature center position coordinates, the local feature shape and orientation information based on Gaussian Mixture Model for co-variant feature matching. We proposed three sub-versions in our method for solving the matching problem in different conditions: rigid, affine and non-rigid, respectively, which all optimized by expectation maximization algorithm. Due to the effective utilization of the additional shape and orientation information, the proposed model can significantly improve the performance in terms of convergence speed and recall. Besides, it is more robust to the outliers.