 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptAL: Sample-Aware Dynamic Soft Prompts for Few-Shot Active Learning
Jul 22, 2025Active learning (AL) aims to optimize model training and reduce annotation costs by selecting the most informative samples for labeling. Typically, AL methods rely on the empirical distribution of labeled data to define the decision boundary and perform uncertainty or diversity estimation, subsequently identifying potential high-quality samples. In few-shot scenarios, the empirical distribution often diverges significantly from the target distribution, causing the decision boundary to shift away from its optimal position. However, existing methods overlook the role of unlabeled samples in enhancing the empirical distribution to better align with the target distribution, resulting in a suboptimal decision boundary and the selection of samples that inadequately represent the target distribution. To address this, we propose a hybrid AL framework, termed \textbf{PromptAL} (Sample-Aware Dynamic Soft \textbf{Prompts} for Few-Shot \textbf{A}ctive \textbf{L}earning). This framework accounts for the contribution of each unlabeled data point in aligning the current empirical distribution with the target distribution, thereby optimizing the decision boundary. Specifically, PromptAL first leverages unlabeled data to construct sample-aware dynamic soft prompts that adjust the model's predictive distribution and decision boundary. Subsequently, based on the adjusted decision boundary, it integrates uncertainty estimation with both global and local diversity to select high-quality samples that more accurately represent the target distribution. Experimental results on six in-domain and three out-of-domain datasets show that PromptAL achieves superior performance over nine baselines. Our codebase is openly accessible.
Boosting Generative Zero-Shot Learning by Synthesizing Diverse Features with Attribute Augmentation
Dec 23, 2021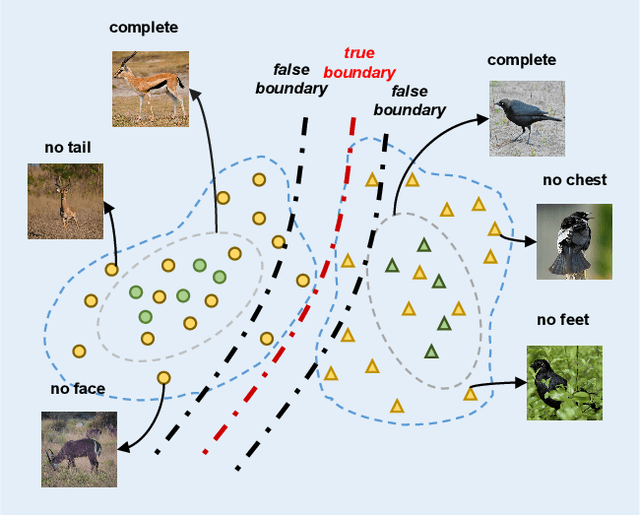
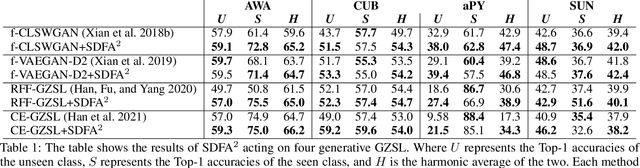
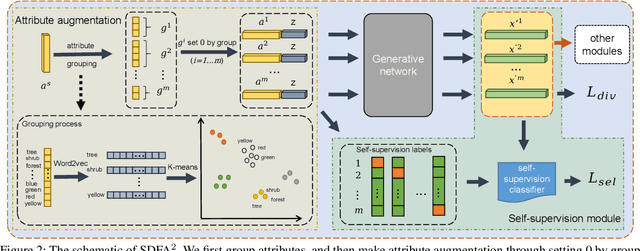
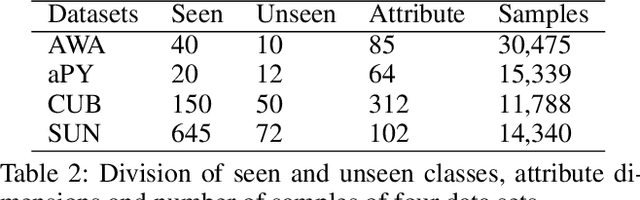
The recent advance in deep generative models outlines a promising perspective in the realm of Zero-Shot Learning (ZSL). Most generative ZSL methods use category semantic attributes plus a Gaussian noise to generate visual features. After generating unseen samples, this family of approaches effectively transforms the ZSL problem into a supervised classification scheme. However, the existing models use a single semantic attribute, which contains the complete attribute information of the category. The generated data also carry the complete attribute information, but in reality, visual samples usually have limited attributes. Therefore, the generated data from attribute could have incomplete semantics. Based on this fact, we propose a novel framework to boost ZSL by synthesizing diverse features. This method uses augmented semantic attributes to train the generative model, so as to simulate the real distribution of visual features. We evaluate the proposed model on four benchmark datasets, observing significant performance improvement against the state-of-the-art.