 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Trustworthy Evaluation of Sustainability Rating Methodologies: A Human-AI Collaborative Framework for Benchmark Dataset Construction
Feb 19, 2026Sustainability or ESG rating agencies use company disclosures and external data to produce scores or ratings that assess the environmental, social, and governance performance of a company. However, sustainability ratings across agencies for a single company vary widely, limiting their comparability, credibility, and relevance to decision-making. To harmonize the rating results, we propose adopting a universal human-AI collaboration framework to generate trustworthy benchmark datasets for evaluating sustainability rating methodologies. The framework comprises two complementary parts: STRIDE (Sustainability Trust Rating & Integrity Data Equation) provides principled criteria and a scoring system that guide the construction of firm-level benchmark datasets using large language models (LLMs), and SR-Delta, a discrepancy-analysis procedural framework that surfaces insights for potential adjustments. The framework enables scalable and comparable assessment of sustainability rating methodologies. We call on the broader AI community to adopt AI-powered approaches to strengthen and advance sustainability rating methodologies that support and enforce urgent sustainability agendas.
D2D-Enabled Data Sharing for Distributed Machine Learning at Wireless Network Edge
Jan 28, 2020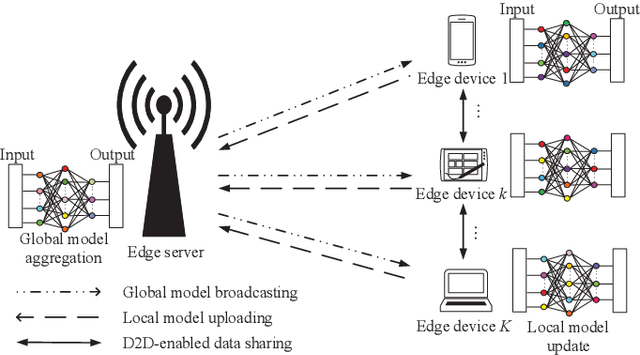
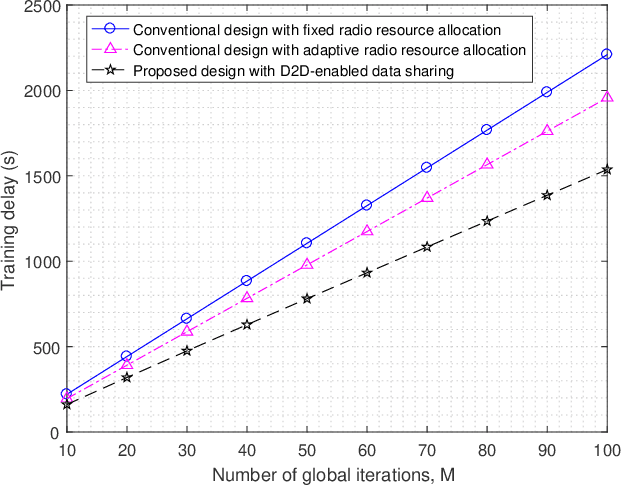
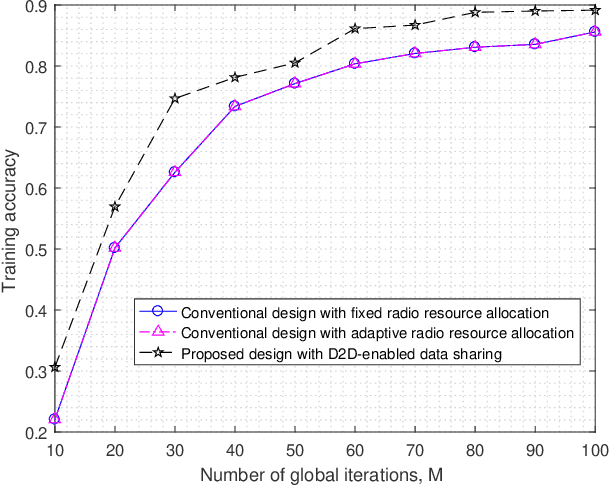
Mobile edge learning is an emerging technique that enables distributed edge devices to collaborate in training shared machine learning models by exploiting their local data samples and communication and computation resources. To deal with the straggler dilemma issue faced in this technique, this paper proposes a new device to device enabled data sharing approach, in which different edge devices share their data samples among each other over communication links, in order to properly adjust their computation loads for increasing the training speed. Under this setup, we optimize the radio resource allocation for both data sharing and distributed training, with the objective of minimizing the total training delay under fixed numbers of local and global iterations. Numerical results show that the proposed data sharing design significantly reduces the training delay, and also enhances the training accuracy when the data samples are non independent and identically distributed among edge devices.